Clear Sky Science · pt
Melhoria temporalmente consistente de vídeos de rostos com pouca luz via difusão condicional vídeo-a-vídeo
Trazendo rostos para fora da escuridão
Qualquer pessoa que já tentou filmar alguém à noite sabe que o resultado pode ser uma bagunça turva e granulada: rostos desaparecem nas sombras, as cores parecem erradas e detalhes piscam de um quadro para outro. Este artigo apresenta o DL-Diff, um novo método de inteligência artificial que transforma esses vídeos de rostos escuros e ruidosos em clipes claros e com aparência natural que reproduzem suavemente, sem o cintilar e o tremeluzir que frequentemente afetam técnicas anteriores. O trabalho é relevante para fotografia cotidiana, câmeras de segurança domésticas e até sistemas de assistência ao motorista que precisam reconhecer pessoas em pouca luz.
Por que vídeos noturnos são tão difíceis
Vídeos de rostos em baixa luminosidade apresentam um duplo desafio. Por um lado, cada quadro é danificado por ruído intenso, deslocamentos de cor e perda de detalhes porque pouquíssimos fótons atingem o sensor da câmera. Por outro lado, um vídeo não é apenas uma pilha de imagens: nossos olhos são altamente sensíveis a saltos de brilho ou forma de um quadro para o próximo. Muitos métodos existentes tratam cada quadro separadamente ou dependem de estimativas de movimento grosseiras entre quadros. Isso pode ajudar um pouco, mas frequentemente deixa para trás cintilação ou rostos distorcidos, especialmente quando a cena está extremamente escura e o movimento é complexo.
Um novo fluxo do escuro para a luz
O DL-Diff resolve o problema tratando a melhoria de pouca luz como uma transformação completa vídeo-a-vídeo em vez de um retoque quadro a quadro. Ele se baseia em poderosos geradores de “difusão” originalmente treinados para criar imagens e vídeos curtos a partir de instruções em texto. Esses geradores funcionam começando a partir de ruído aleatório e refinando-o gradualmente até obter uma imagem limpa. O DL-Diff reutiliza esse tipo de modelo de modo que, em vez de seguir uma descrição textual, o gerador é guiado pelo próprio vídeo escuro de entrada. Operando em uma representação interna compacta em vez de diretamente nos pixels, o sistema pode eliminar o ruído e alucinar detalhes faltantes respeitando, ao mesmo tempo, o conteúdo geral da filmagem original.
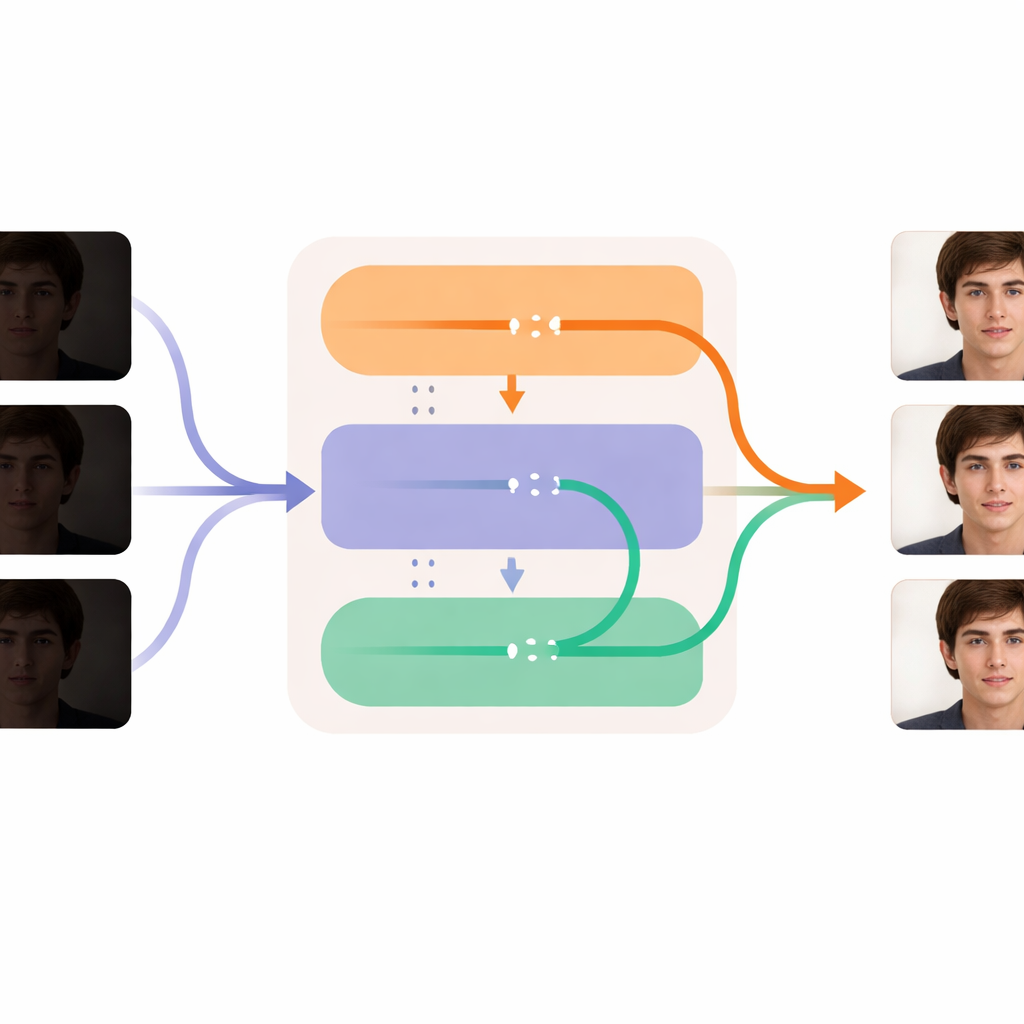
Afiando cada quadro enquanto mantém o tempo suave
O cerne do DL-Diff é dividido em dois módulos cooperativos que espelham como experienciamos vídeo. A parte de “restauração” foca no espaço: ela analisa cada quadro e injeta detalhes extras, textura e cores mais realistas nas camadas internas do gerador, compensando o que foi perdido na escuridão. Esse módulo é treinado primeiro em pares individuais de imagens, aprendendo como um rosto pouco iluminado deveria ficar quando devidamente iluminado. A parte “temporal” foca no tempo: ela remodela o modelo para que, em etapas-chave do processamento, ele possa comparar informações entre quadros e alinhá-los suavemente. Isso ajuda expressões, movimentos de cabeça e mudanças de iluminação a evoluírem de forma suave quadro a quadro em vez de tremerem ou estourarem. Juntos, esses módulos permitem que o sistema clareie e limpe cada quadro enquanto mantém a identidade da pessoa e o movimento estáveis ao longo de todo o vídeo.
Ensinando o modelo em etapas
Para aproveitar ao máximo o grande gerador pré-treinado sem perturbar o que ele já aprendeu, os autores treinam o DL-Diff em três etapas. Primeiro, eles ensinam o módulo de restauração a corrigir imagens escuras individuais enquanto o restante da rede permanece congelado. Em seguida, treinam o módulo temporal em vídeos limpos e normalmente iluminados para que ele aprenda como o movimento natural se comporta sem se confundir com artefatos de baixa luminosidade. Por fim, ajustam ambos os módulos juntos em vídeos emparelhados escuros e claros. Esse processo em estilo currículo reduz a lacuna entre imagens fixas e filmagens em movimento e ajuda o sistema a permanecer estável mesmo quando a entrada é extremamente ruidosa ou quase preta.

Rostos mais nítidos e naturais no escuro
Em dois conjuntos de dados públicos de vídeos reais em baixa luminosidade, o DL-Diff produz rostos mais claros com cores mais naturais do que vários métodos de ponta, e faz isso com menos cintilação visível ao longo do tempo. Medidas de qualidade visual alinhadas ao julgamento humano favorecem o DL-Diff, embora algumas técnicas mais antigas obtenham pontuações ligeiramente melhores em precisão estrita pixel a pixel. Essa troca reflete uma escolha de projeto: o novo método enfatiza o que parece correto para um observador em vez de corresponder exatamente a cada pixel. A principal desvantagem é a velocidade — porque modelos de difusão refinam cada quadro em muitos passos, o processamento é mais lento do que abordagens mais simples — mas os autores observam que variantes mais novas e mais rápidas podem amenizar isso no futuro. No geral, o DL-Diff demonstra que modelos generativos modernos, quando cuidadosamente adaptados, podem transformar vídeos de rostos quase inutilizáveis em filmagens claras e estáveis adequadas para vigilância, fotografia e outras aplicações do mundo real.
Citação: Ding, X., He, K., Sun, H. et al. Temporally consistent low-light face video enhancement via video-to-video conditional diffusion. Sci Rep 16, 14097 (2026). https://doi.org/10.1038/s41598-026-44219-8
Palavras-chave: vídeo com pouca luz, melhoria de rosto, modelos de difusão, restauração de vídeo, consistência temporal