Clear Sky Science · ar
تعزيز فيديو الوجوه منخفض الإضاءة مع اتساق زمني عبر الانتشار الشرطي من فيديو إلى فيديو
إخراج الوجوه من الظلام
أي شخص حاول تصوير شخص في الليل يعرف أن النتيجة قد تكون فوضى معتمة وحبيبية: تختفي الوجوه في الظلال، تبدو الألوان غير صحيحة، وتتقلب التفاصيل من إطار لآخر. يقدم هذا البحث DL-Diff، طريقة ذكاء اصطناعي جديدة تحوّل مثل هذه مقاطع فيديو الوجوه المظلمة والمشحونة بالضوضاء إلى مقاطع مضيئة وطبيعية المظهر تتشغّل بسلاسة، من دون الوميض والتقلب الملهيان اللذين غالبًا ما تعاني منهما تقنيات سابقة. العمل مهم للتصوير اليومي، وكاميرات المراقبة المنزلية، وحتى لأنظمة مساعدة السائق التي تحتاج إلى التعرف على الأشخاص في ظروف إضاءة ضعيفة.
لماذا تُعدّ مقاطع الفيديو الليلية صعبة جدًا
تشكّل مقاطع فيديو الوجوه منخفضة الإضاءة تحديًا مزدوجًا. من ناحية، يتضرر كل إطار بضوضاء كثيفة، وتحولات لونية، وفقدان تفاصيل لأن القليل جدًا من الفوتونات يصل إلى حساس الكاميرا. ومن ناحية أخرى، الفيديو ليس مجرد تراكب صور: عيوننا حساسة جدًا للقفزات في السطوع أو الشكل من إطار إلى آخر. العديد من الطرق الحالية تتعامل مع كل إطار على حدة أو تعتمد على تقديرات حركة تقريبية بين الإطارات. هذا قد يساعد قليلًا، لكنه غالبًا ما يترك وميضًا أو تشوّهًا في الوجوه، خاصة عندما يكون المشهد مظلمًا للغاية وحركة الكاميرا أو الأشخاص معقّدة.
خط معالجة جديد من الظلام إلى الضوء
يتعامل DL-Diff مع المشكلة باعتبار تعزيز منخفض الإضاءة تحويلًا شاملاً من فيديو إلى فيديو بدلًا من تعديل كل إطار على حدة. يبني على مولِّدات "الانتشار" القوية التي تدربت أصلاً لإنشاء صور ومقاطع فيديو قصيرة من أوصاف نصية. تعمل هذه المولدات بالبدء من ضوضاء عشوائية ثم تنقحها تدريجيًا لتتحول إلى صورة نظيفة. يعيد DL-Diff استخدام مثل هذا النموذج بحيث يُوجَّه، بدلًا من اتباع وصف نصي، بواسطة الفيديو المظلم الفعلي المدخل. من خلال العمل في تمثيل داخلي مضغوط بدلًا من البكسلات مباشرة، يمكن للنظام أن يزيل الضوضاء ويتخيل التفاصيل المفقودة مع الحفاظ على المحتوى العام للقطات الأصلية.
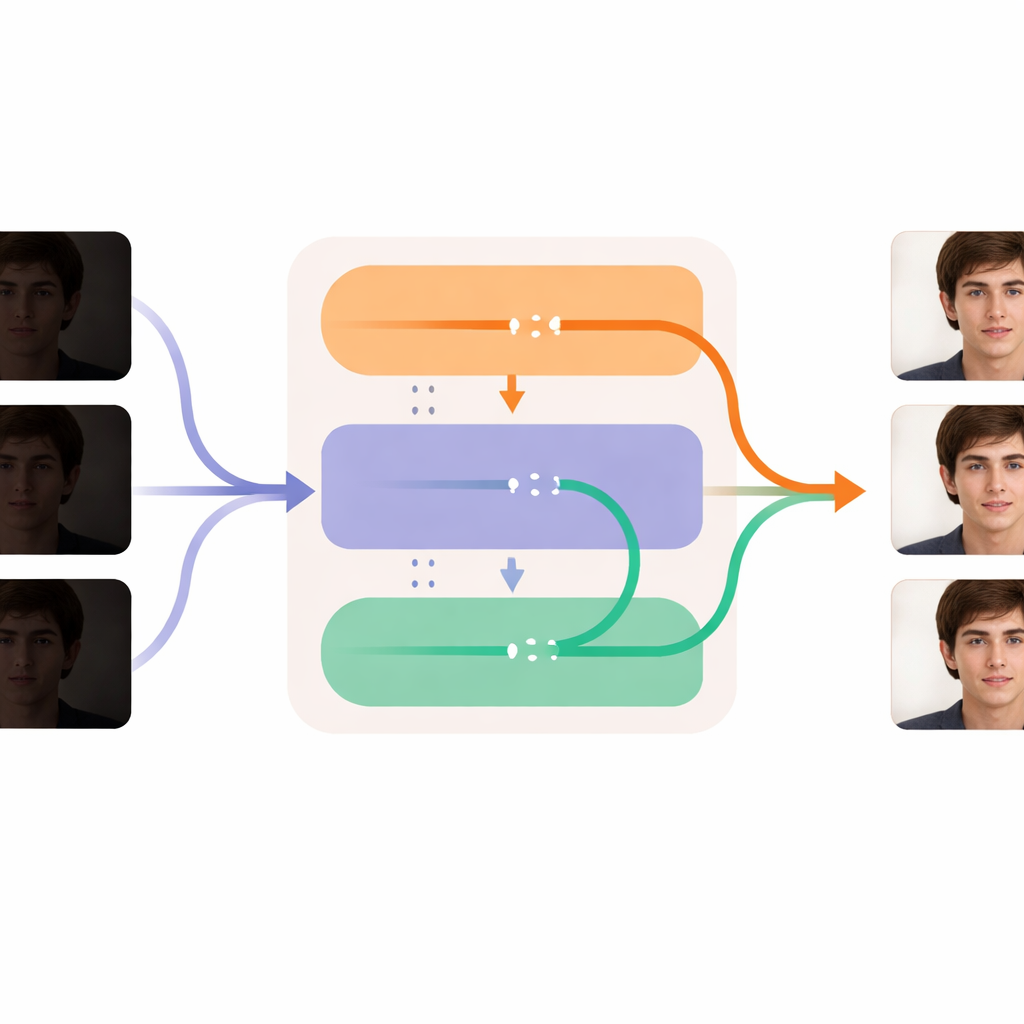
تحسين كل إطار مع الحفاظ على سلاسة الزمن
يكمن جوهر DL-Diff في وحدتين متعاونتين تعكسان كيف نختبر الفيديو. يركِّز جزء "الاستعادة" على المكان: ينظر إلى كل إطار ويضيف تفاصيل وملمسًا وألوانًا أكثر واقعية إلى طبقات المولد الداخلية، معوضًا ما فقد في الظلام. تُدرّب هذه الوحدة أولًا على أزواج صور فردية، لتتعلم كيف ينبغي أن يبدو الوجه الخافت عندما يُضاء بشكل صحيح. يركِّز الجزء "الزمني" على الزمن: يعيد تشكيل النموذج بحيث، في مراحل رئيسية من المعالجة، يمكنه مقارنة المعلومات عبر الإطارات وسحبها بلطف إلى محاذاة. يساعد ذلك التعبيرات وحركات الرأس وتغيرات الإضاءة على التطور بسلاسة من إطار لآخر بدلًا من الارتجاج أو القفز. معًا تسمح هاتان الوحدتان للنظام بتفتيح وتنظيف كل إطار مع الحفاظ على هوية الشخص وحركته ثابتة عبر الفيديو بالكامل.
تعلّم النموذج على مراحل
للاستفادة القصوى من المولد المدرب مسبقًا دون الإخلال بما تعلّمه سابقًا، يدرب المؤلفون DL-Diff على ثلاث مراحل. أولًا، يعلّمون وحدة الاستعادة إصلاح الصور المظلمة المفردة بينما يبقى بقية الشبكة مجمّدًا. بعد ذلك، يدربون الوحدة الزمنية على مقاطع فيديو نظيفة ومضاءة بشكل طبيعي حتى تتعلّم سلوك الحركة الطبيعي دون أن تشتتها تشوّهات الإضاءة المنخفضة. أخيرًا، ينعّمون كلا الوحدتين معًا على مقاطع فيديو مقترنة مظلمة ومضيئة. هذه العملية الشبيهة بالمناهج الدراسية تضيق الفجوة بين الصور الثابتة واللقطات المتحركة وتساعد النظام على البقاء مستقرًا حتى عندما يكون الإدخال شديد الضجيج أو شبه مظلم.

وجوه أكثر حدة وطبيعية في الظلام
على مجموعتين عامتين لمقاطع الفيديو الحقيقية منخفضة الإضاءة، ينتج DL-Diff وجوهًا أوضح بألوان أكثر طبيعية من عدة طرق رائدة، ويحقق ذلك مع وميض مرئي أقل مع مرور الوقت. تفضّل مقاييس جودة بصرية متوافقة مع تقييم بشري DL-Diff، رغم أن بعض التقنيات الأقدم تسجل نتائج أفضل قليلًا على دقة البكسل الصارمة إطارًا بإطار. تعكس هذه المقايضة خيار تصميمي: تركز الطريقة الجديدة على ما يبدو صحيحًا للمشاهد بدلًا من مطابقة كل بكسل حرفيًّا. العائق الرئيسي هو السرعة—بحكم أن نماذج الانتشار تنقح كل إطار عبر خطوات عديدة، تكون المعالجة أبطأ من الأساليب الأبسط—لكن المؤلفين يشيرون إلى أن نُسخًا أحدث وأسرع قد تخفف هذا لاحقًا. بشكل عام، يظهر DL-Diff أن النماذج التوليدية الحديثة، عند تكييفها بعناية، يمكن أن تحوّل مقاطع فيديو للوجوه شبه غير صالحة إلى لقطات مضيئة ومستقرة مناسبة للمراقبة، والتصوير، وتطبيقات العالم الحقيقي الأخرى.
الاستشهاد: Ding, X., He, K., Sun, H. et al. Temporally consistent low-light face video enhancement via video-to-video conditional diffusion. Sci Rep 16, 14097 (2026). https://doi.org/10.1038/s41598-026-44219-8
الكلمات المفتاحية: فيديو منخفض الإضاءة, تحسين الوجوه, نماذج الانتشار, استعادة الفيديو, الاتساق الزمني