Clear Sky Science · pl
Temporalnie spójne ulepszanie wideo z twarzami w słabym oświetleniu za pomocą warunkowej dyfuzji video-do-video
Wyciąganie twarzy z ciemności
Każdy, kto próbował filmować osobę nocą, wie, że efekt bywa mętny i zaszumiony: twarze znikają w cieniach, kolory są przekłamane, a detale migoczą z klatki na klatkę. W artykule przedstawiono DL-Diff — nową metodę sztucznej inteligencji, która przekształca takie ciemne, zaszumione nagrania twarzy w jasne, naturalnie wyglądające klipy, odtwarzane płynnie, bez rozpraszającego połysku i migotania, które często występują przy wcześniejszych technikach. Praca ma znaczenie dla codziennej fotografii, kamer domowego monitoringu, a nawet systemów wspomagania kierowcy, które muszą rozpoznawać osoby przy słabym oświetleniu.
Dlaczego nagrania nocne są tak trudne
Wideo z twarzami w słabym świetle stawia podwójne wyzwanie. Z jednej strony każda klatka jest zniszczona przez silny szum, przesunięcia kolorów i utratę szczegółów, ponieważ do matrycy trafia bardzo niewiele fotonów. Z drugiej strony wideo to nie tylko stos obrazów: nasze oczy są bardzo wrażliwe na skoki jasności lub kształtu między kolejnymi klatkami. Wiele istniejących metod traktuje każdą klatkę osobno albo polega na niedokładnych oszacowaniach ruchu między klatkami. To może trochę pomóc, ale często pozostawia migotanie lub zniekształcone twarze, szczególnie gdy scena jest ekstremalnie ciemna, a ruch złożony.
Nowy pipeline od ciemności do światła
DL-Diff podchodzi do problemu jako pełnej transformacji video-do-video, zamiast poprawiania klatka po klatce. Opiera się na potężnych generatorach „dyfuzyjnych”, pierwotnie szkolonych do tworzenia obrazów i krótkich filmów na podstawie opisów tekstowych. Te generatory zaczynają od losowego szumu i stopniowo dopracowują go do czystego obrazu. DL-Diff zaadaptowuje taki model tak, że zamiast podążać za opisem tekstowym, generator jest kierowany przez rzeczywiste ciemne wideo wejściowe. Działając w zwartej wewnętrznej reprezentacji zamiast bezpośrednio na pikselach, system potrafi usunąć szum i wygenerować brakujące detale, jednocześnie respektując ogólną zawartość oryginalnego materiału.
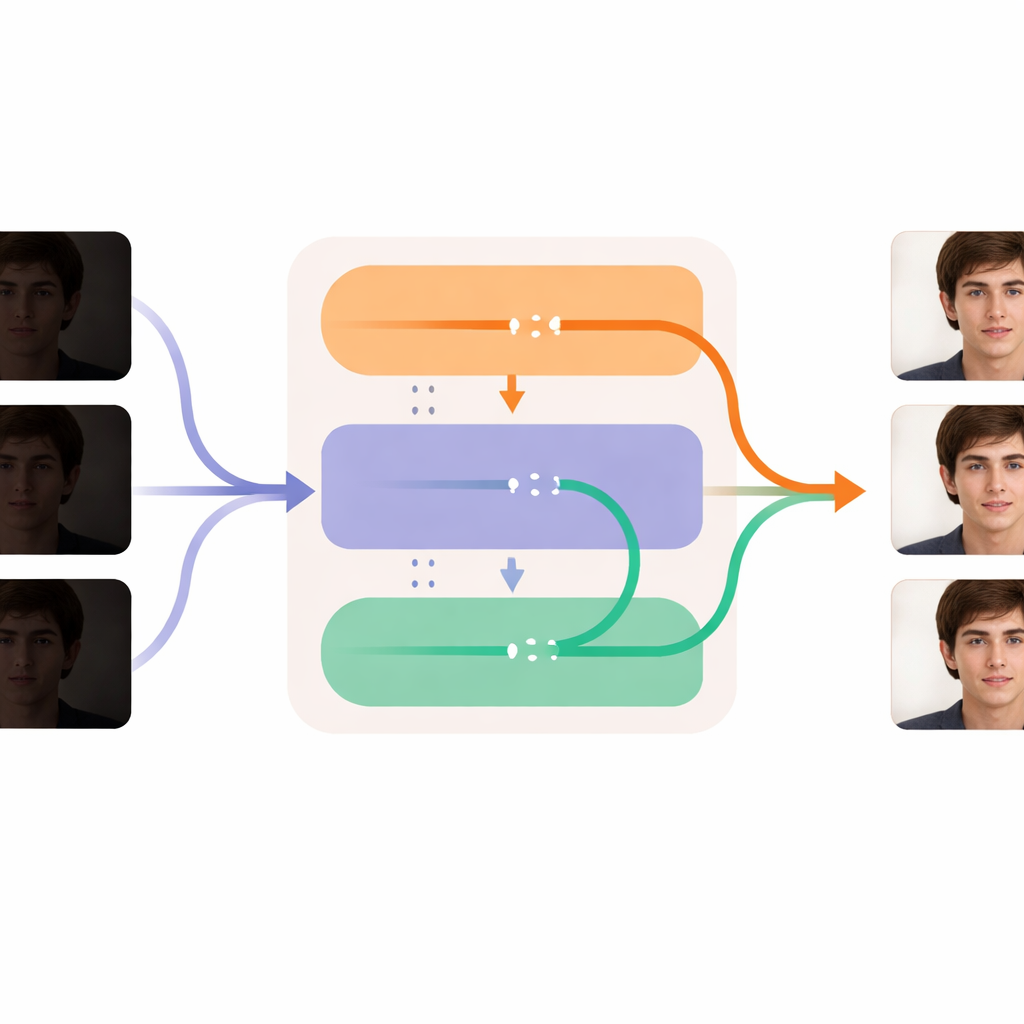
Wyostrzanie każdej klatki przy zachowaniu płynności czasu
Rdzeń DL-Diff dzieli się na dwa współpracujące moduły, które odzwierciedlają sposób, w jaki odbieramy wideo. Część „restauracyjna” koncentruje się na przestrzeni: analizuje każdą klatkę i wprowadza dodatkowe detale, tekstury oraz bardziej realistyczne kolory do wewnętrznych warstw generatora, kompensując to, co utraciło się w ciemności. Ten moduł jest najpierw szkolony na pojedynczych parach obrazów, ucząc się, jak powinna wyglądać przyciemniona twarz po poprawnym doświetleniu. Część „czasowa” skupia się na czasie: przekształca model tak, by na kluczowych etapach przetwarzania mógł porównywać informacje między klatkami i łagodnie wyrównywać je względem siebie. Dzięki temu mimika, ruchy głowy i zmiany oświetlenia rozwijają się płynnie z klatki na klatkę zamiast drgać lub skakać. Razem te moduły pozwalają rozjaśnić i oczyścić każdą klatkę, zachowując jednocześnie tożsamość osoby i spójność ruchu w całym wideo.
Nauczanie modelu etapami
Aby w pełni wykorzystać duży, wstępnie wytrenowany generator, nie naruszając tego, czego już się nauczył, autorzy szkolą DL-Diff w trzech krokach. Najpierw uczą moduł restauracyjny naprawiać pojedyncze ciemne obrazy, podczas gdy reszta sieci pozostaje zamrożona. Następnie trenują moduł czasowy na czystych, normalnie oświetlonych wideo, aby nauczył się, jak zachowuje się naturalny ruch, bez zamieszania powodowanego artefaktami niskiego oświetlenia. Na końcu dostrajają oba moduły razem na sparowanych nagraniach ciemnych i jasnych. Ten proces przypominający program nauczania zmniejsza przepaść między statycznymi obrazami a ruchem i pomaga systemowi pozostać stabilnym nawet wtedy, gdy wejście jest bardzo zaszumione lub prawie czarne.

Bardziej wyraźne, naturalniejsze twarze w ciemności
Na dwóch publicznych zbiorach rzeczywistych nagrań w słabym oświetleniu DL-Diff generuje wyraźniejsze twarze o bardziej naturalnych kolorach niż kilka wiodących metod, i robi to z mniejszym widocznym migotaniem w czasie. Miary jakości wizualnej zgodne z ocenami ludzkimi faworyzują DL-Diff, choć niektóre starsze techniki wypadają nieco lepiej w surowej, piksel-po-pikselu dokładności. To kompromis wynikający z wyboru projektowego: nowa metoda kładzie nacisk na to, co wygląda dobrze dla obserwatora, zamiast idealnie dopasowywać każdy piksel. Głównym mankamentem jest szybkość — ponieważ modele dyfuzyjne dopracowują każdą klatkę przez wiele kroków, przetwarzanie jest wolniejsze niż przy prostszych podejściach — lecz autorzy zauważają, że nowsze, szybsze warianty mogą to złagodzić w przyszłości. Ogólnie rzecz biorąc, DL-Diff pokazuje, że nowoczesne modele generatywne, odpowiednio zaadaptowane, potrafią zamienić niemal nieużyteczne ciemne nagrania twarzy w jasne, stabilne materiały odpowiednie do zastosowań w monitoringu, fotografii i innych realnych zastosowaniach.
Cytowanie: Ding, X., He, K., Sun, H. et al. Temporally consistent low-light face video enhancement via video-to-video conditional diffusion. Sci Rep 16, 14097 (2026). https://doi.org/10.1038/s41598-026-44219-8
Słowa kluczowe: wideo w słabym świetle, poprawa twarzy, modele dyfuzyjne, restauracja wideo, spójność czasowa