Clear Sky Science · de
Zeitlich konsistente Low-Light-Gesichtsvideo-Verbesserung mittels Video-zu-Video-bedingter Diffusion
Gesichter aus der Dunkelheit holen
Wer schon einmal versucht hat, nachts eine Person zu filmen, kennt das Ergebnis: ein trübes, körniges Durcheinander — Gesichter versinken in den Schatten, Farben wirken falsch, und Details flackern von Bild zu Bild. Dieses Paper stellt DL-Diff vor, eine neue KI-Methode, die dunkle, verrauschte Gesichtsaufnahmen in helle, natürlich wirkende Clips verwandelt, die flüssig ablaufen, ohne das ablenkende Schimmern und Flackern, das frühere Techniken oft begleitet. Die Arbeit ist relevant für Alltagsfotografie, private Überwachungskameras und sogar Fahrerassistenzsysteme, die Personen bei schlechten Lichtverhältnissen erkennen müssen.
Warum Videos bei Nacht so schwierig sind
Low-Light-Gesichtsvideos stellen eine doppelte Herausforderung dar. Einerseits ist jedes Einzelbild durch starkes Rauschen, Farbverschiebungen und verlorene Details beschädigt, weil nur sehr wenige Photonen den Sensors erreichen. Andererseits ist ein Video nicht einfach ein Stapel von Bildern: Unsere Augen sind sehr empfindlich gegenüber Sprüngen in Helligkeit oder Form von einem Frame zum nächsten. Viele bestehende Methoden behandeln jedes Bild einzeln oder stützen sich auf grobe Bewegungsabschätzungen zwischen Frames. Das kann etwas helfen, lässt aber oft Flackern oder verzerrte Gesichter zurück, besonders wenn die Szene extrem dunkel ist und die Bewegung komplex.
Eine neue Dark-to-Light-Pipeline
DL-Diff begegnet dem Problem, indem Low-Light-Enhancement als vollständige Video-zu-Video-Transformation statt als Bild-für-Bild-Retusche verstanden wird. Es baut auf leistungsfähigen "Diffusions"-Generatoren auf, die ursprünglich dafür trainiert wurden, Bilder und kurze Videos aus Textvorgaben zu erzeugen. Diese Generatoren arbeiten, indem sie von zufälligem Rauschen ausgehen und es schrittweise zu einem sauberen Bild verfeinern. DL-Diff nutzt ein solches Modell so um, dass der Generator statt einer Textbeschreibung vom tatsächlichen dunklen Eingangsvideo geleitet wird. Indem es in einer kompakten internen Repräsentation operiert statt direkt auf Pixeln, kann das System Rauschen entfernen und fehlende Details ergänzen, während es gleichzeitig den Gesamtinhalt des Originalmaterials respektiert.
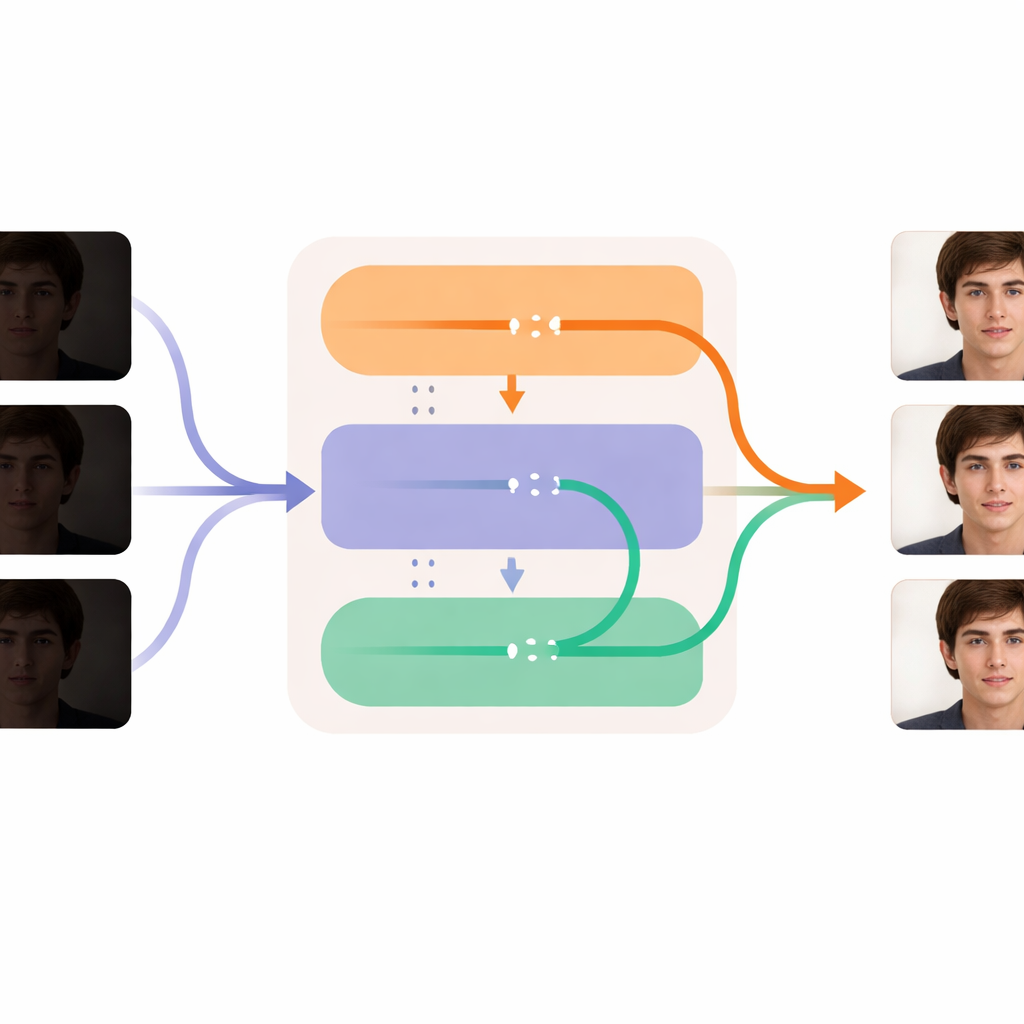
Jedes Bild schärfen und gleichzeitig zeitliche Glätte bewahren
Der Kern von DL-Diff ist in zwei zusammenarbeitende Module unterteilt, die widerspiegeln, wie wir Video wahrnehmen. Der "Restoration"-Teil konzentriert sich auf den Raum: Er betrachtet jedes Bild und fügt in die internen Schichten des Generators zusätzliche Details, Textur und realistischere Farben ein, um das auszugleichen, was in der Dunkelheit verloren ging. Dieses Modul wird zuerst auf einzelnen Bildpaaren trainiert und lernt so, wie ein gedämpftes Gesicht bei korrekter Beleuchtung aussehen sollte. Der "Temporal"-Teil konzentriert sich auf die Zeit: Er formt das Modell so um, dass es in Schlüsselphasen des Prozesses Informationen über Frames hinweg vergleichen und diese sanft aufeinander abstimmen kann. Das hilft dabei, dass Mimik, Kopfbewegungen und Beleuchtungswechsel sich zwischen den Frames gleichmäßig entwickeln statt zu zittern oder aufzublitzen. Zusammen erlauben diese Module dem System, jedes Bild aufzuhellen und zu säubern, während Identität und Bewegung der Person über das gesamte Video stabil bleiben.
Das Modell schrittweise lehren
Um den großen vortrainierten Generator bestmöglich zu nutzen, ohne das bereits Gelernte zu stören, trainieren die Autorinnen und Autoren DL-Diff in drei Schritten. Zuerst lehren sie das Restoration-Modul, einzelne dunkle Bilder zu korrigieren, während der Rest des Netzes eingefroren bleibt. Als Nächstes trainieren sie das Temporal-Modul auf sauberen, normal beleuchteten Videos, damit es lernen kann, wie sich natürliche Bewegung verhält, ohne von Low-Light-Artefakten verwirrt zu werden. Schließlich fine-tunen sie beide Module gemeinsam auf gepaarten dunklen und hellen Videos. Dieser lehrplanartige Prozess verringert die Lücke zwischen Standbildern und Bewegtbildern und hilft dem System, auch dann stabil zu bleiben, wenn die Eingabe extrem verrauscht oder nahezu schwarz ist.

Scharfere, natürlicher wirkende Gesichter in der Dunkelheit
An zwei öffentlichen Datensätzen echter Low-Light-Videos liefert DL-Diff klarere Gesichter mit natürlicheren Farben als mehrere führende Methoden, und das mit weniger sichtbarem Flackern über die Zeit. Menschlich ausgerichtete Qualitätsmaße bevorzugen DL-Diff, obwohl einige ältere Techniken bei strenger pixelgenauer Genauigkeit geringfügig besser abschneiden. Dieser Kompromiss spiegelt eine Designentscheidung wider: Die neue Methode betont, was für einen Betrachter richtig aussieht, statt jedes Pixel exakt zu treffen. Der Hauptnachteil ist die Geschwindigkeit — da Diffusionsmodelle jedes Bild über viele Schritte verfeinern, ist die Verarbeitung langsamer als bei einfacheren Ansätzen — doch die Autorinnen und Autoren verweisen darauf, dass neuere, schnellere Varianten dies zukünftig erleichtern könnten. Insgesamt zeigt DL-Diff, dass moderne generative Modelle, wenn sie sorgfältig angepasst werden, fast unbrauchbare dunkle Gesichtsaufnahmen in helle, stabile Aufnahmen verwandeln können, die sich für Überwachung, Fotografie und andere reale Anwendungen eignen.
Zitation: Ding, X., He, K., Sun, H. et al. Temporally consistent low-light face video enhancement via video-to-video conditional diffusion. Sci Rep 16, 14097 (2026). https://doi.org/10.1038/s41598-026-44219-8
Schlüsselwörter: Low-Light-Video, Gesichtsverbesserung, Diffusionsmodelle, Videorestauration, zeitliche Konsistenz