Clear Sky Science · ja
ビデオ間条件付き拡散による時間的一貫性を持つ低照度顔ビデオの強調
暗闇から顔を引き出す
夜間に人物を撮影しようとしたことがある人なら、その結果がどれほど泥濘でノイズだらけになるかを知っています。顔は影に溶け込み、色味が不自然になり、細部がフレームごとにちらつきます。本論文はDL‑Diffという新しい人工知能手法を紹介します。これにより、そのような暗くノイズの多い顔ビデオを、違和感のあるきらめきやちらつきのない、明るく自然な見た目で滑らかに再生されるクリップに変換できます。この仕事は、日常の写真撮影、家庭用防犯カメラ、光量が乏しい状況で人を認識する必要のある運転支援システムなどに重要です。
夜間ビデオが難しい理由
低照度の顔ビデオは二重の課題を突きつけます。一方で、各フレームは到達する光子が非常に少ないため、強いノイズや色ずれ、失われた細部によって損なわれます。他方で、ビデオは単なる画像の重ね合わせではありません:我々の目はフレーム間の明るさや形状の急変に非常に敏感です。既存の多くの手法は各フレームを個別に処理するか、フレーム間の粗い動き推定に頼ります。多少の改善にはなりますが、特にシーンが極端に暗く動きが複雑な場合には、ちらつきや歪んだ顔を残しがちです。
暗から明への新しいパイプライン
DL‑Diffは、低照度の強調をフレーム単位の手直しではなく、ビデオ→ビデオの変換として扱うことで問題に取り組みます。これは、もともとテキストプロンプトから画像や短い動画を生成するために訓練された強力な「拡散」生成器に基づいています。これらの生成器はランダムノイズから始め、徐々にそれを精製してきれいな画像を作り出します。DL‑Diffはこのモデルを再利用し、テキスト記述に従う代わりに実際の暗い入力ビデオによって生成器を導きます。画素上で直接操作するのではなくコンパクトな内部表現で動作することで、ノイズを取り除き失われた細部を補完しつつ、元の映像の全体的な内容を尊重できます。
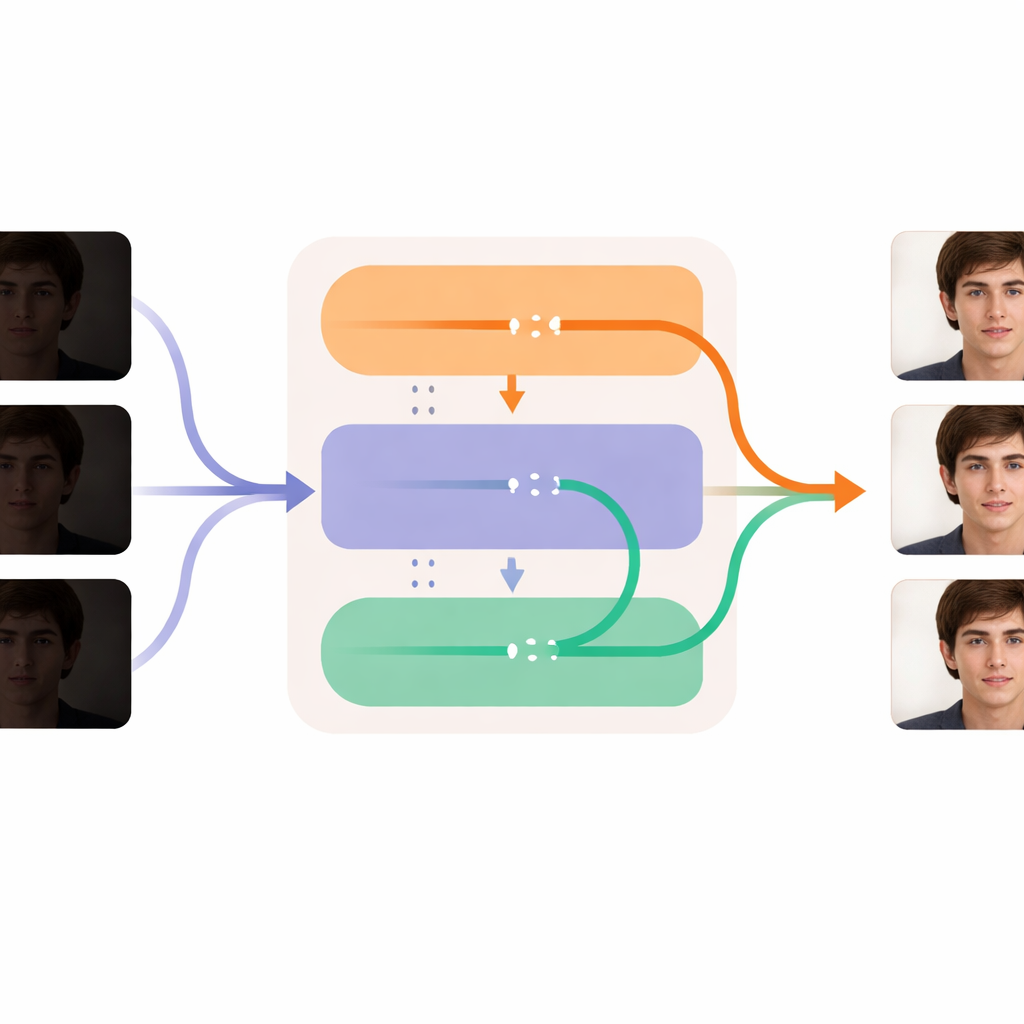
各フレームを鮮明にしつつ時間軸を滑らかに保つ
DL‑Diffの中核は、我々がビデオを体験する仕方を反映した二つの協調モジュールに分かれています。「復元」パートは空間に注目します:各フレームを見て、生成器の内部層に追加の細部、テクスチャ、より現実的な色を注入し、暗闇で失われたものを補います。このモジュールは最初に個別の画像対で訓練され、暗い顔が適切に照らされた際にどう見えるべきかを学習します。「時間」パートは時間に注目します:処理の重要な段階でフレーム間の情報を比較し、穏やかに整合させるようモデルを再構築します。これにより、表情や頭の動き、照明の変化がフレーム間でジャンプやポップではなく滑らかに変化します。これらのモジュールが組み合わさることで、個々のフレームを明るくきれいにしながら、そのビデオ全体で被写体の識別性と動きを安定して保てます。
段階的にモデルを教える
大規模な事前学習済み生成器の利点を損なわずに最大限活用するために、著者らはDL‑Diffを三段階で訓練します。まず復元モジュールを、ネットワークの残りを固定したまま単一の暗い画像を修復するように学習させます。次に、時間モジュールを通常照明のクリーンなビデオで訓練し、低照度アーティファクトに惑わされず自然な動きがどう振る舞うかを学ばせます。最後に、暗いビデオと明るいビデオの対で両方のモジュールを共同で微調整します。このカリキュラムに似た過程は静止画と動画のギャップを狭め、入力が極端にノイズまみれあるいはほぼ黒に近い場合でもシステムの安定性を高めます。

暗闇でより鮮明で自然な顔
実際の低照度ビデオの2つの公開データセットで、DL‑Diffは複数の主要手法よりも自然な色合いでより鮮明な顔を生成し、時間的なちらつきも少なく抑えています。視覚品質を人間の評価に合わせた指標でもDL‑Diffが有利であり、古い手法のいくつかは厳密なピクセル単位の精度でやや良いスコアを出すことがあるものの、その差は設計上の選択を反映しています:新手法はすべてのピクセルを厳密に一致させるよりも、視聴者にとって自然に見えることを重視します。主な欠点は処理速度です—拡散モデルは各フレームを多段階で精製するため、単純な手法より処理に時間がかかりますが、著者らはより高速な新しい変種が将来的にこれを緩和しうると指摘しています。総じて、慎重に適応された現代の生成モデルは、ほとんど使い物にならない暗い顔ビデオを監視、写真撮影、その他の実世界用途に適した明るく安定した映像に変えうることをDL‑Diffは示しています。
引用: Ding, X., He, K., Sun, H. et al. Temporally consistent low-light face video enhancement via video-to-video conditional diffusion. Sci Rep 16, 14097 (2026). https://doi.org/10.1038/s41598-026-44219-8
キーワード: 低照度ビデオ, 顔強調, 拡散モデル, ビデオ復元, 時間的一貫性