Clear Sky Science · nl
Tijdelijk consistente verbetering van gezichtsvideo’s bij weinig licht via video-naar-video conditionele diffusie
Gezichten uit de schaduw halen
Wie ooit geprobeerd heeft ’s nachts iemand te filmen, weet dat het resultaat vaak een modderige, korrelige puinhoop is: gezichten verdwijnen in de schaduwen, kleuren kloppen niet en details flikkeren van frame naar frame. Dit artikel introduceert DL-Diff, een nieuwe kunstmatige-intelligentiemethode die zulke donkere, lawaaierige gezichtsvideo’s omzet in heldere, natuurlijk ogende clips die soepel afspelen, zonder de storende shimmer en flikkering die eerdere technieken vaak vertonen. Het werk is relevant voor alledaagse fotografie, bewakingscamera’s voor thuis en zelfs voor rijhulpsystemen die mensen moeten herkennen bij slechte lichtomstandigheden.
Waarom nachtopnames zo moeilijk zijn
Gezichtsvideo’s bij weinig licht vormen een dubbele uitdaging. Enerzijds is elk frame beschadigd door zware ruis, kleurverschuivingen en verloren details omdat zeer weinig fotonen de camerasensor bereiken. Anderzijds is een video niet zomaar een stapel plaatjes: ons visuele systeem is erg gevoelig voor sprongen in helderheid of vorm van het ene naar het andere frame. Veel bestaande methoden behandelen elk frame afzonderlijk of vertrouwen op grove bewegingsschattingen tussen frames. Dat helpt enigszins, maar laat vaak nog flikkering of vervormde gezichten achter, vooral wanneer de scène extreem donker is en de beweging complex.
Een nieuwe pijplijn van donker naar licht
DL-Diff pakt het probleem aan door verbetering bij weinig licht te zien als een volledige video-naar-video transformatie in plaats van een frame-voor-frame bijwerking. Het bouwt voort op krachtige “diffusie”generators die oorspronkelijk getraind zijn om afbeeldingen en korte video’s uit tekstprompts te creëren. Deze generators werken door te beginnen met willekeurige ruis en die geleidelijk te verfijnen tot een schoon beeld. DL-Diff hergebruikt zo’n model zodat, in plaats van een tekstbeschrijving te volgen, de generator wordt gestuurd door de daadwerkelijke donkere invoervideo. Doordat het systeem in een compacte interne representatie werkt in plaats van direct op pixels, kan het ruis wegsnijden en ontbrekende details hallucineren terwijl het toch de algemene inhoud van het originele beeldmateriaal respecteert.
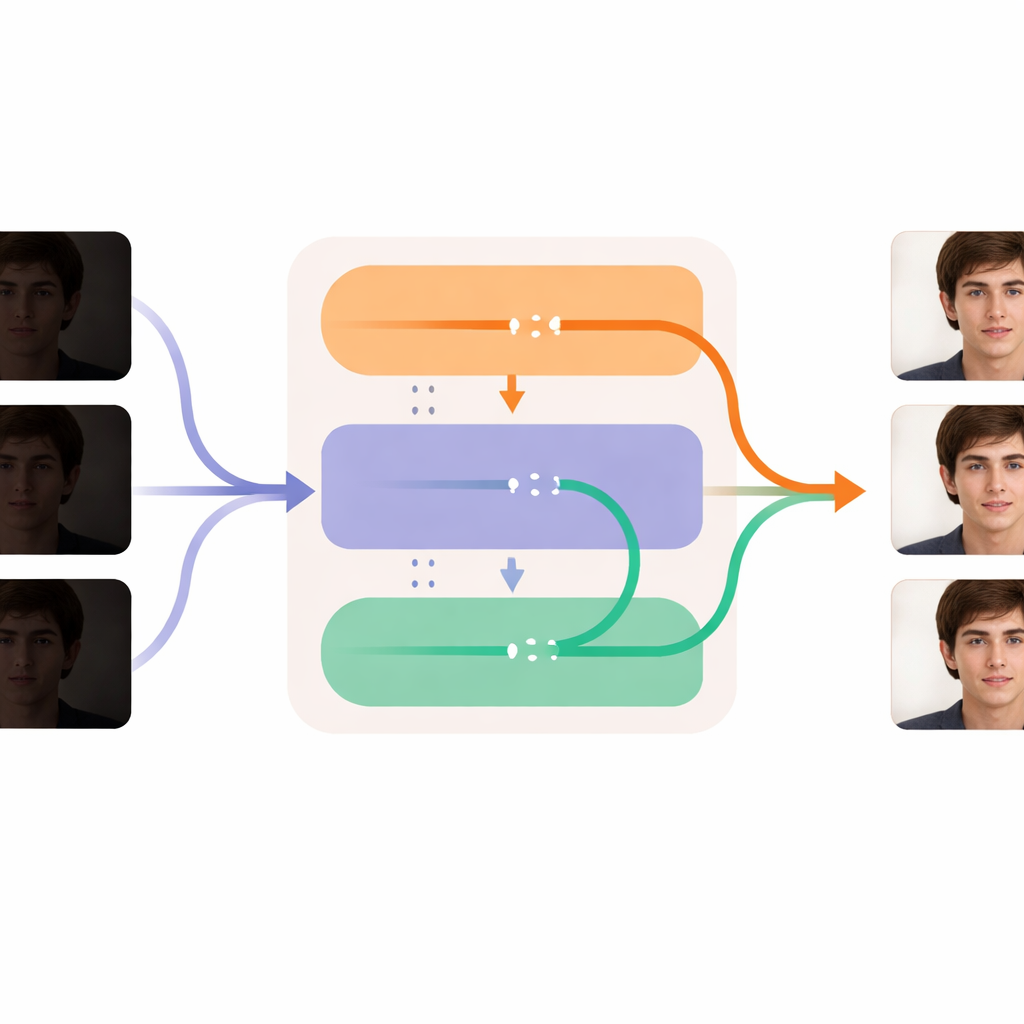
Elk frame verscherpen en tegelijk de tijd vloeiend houden
De kern van DL-Diff is opgesplitst in twee samenwerkende modules die spiegelbeeldig zijn aan hoe wij video ervaren. Het “restauratie”-gedeelte richt zich op ruimte: het bekijkt elk frame en voegt extra detail, textuur en realistischere kleuren toe in de interne lagen van de generator, ter compensatie van wat in het donker verloren ging. Deze module wordt eerst getraind op individuele afbeeldingsparen, zodat hij leert hoe een donker gezicht eruit zou moeten zien als het goed verlicht is. Het “tijdelijke” gedeelte richt zich op tijd: het vormt het model zodanig dat het, in sleutelstadia van de verwerking, informatie over meerdere frames kan vergelijken en ze zachtjes op één lijn kan trekken. Dit helpt dat gezichtsuitdrukkingen, hoofdbewegingen en lichtveranderingen vloeiend evolueren van frame naar frame in plaats van te schokken of te poppen. Samen stellen deze modules het systeem in staat elk frame op te helderen en te reinigen terwijl de identiteit en beweging van de persoon stabiel blijven over de hele video.
Het model in fasen leren
Om optimaal gebruik te maken van de grote voorgetrainde generator zonder te verstoren wat deze al geleerd heeft, trainen de auteurs DL-Diff in drie stappen. Eerst leren ze de restauratiemodule om enkele donkere afbeeldingen te herstellen terwijl de rest van het netwerk bevroren blijft. Vervolgens trainen ze de tijdelijke module op schone, normaal verlichte video’s zodat deze kan leren hoe natuurlijke beweging zich gedraagt zonder verward te raken door artefacten van weinig licht. Ten slotte finetunen ze beide modules samen op gekoppelde donkere en heldere video’s. Dit curriculumachtige proces verkleint de kloof tussen stilstaande beelden en bewegend beeldmateriaal en helpt het systeem stabiel te blijven, zelfs wanneer de invoer extreem ruisig of bijna zwart is.

Scherpere, natuurlijker ogende gezichten in het donker
Op twee openbare datasets met echte video’s bij weinig licht produceert DL-Diff duidelijkere gezichten met natuurlijkere kleuren dan meerdere toonaangevende methoden, en dat met minder zichtbare flikkering in de tijd. Mens menselijke georiënteerde maatstaven van visuele kwaliteit DL-Diff bevoordelen, scoren sommige oudere technieken iets beter op strikte pixel-voor-pixel nauwkeurigheid. Die afweging weerspiegelt een ontwerpkeuze: de nieuwe methode legt de nadruk op wat voor een kijker goed oogt in plaats van precies elke pixel te matchen. Het belangrijkste nadeel is snelheid — omdat diffusiemodellen elk frame via vele stappen verfijnen, is verwerking trager dan bij eenvoudigere benaderingen — maar de auteurs merken op dat nieuwere, snellere varianten dit in de toekomst kunnen verlichten. Al met al laat DL-Diff zien dat moderne generatieve modellen, mits zorgvuldig aangepast, bijna onbruikbare donkere gezichtsvideo’s kunnen omzetten in heldere, stabiele opnames die geschikt zijn voor bewaking, fotografie en andere toepassingen in de echte wereld.
Bronvermelding: Ding, X., He, K., Sun, H. et al. Temporally consistent low-light face video enhancement via video-to-video conditional diffusion. Sci Rep 16, 14097 (2026). https://doi.org/10.1038/s41598-026-44219-8
Trefwoorden: video bij weinig licht, verbetering van gezichten, diffusiemodellen, videoherstel, tijdelijke consistentie