Clear Sky Science · he
שיפור וידאו של פנים בתאורה נמוכה בעקביות זמנית באמצעות דיפוזיה מותנית וידאו-אל-וידאו
מוציאים את הפנים מהחשכה
כל מי שניסה לצלם אדם בלילה יודע שהתוצאה יכולה להיות מבולגנת וגרעינית: הפנים נעלמות בצללים, הצבעים נראים לא נכונים והפרטים מרצדים בין פריימים. המאמר מציג את DL-Diff, שיטה חדשה מבוססת בינה מלאכותית שהופכת קליפים של פנים חשוכים ורעשים לקטעי וידאו מוארים ומראה-טבעי שנעים בצורה חלקה, ללא הנצנוץ והפיקסים המטרידים שאופייניים לשיטות קודמות. העבודה חשובה לצילום יומיומי, מצלמות אבטחה ביתיות ואף למערכות סיוע לנהג שצריכות לזהות אנשים בתנאי תאורה ירודים.
מדוע וידאו בלילה כל כך קשה
וידאו של פנים בתאורה נמוכה מציב אתגר כפול. מצד אחד, כל פריים נפגע מרעש כבד, שינויים בצבעים ואובדן פרטים כי מאוד מעט פוטונים מגיעים לחיישן המצלמה. מצד שני, וידאו הוא לא רק ערימה של תמונות: העין שלנו רגישה מאוד לקפיצות בבהירות או בצורה בין פריימים. רבות מהשיטות הקיימות מטפלות בכל פריים בנפרד או מסתמכות על אומדני תנועה גסים בין פריימים. זה יכול לעזור במעט, אך לעיתים משאיר אחריו תרדמת או עיוות בפנים, במיוחד כאשר הסצנה חשוכה מאוד והתנועה מורכבת.
צינור חדש מהכהה לאור
DL-Diff מתמודד עם הבעיה על ידי התייחסות לשיפור בתאורה נמוכה כהמרה של וידאו-אל-וידאו שלמה במקום תיקון פריים-אחר-פריים. הוא בנוי על מחוללי "דיפוזיה" חזקים שאומנו במקור ליצירת תמונות וסרטונים קצרים מתיאורים טקסטואליים. מחוללים אלה מתחילים מרעש אקראי ומחדדים אותו בהדרגה לתמונה נקייה. DL-Diff ממנף מודל כזה כך שבמקום לעקוב אחרי טקסט, המחולל מונחה על ידי הווידאו הכהה המקורי. על ידי עבודה בייצוג פנימי קומפקטי במקום על פיקסלים ישירות, המערכת יכולה להסיר רעש ולהשליט פרטים חסרים תוך שמירה על התוכן הכללי של החומר המקורי.
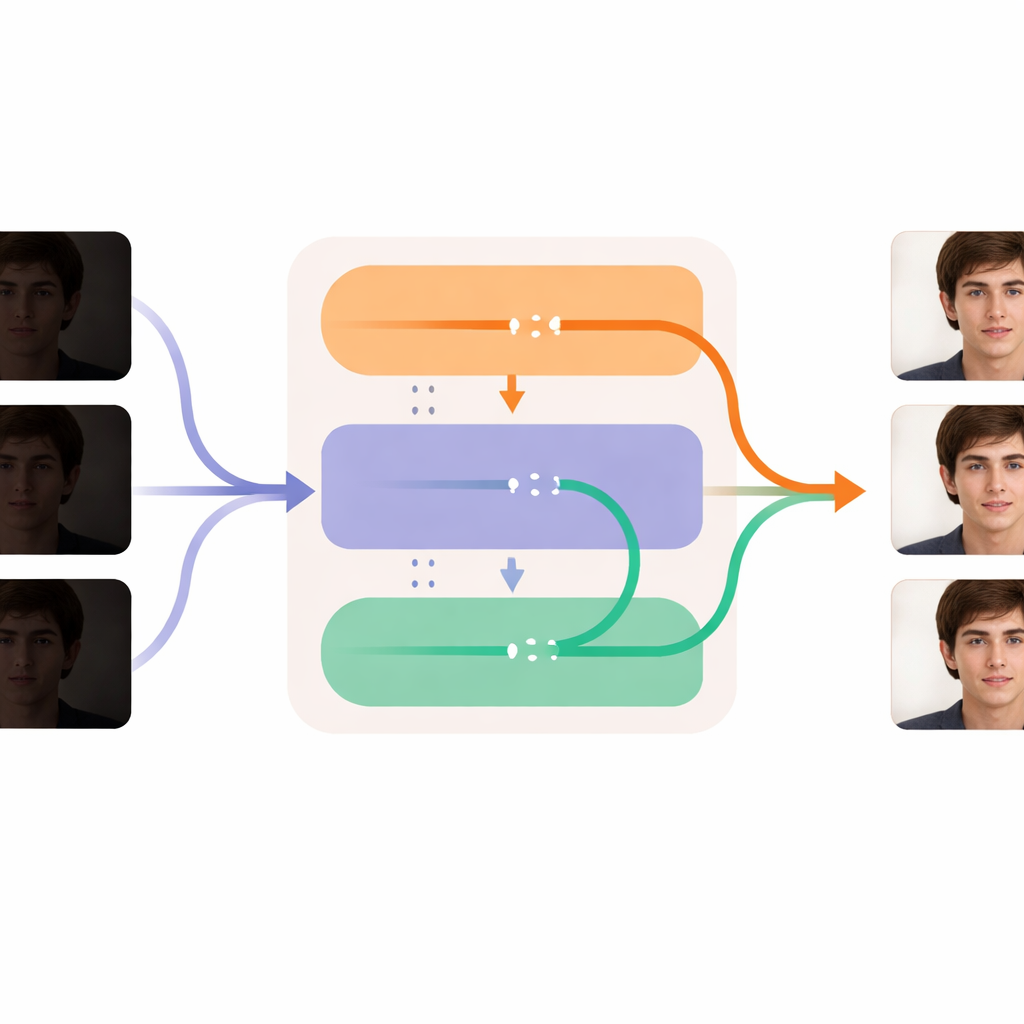
חדות בכל פריים תוך שמירה על רכות הזמן
הלב של DL-Diff מחולק לשני מודולים משתפים פעולה שמשקפים כיצד אנו חווים וידאו. חלק ה"שחזור" מתמקד במרחב: הוא בוחן כל פריים ומזריק פרטים נוספים, מרקם וצבעים ריאליסטיים לשכבות הפנימיות של המחולל, מפצה על מה שאבד בחשכה. מודול זה מאומן תחילה על זוגות תמונות בודדות, לומד איך פנים כהות צריכות להיראות כשהן מוארות כראוי. החלק ה"זמני" מתמקד בזמן: הוא מעצב את המודל כך שבשלבים מרכזיים בעיבוד הוא יכול להשוות מידע בין פריימים ולמשוך אותם בעדינות ליישור. זה עוזר להבטיח שהבעות, סיבובי ראש ושינויים בתאורה יתפתחו בצורה חלקה מפריים לפריים במקום לקפוץ או להופיע בבת אחת. יחד, המודולים מאפשרים להבהיר ולנקות כל פריים תוך שמירה על זהות האדם ותנועתו קבועות לאורך כל הווידאו.
הלימוד של המודל בשלבים
כדי להפיק את המרב מהמחולל המאומן מראש בלי להפריע למה שכבר נלמד, המחברים מאמנים את DL-Diff בשלוש שלבים. ראשית, הם מלמדים את מודול השחזור לתקן תמונות חשוכות בודדות בעוד שאר הרשת קפואה. לאחר מכן הם מאמנים את המודול הזמני על וידאו נקי ומואר באופן רגיל כדי שיילמד כיצד נראית תנועה טבעית בלי להיסחף על ידי ארטיפקטים של תאורה נמוכה. לבסוף, הם מיקצעים (fine-tune) את שני המודולים יחד על זוגות וידאו כהים ובהירים. תהליך הדומה לתוכנית לימודים מצמצם את הפער בין תמונות סטילס לחומר נייד ועוזר למערכת להישאר יציבה אפילו כאשר הקלט רעוע מאוד או כמעט שחור.

פנים חדים וטבעיים יותר בחשכה
במתן לשתי מערכות נתונים ציבוריות של וידאו אמיתי בתאורה נמוכה, DL-Diff מייצר פנים חדות יותר עם צבעים טבעיים יותר מאשר כמה מהשיטות המובילות, והוא עושה זאת עם פחות נצנוץ גלוי לאורך הזמן. מדדים מותאמים להערכת איכות חזותית בעין אדם מעדיפים את DL-Diff, אף כי כמה טכניקות ישנות מקבלות ציון מעט טוב יותר על דיוק פיקסל-אחר-פיקסל מחמיר. הפשרה הזו משקפת בחירת עיצוב: השיטה החדשה מדגישה מה נראה נכון לצופה במקום להתאים כל פיקסל בדיוק מוחלט. החיסרון העיקרי הוא מהירות—מכיוון שמודלי דיפוזיה מחדדים כל פריים דרך מספר רב של שלבים, העיבוד איטי יותר מגישות פשוטות יותר—אך המחברים מציינים שגרסאות חדשות ומהירות יותר עשויות להקל על כך בעתיד. בסך הכל, DL-Diff מראה שמודלים גנרטיביים מודרניים, כאשר מותאמים בקפידה, יכולים להפוך קטעי וידאו של פנים כמעט בלתי-שימושיים לחומר מואר, יציב ומתאים לצרכי פיקוח, צילום ויישומים אחרים במציאות.
ציטוט: Ding, X., He, K., Sun, H. et al. Temporally consistent low-light face video enhancement via video-to-video conditional diffusion. Sci Rep 16, 14097 (2026). https://doi.org/10.1038/s41598-026-44219-8
מילות מפתח: וידאו בתאורה נמוכה, שיפור פנים, מודלי דיפוזיה, שחזור וידאו, עקביות זמנית