Clear Sky Science · it
Enhancement temporale coerente di video con volti in condizioni di scarsa illuminazione tramite diffusione condizionata video-a-video
Far emergere i volti dal buio
Chiunque abbia provato a filmare una persona di notte sa che il risultato può essere un pasticcio torbido e sgranato: i volti scompaiono nelle ombre, i colori appaiono alterati e i dettagli tremolano da un fotogramma all’altro. Questo articolo presenta DL-Diff, un nuovo metodo di intelligenza artificiale che trasforma tali video scuri e rumorosi in clip luminose e dall’aspetto naturale che scorrono in modo uniforme, senza lo sfarfallio e lo scintillio fastidiosi che spesso affliggono le tecniche precedenti. Il lavoro è rilevante per la fotografia quotidiana, le telecamere di sicurezza domestica e persino i sistemi di assistenza alla guida che devono riconoscere persone in condizioni di scarsa illuminazione.
Perché i video notturni sono così difficili
I video con volti in scarsa illuminazione presentano una doppia sfida. Da un lato, ogni fotogramma è compromesso da forte rumore, spostamenti cromatici e dettagli persi perché pochissimi fotoni raggiungono il sensore della fotocamera. Dall’altro, un video non è solo una pila di immagini: i nostri occhi sono molto sensibili a salti di luminosità o di forma da un fotogramma all’altro. Molti metodi esistenti trattano ogni fotogramma separatamente o si basano su stime grossolane del moto tra i fotogrammi. Questo può aiutare un poco, ma spesso lascia dietro di sé sfarfallii o volti deformati, specialmente quando la scena è estremamente buia e il movimento è complesso.
Una nuova pipeline da buio a luce
DL-Diff affronta il problema considerando il miglioramento in scarsa luce come una vera trasformazione video-a-video invece che come un ritocco fotogramma per fotogramma. Si basa su potenti generatori di “diffusione” originariamente addestrati per creare immagini e brevi video da prompt testuali. Questi generatori operano partendo da rumore casuale e raffinando gradualmente l’immagine fino a ottenere un risultato pulito. DL-Diff riadatta tale modello in modo che, invece di seguire una descrizione testuale, il generatore sia guidato dal video di input scuro. Operando in una rappresentazione interna compatta anziché direttamente sui pixel, il sistema può rimuovere il rumore e immaginare dettagli mancanti pur rispettando il contenuto complessivo della ripresa originale.
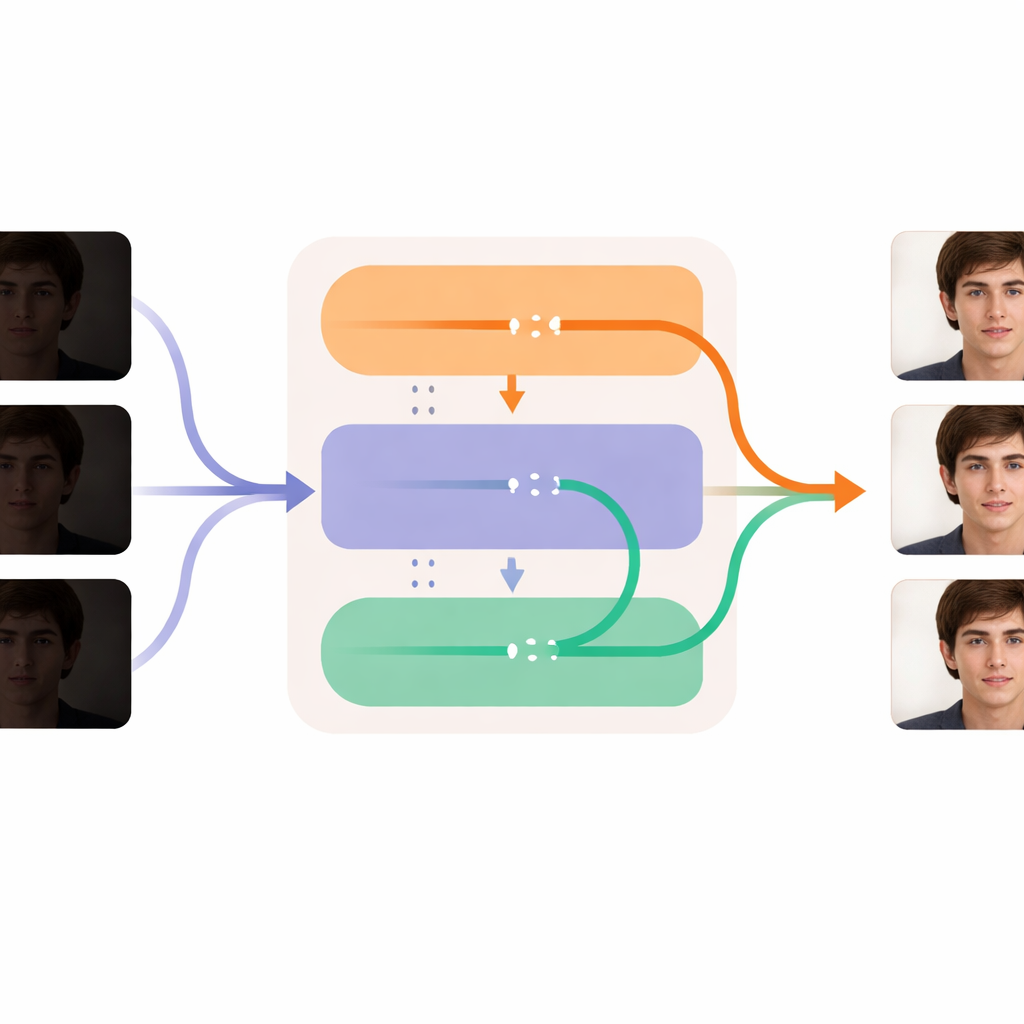
Rendere ogni fotogramma nitido preservando la continuità temporale
Il cuore di DL-Diff è suddiviso in due moduli cooperanti che rispecchiano il modo in cui percepiamo un video. La parte di “restauro” si concentra sullo spazio: osserva ogni fotogramma e inietta dettagli, texture e colori più realistici negli strati interni del generatore, compensando ciò che è stato perso nel buio. Questo modulo viene addestrato prima su coppie di immagini individuali, imparando come dovrebbe apparire un volto poco illuminato una volta correttamente esposto. La parte “temporale” si concentra sul tempo: rimodella il modello in modo che, in fasi chiave dell’elaborazione, possa confrontare informazioni tra i fotogrammi e allinearli dolcemente. Questo aiuta espressioni, movimenti della testa e variazioni di illuminazione a evolvere in modo fluido da un fotogramma all’altro anziché tremolare o scattare. Insieme, questi moduli permettono al sistema di illuminare e pulire ogni fotogramma mantenendo stabile l’identità e il movimento della persona in tutto il video.
Insegnare il modello per fasi
Per sfruttare al meglio il grande generatore pre-addestrato senza disturbare ciò che ha già appreso, gli autori addestrano DL-Diff in tre passaggi. Prima insegnano al modulo di restauro a correggere singole immagini scure mentre il resto della rete rimane congelato. Poi addestrano il modulo temporale su video puliti e normalmente illuminati in modo che impari come si comporta il moto naturale senza essere confuso dagli artefatti da scarsa illuminazione. Infine, affinano entrambi i moduli insieme su video accoppiati scuri e luminosi. Questo processo simile a un curriculum riduce il divario tra immagini statiche e riprese in movimento e aiuta il sistema a rimanere stabile anche quando l’input è estremamente rumoroso o quasi nero.

Volti più nitidi e naturali nel buio
Su due dataset pubblici di video reali in condizioni di scarsa illuminazione, DL-Diff produce volti più nitidi e con colori più naturali rispetto a diversi metodi di punta, e lo fa con meno sfarfallio visibile nel tempo. Misure di qualità visiva allineate alla percezione umana favoriscono DL-Diff, anche se alcune tecniche più datate ottengono punteggi leggermente migliori su rigide metriche pixel-per-pixel. Il compromesso riflette una scelta di progetto: il nuovo metodo privilegia ciò che appare corretto a un osservatore piuttosto che l’aderenza assoluta a ogni singolo pixel. L’unico svantaggio principale è la velocità: poiché i modelli di diffusione raffinano ogni fotogramma attraverso molti passaggi, l’elaborazione è più lenta rispetto ad approcci più semplici, ma gli autori osservano che varianti più recenti e più veloci potrebbero mitigare questo limite in futuro. Nel complesso, DL-Diff dimostra che i modelli generativi moderni, quando adattati con cura, possono trasformare video con volti quasi inutilizzabili in riprese luminose e stabili adatte per sorveglianza, fotografia e altre applicazioni del mondo reale.
Citazione: Ding, X., He, K., Sun, H. et al. Temporally consistent low-light face video enhancement via video-to-video conditional diffusion. Sci Rep 16, 14097 (2026). https://doi.org/10.1038/s41598-026-44219-8
Parole chiave: video in condizioni di scarsa illuminazione, miglioramento dei volti, modelli di diffusione, restauro video, coerenza temporale