Clear Sky Science · es
Mejora temporalmente consistente de vídeos de rostros con poca luz mediante difusión condicional video-a-video
Sacando los rostros de la oscuridad
Cualquiera que haya intentado grabar a una persona de noche sabe que el resultado puede ser un desastre turbio y granuloso: los rostros se pierden en las sombras, los colores se ven incorrectos y los detalles parpadean de un fotograma a otro. Este artículo presenta DL-Diff, un nuevo método de inteligencia artificial que convierte esos vídeos de rostros oscuros y ruidosos en secuencias brillantes y de aspecto natural que se reproducen de forma fluida, sin el brillo y el parpadeo molestos que a menudo afectan a técnicas anteriores. Este trabajo es relevante para la fotografía cotidiana, las cámaras de seguridad domésticas e incluso los sistemas de asistencia al conductor que deben reconocer personas con poca luz.
Por qué los vídeos nocturnos son tan difíciles
Los vídeos de rostros con poca luz plantean un doble desafío. Por un lado, cada fotograma está dañado por un ruido intenso, cambios de color y pérdida de detalles porque muy pocos fotones alcanzan el sensor de la cámara. Por otro lado, un vídeo no es solo una pila de imágenes: nuestros ojos son muy sensibles a los saltos de brillo o de forma de un fotograma a otro. Muchos métodos existentes tratan cada fotograma por separado o se apoyan en estimaciones toscas de movimiento entre fotogramas. Eso puede ayudar algo, pero con frecuencia deja parpadeos o rostros deformados, especialmente cuando la escena es extremadamente oscura y el movimiento es complejo.
Un nuevo flujo de trabajo de oscuro a claro
DL-Diff aborda el problema tratando la mejora de poca luz como una transformación completa de vídeo a vídeo en lugar de un retoque fotograma a fotograma. Se basa en potentes generadores de "difusión" entrenados originalmente para crear imágenes y vídeos cortos a partir de indicaciones de texto. Estos generadores funcionan comenzando desde ruido aleatorio y refinándolo gradualmente hasta obtener una imagen limpia. DL-Diff reutiliza dicho modelo de modo que, en lugar de seguir una descripción textual, el generador se guía por el vídeo de entrada oscuro real. Al operar en una representación interna compacta en lugar de directamente sobre los píxeles, el sistema puede eliminar ruido e imaginar detalles faltantes mientras respeta el contenido general del metraje original.
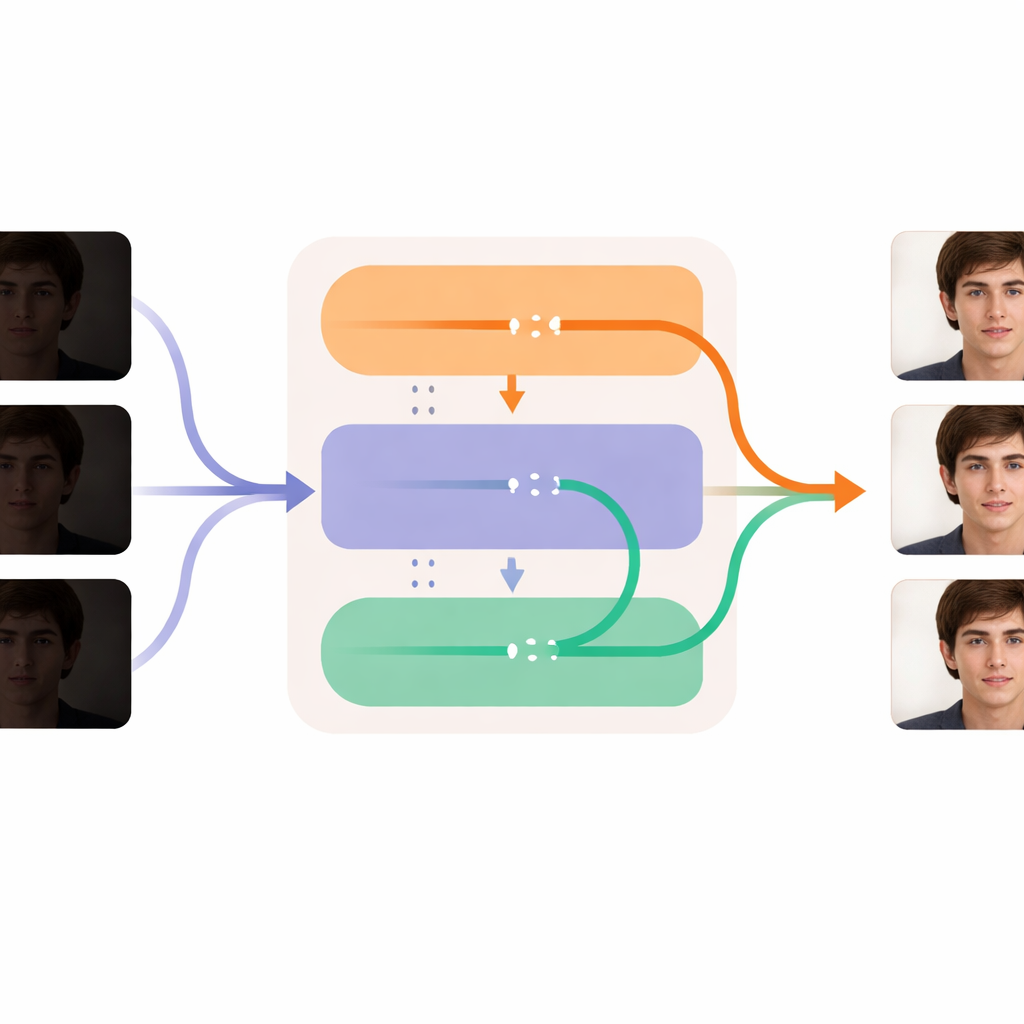
Afinando cada fotograma manteniendo la fluidez temporal
El núcleo de DL-Diff está dividido en dos módulos cooperativos que reflejan cómo percibimos un vídeo. La parte de "restauración" se centra en el espacio: analiza cada fotograma e inyecta detalle adicional, textura y colores más realistas en las capas internas del generador, compensando lo que se perdió en la oscuridad. Este módulo se entrena primero con pares de imágenes individuales, aprendiendo cómo debería verse un rostro tenue una vez correctamente iluminado. La parte "temporal" se centra en el tiempo: reorganiza el modelo para que, en etapas clave del procesamiento, pueda comparar información entre fotogramas y alinearlos suavemente. Esto ayuda a que las expresiones, los movimientos de la cabeza y los cambios de iluminación evolucionen de forma fluida entre fotogramas en lugar de producir sacudidas o saltos. Juntos, estos módulos permiten al sistema iluminar y limpiar cada fotograma manteniendo la identidad y el movimiento de la persona estables a lo largo de todo el vídeo.
Enseñar el modelo por fases
Para aprovechar al máximo el gran generador preentrenado sin alterar lo que ya ha aprendido, los autores entrenan DL-Diff en tres pasos. Primero, enseñan al módulo de restauración a corregir imágenes oscuras individuales mientras el resto de la red permanece congelado. Después, entrenan el módulo temporal con vídeos limpios y con iluminación normal para que aprenda cómo se comporta el movimiento natural sin confundirse por los artefactos de poca luz. Finalmente, afinan ambos módulos juntos con vídeos pareados oscuros y brillantes. Este proceso tipo currículo reduce la brecha entre imágenes estáticas y metraje en movimiento y ayuda a que el sistema siga siendo estable incluso cuando la entrada está extremadamente ruidosa o casi negra.

Rostros más nítidos y naturales en la oscuridad
En dos conjuntos de datos públicos de vídeos reales con poca luz, DL-Diff produce rostros más claros con colores más naturales que varios métodos líderes, y lo hace con menos parpadeo visible a lo largo del tiempo. Medidas de calidad visual alineadas con la percepción humana favorecen a DL-Diff, aunque algunas técnicas más antiguas puntúan ligeramente mejor en precisión estricta píxel a píxel. Esa compensación refleja una elección de diseño: el nuevo método enfatiza lo que resulta correcto para un observador en lugar de igualar cada píxel exactamente. El principal inconveniente es la velocidad: debido a que los modelos de difusión refinan cada fotograma mediante muchos pasos, el procesamiento es más lento que en enfoques más simples, pero los autores apuntan que variantes más nuevas y rápidas podrían aliviar esto en el futuro. En conjunto, DL-Diff demuestra que los modelos generativos modernos, cuando se adaptan con cuidado, pueden convertir vídeos de rostros casi inutilizables en metraje brillante y estable adecuado para vigilancia, fotografía y otras aplicaciones del mundo real.
Cita: Ding, X., He, K., Sun, H. et al. Temporally consistent low-light face video enhancement via video-to-video conditional diffusion. Sci Rep 16, 14097 (2026). https://doi.org/10.1038/s41598-026-44219-8
Palabras clave: vídeo con poca luz, mejora de rostros, modelos de difusión, restauración de vídeo, consistencia temporal