Clear Sky Science · ru
Временная согласованность улучшения лиц в слабо освещённом видео с помощью условной видео‑видео диффузии
Выводя лица из темноты
Кто пытался снимать человека ночью, знает: результат часто похож на мутное, зернистое пятно — лица теряются в тени, цвета исказились, а детали мерцают из кадра в кадр. В этой работе представлен DL‑Diff, новый метод ИИ, который превращает такие тёмные, зашумлённые видео с лицами в яркие, естественно выглядящие клипы, воспроизводящиеся плавно, без отвлекающего мерцания и дрожания, присущих ранним подходам. Работа важна для повседневной фотографии, домашних камер наблюдения и даже для систем помощи водителю, которым нужно распознавать людей в плохом свете.
Почему ночные видео такие сложные
Видео лиц в условиях слабого освещения создают двойную задачу. С одной стороны, каждый кадр искажается сильным шумом, сдвигами цвета и потерей деталей, потому что на сенсор камеры попадает очень мало фотонов. С другой стороны, видео — это не просто стопка картинок: наши глаза очень чувствительны к скачкам яркости или формы между кадрами. Многие существующие методы обрабатывают кадры по отдельности или опираются на грубые оценки движения между ними. Это может немного помочь, но часто оставляет мерцание или деформации лиц, особенно когда сцена очень тёмная и движение сложное.
Новый конвейер «из тьмы в свет»
DL‑Diff решает задачу, рассматривая улучшение при слабом освещении как преобразование полного видео‑видео, а не как починку кадр за кадром. Он опирается на мощные «диффузионные» генераторы, изначально обученные создавать изображения и короткие видео по текстовым подсказкам. Эти генераторы работают, начиная с случайного шума и постепенно уточняя его в чистую картинку. DL‑Diff переосмысливает такую модель: вместо того чтобы следовать текстовому описанию, генератор направляется реальным тёмным входным видео. Работая в компактном внутреннем представлении, а не напрямую с пикселями, система умеет удалять шум и домысливать недостающие детали, при этом сохраняя общий содержательный облик исходной съёмки.
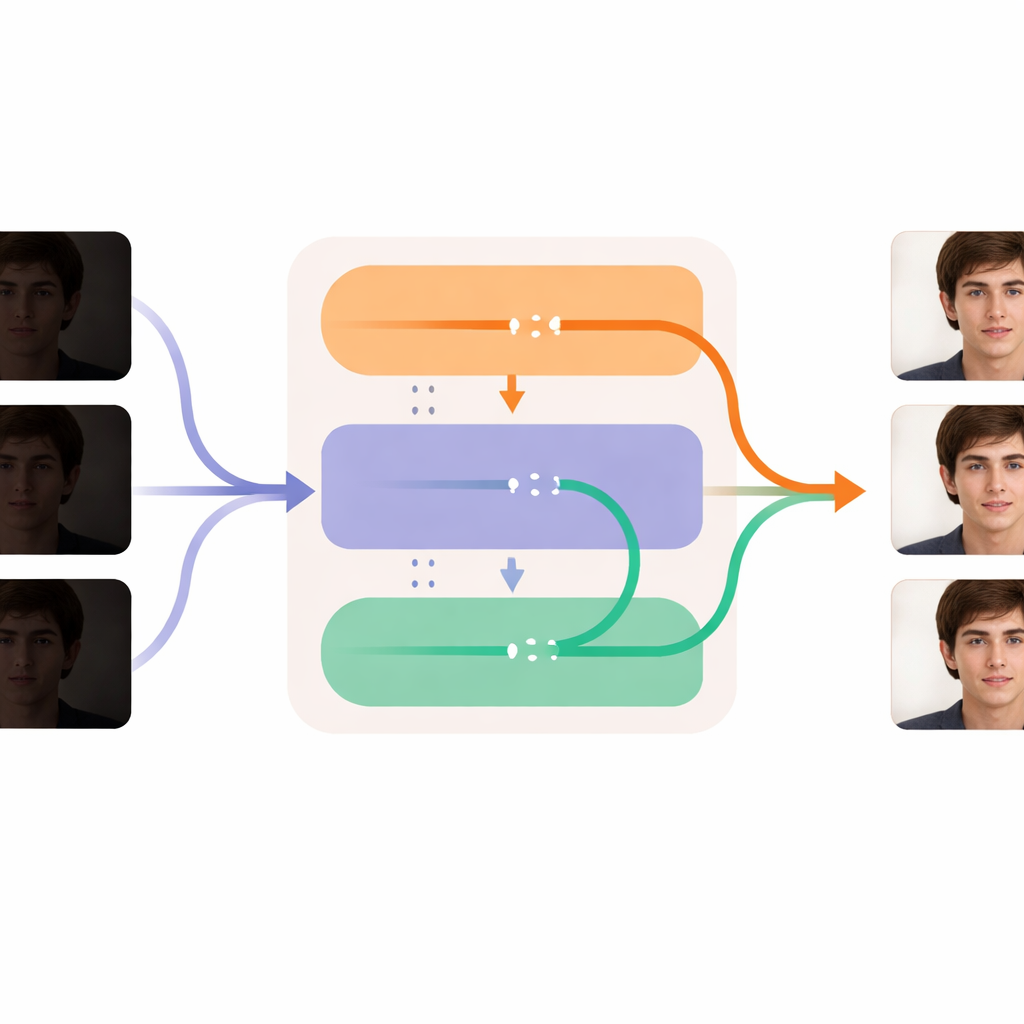
Уточнение каждого кадра при плавном течении времени
Сердце DL‑Diff разделено на два взаимодополняющих модуля, отражающих то, как мы воспринимаем видео. Часть «восстановления» сосредоточена на пространстве: она рассматривает каждый кадр и добавляет детали, текстуру и более реалистичные цвета во внутренние слои генератора, компенсируя то, что было утрачено в темноте. Этот модуль сначала обучают на отдельных парах изображений, чтобы он выучил, как должно выглядеть тусклое лицо при корректном освещении. Часть «временная» сосредоточена на времени: она перестраивает модель так, чтобы на ключевых этапах обработки можно было сравнивать информацию между кадрами и мягко выравнивать их. Это помогает выражениям лица, поворотам головы и изменениям освещения естественно развиваться из кадра в кадр, а не дрожать или прыгать. Вместе эти модули позволяют системе осветлять и очищать каждый кадр, сохраняючи при этом идентичность и движения человека по всему видео.
Поэтапное обучение модели
Чтобы максимально использовать большой предварительно обученный генератор, не нарушая того, что он уже усвоил, авторы обучают DL‑Diff в три этапа. Сначала они учат модуль восстановления исправлять отдельные тёмные изображения при замороженных остальных частях сети. Затем тренируют временной модуль на чистых, нормально освещённых видео, чтобы он выучил, как ведёт себя естественное движение, не смущаясь артефактами слабого освещения. Наконец, они финетюнят оба модуля вместе на парах тёмных и светлых видео. Такой учебный кьюрикулум сокращает разрыв между неподвижными изображениями и движущимися кадрами и помогает системе оставаться устойчивой даже при крайне шумном или почти чёрном входе.

Более чёткие, естественные лица в темноте
На двух публичных наборах реальных видеороликов при слабом освещении DL‑Diff даёт более чёткие лица с естественными цветами по сравнению с несколькими ведущими методами, и делает это с меньшим заметным мерцанием во времени. Метрики качества, согласованные с человеческим восприятием, в большинстве случаев отдают предпочтение DL‑Diff, хотя некоторые старые методы слегка превосходят по строгой покадровой точности пиксель в пиксель. Этот компромисс отражает дизайнерский выбор: новый метод отдаёт приоритет тому, что кажется правильным зрителю, а не точному совпадению каждого пикселя. Главный недостаток — скорость: поскольку диффузионные модели уточняют каждый кадр через множество шагов, обработка медленнее, чем у более простых подходов, — но авторы отмечают, что более быстрые современные варианты могут облегчить эту проблему в будущем. В целом DL‑Diff демонстрирует, что современные генеративные модели, при аккуратной адаптации, способны превращать почти непригодные тёмные видео с лицами в яркие, стабильные записи, пригодные для наблюдения, фотографии и других практических применений.
Цитирование: Ding, X., He, K., Sun, H. et al. Temporally consistent low-light face video enhancement via video-to-video conditional diffusion. Sci Rep 16, 14097 (2026). https://doi.org/10.1038/s41598-026-44219-8
Ключевые слова: видео при слабом освещении, улучшение лиц, диффузионные модели, восстановление видео, временная согласованность