Clear Sky Science · tr
Zamana bağlı tutarlı düşük ışıklı yüz video iyileştirmesi: video'dan video'ya koşullu difüzyon
Yüzleri Karanlıktan Çıkarmak
Geceleri bir kişiyi filme almaya çalışan herkes sonucun bulanık, grenli bir karışım olabileceğini bilir: yüzler gölgelere karışır, renkler yanlış görünür ve ayrıntılar kareden kareye titreşir. Bu makale, DL-Diff adını taşıyan yeni bir yapay zeka yöntemini tanıtıyor; bu yöntem karanlık, gürültülü yüz videolarını parlak, doğal görünen ve rahatsız edici parıltı ile titremeden akıcı oynayan kliplere dönüştürüyor. Çalışma günlük fotoğrafçılık, ev güvenlik kameraları ve zayıf ışıkta insanları tanıması gereken sürücü destek sistemleri için önem taşıyor.
Neden Gece Videoları Bu Kadar Zor?
Düşük ışıklı yüz videoları çift yönlü bir zorluk sunar. Bir yandan, her kare çok az foton kameraya ulaştığı için yoğun gürültü, renk kaymaları ve kaybolmuş ayrıntılarla bozulur. Öte yandan, bir video yalnızca üst üste koyulmuş görüntüler değil: gözlerimiz bir kareden diğerine parlaklık veya şekil atlamalarına karşı çok hassastır. Mevcut birçok yöntem her kareyi ayrı ayrı işler veya kareler arasındaki kaba hareket tahminlerine dayanır. Bu bir parça yardımcı olabilir, ancak genellikle özellikle sahne son derece karanlık ve hareket karmaşıksa, titreme veya yamulmuş yüzler bırakır.
Karanlıktan Aydınlığa Yeni Bir İşlem Hattı
DL-Diff sorunu kare kare rötuş yerine tam bir video'dan video'ya dönüşüm olarak ele alır. Metin istemlerinden görüntü ve kısa videolar üretmek üzere eğitilmiş güçlü "difüzyon" üreticilerinin üzerine inşa edilir. Bu üreticiler rastgele gürültüyle başlayıp bunu kademeli olarak temiz bir resme dönüştürerek çalışır. DL-Diff, üreticiyi bir metin betimlemesini takip etmek yerine gerçek karanlık giriş videosuyla yönlendirerek böyle bir modeli yeniden amaçlar. Piksel düzeyinde doğrudan çalışmak yerine kompakt iç temsillerde işlem yaparak sistem gürültüyü ortadan kaldırabilir ve eksik ayrıntıları hayal ederken orijinal görüntülerin genel içeriğine saygı gösterir.
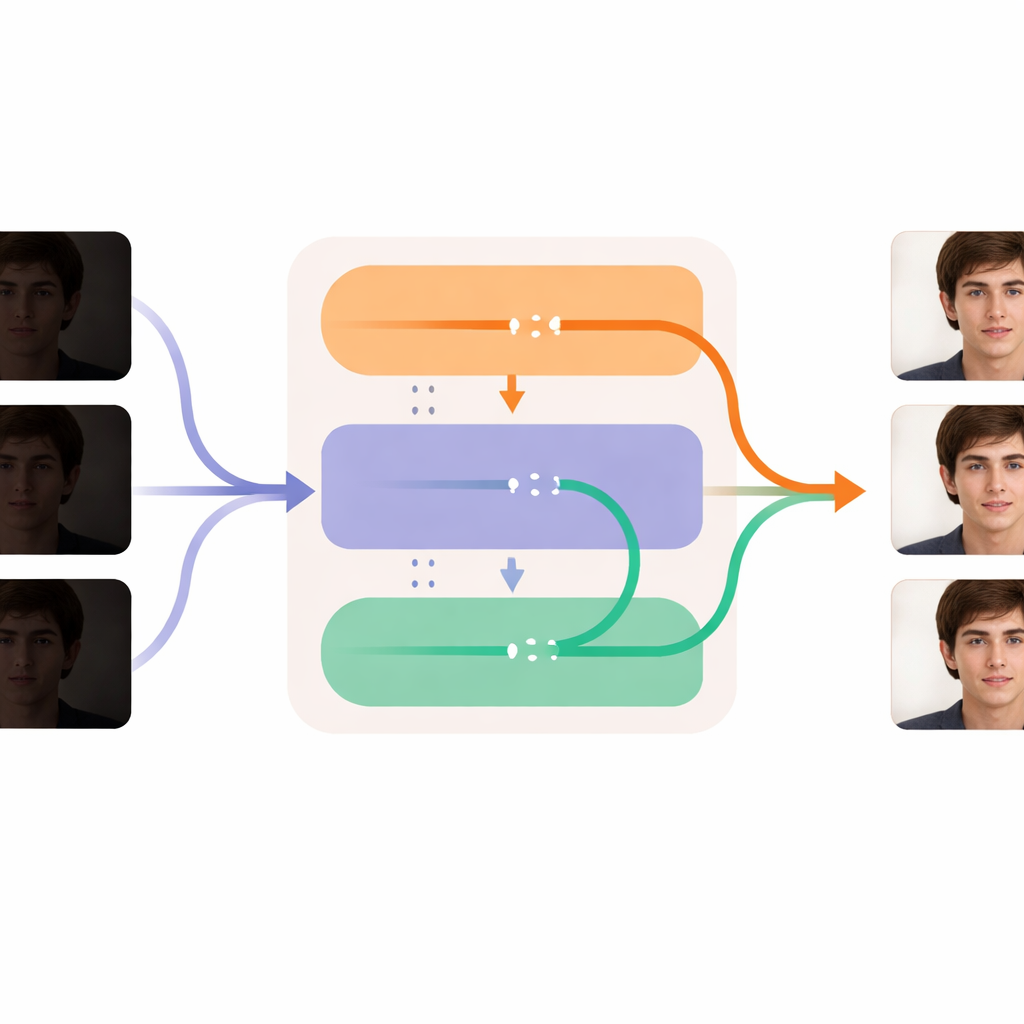
Her Karekteri Keskinleştirirken Zamanı Düz Tutmak
DL-Diff’in özü, videoyu nasıl deneyimlediğimizi yansıtan iki işbirlikçi modüle ayrılır. "Restorasyon" kısmı mekâna odaklanır: her kareye bakar ve üreticinin iç katmanlarına ekstra ayrıntı, doku ve daha gerçekçi renkler enjekte ederek karanlıkta kaybolanı telafi eder. Bu modül ilk olarak bireysel görüntü çiftleri üzerinde eğitilir ve loş bir yüzün doğru aydınlatıldığında nasıl görünmesi gerektiğini öğrenir. "Zamansal" kısım ise zamana odaklanır: işlem sürecinin kilit aşamalarında modelin kareler arası bilgileri karşılaştırmasını ve nazikçe hizalamasını sağlayacak şekilde modeli yeniden şekillendirir. Bu, ifadelerin, baş hareketlerinin ve aydınlatma değişimlerinin kareden kareye titremek veya atlamak yerine düzgünce evrilmesine yardımcı olur. Bu modüller birlikte çalışarak kişinin kimliğini ve hareketini korurken her kareyi aydınlatıp temizlemeyi sağlar.
Modeli Aşamalar Halinde Öğretmek
Büyük önceden eğitilmiş üreticiyi bozmayacak şekilde en iyi şekilde faydalanmak için yazarlar DL-Diff’i üç adımda eğitir. Önce, ağın geri kalanı donuk haldeyken restorasyon modülünü tekil karanlık görüntüleri düzeltmesi için öğretirler. Ardından, zamansal modülü temiz, normal aydınlatılmış videolarda eğiterek doğal hareketin nasıl davrandığını düşük ışık artefaktlarıyla karışmadan öğrenmesini sağlarlar. Son olarak, her iki modülü eşleştirilmiş karanlık ve aydın videolar üzerinde birlikte ince ayarlarlar. Bu müfredat benzeri süreç, durağan görüntüler ile hareketli görüntüler arasındaki boşluğu daraltır ve giriş son derece gürültülü veya neredeyse siyah olduğunda bile sistemin kararlı kalmasına yardımcı olur.

Karanlıkta Daha Keskin, Daha Doğal Yüzler
Gerçek düşük ışıklı videolardan oluşan iki halka açık veri setinde DL-Diff, önde gelen birkaç yönteme kıyasla daha doğal renklere sahip daha net yüzler üretir ve zaman içinde daha az görünür titreme gösterir. İnsan algısına uygun görsel kalite ölçüleri DL-Diff’i destekler; bazı eski teknikler katı piksel başına doğrulukta biraz daha yüksek puanlar alırken bile. Bu ödün görünüme öncelik veren bir tasarım tercihini yansıtır: yeni yöntem her pikseli birebir eşlemekten ziyade izleyiciye doğru görüneni vurgular. Başlıca dezavantaj hızdır—difüzyon modelleri her kareyi birçok adımda iyileştirdiği için işlem daha yavaştır—ancak yazarlar daha yeni, daha hızlı varyantların gelecekte bunu hafifletebileceğine dikkat çeker. Genel olarak DL-Diff, dikkatle uyarlanmış modern üretici modellerin neredeyse kullanılamaz karanlık yüz videoları göze hoş, kararlı görüntülere dönüştürebileceğini gösterir; bu görüntüler gözetim, fotoğrafçılık ve diğer gerçek dünya uygulamaları için uygundur.
Atıf: Ding, X., He, K., Sun, H. et al. Temporally consistent low-light face video enhancement via video-to-video conditional diffusion. Sci Rep 16, 14097 (2026). https://doi.org/10.1038/s41598-026-44219-8
Anahtar kelimeler: düşük ışıklı video, yüz iyileştirme, difüzyon modelleri, video restorasyonu, zamansal tutarlılık