Clear Sky Science · fr
Amélioration temporellement cohérente de vidéos de visages en faible luminosité via diffusion conditionnelle vidéo-à-vidéo
Faire ressortir les visages de l’obscurité
Quiconque a essayé de filmer une personne de nuit sait que le résultat peut être trouble et granuleux : les visages se perdent dans les ombres, les couleurs sont déformées et les détails scintillent d’une image à l’autre. Cet article présente DL-Diff, une nouvelle méthode d’intelligence artificielle qui transforme ces vidéos de visages sombres et bruitées en séquences lumineuses et naturelles, jouant de manière fluide sans le scintillement et les artefacts gênants qui affectent souvent les techniques précédentes. Ce travail importe pour la photographie quotidienne, les caméras de sécurité domestique et même les systèmes d’assistance à la conduite qui doivent reconnaître des personnes en faible éclairage.
Pourquoi les vidéos nocturnes sont si difficiles
Les vidéos de visages en faible luminosité posent un double défi. D’une part, chaque image est altérée par un bruit important, des dérives de couleur et des détails perdus parce que très peu de photons atteignent le capteur de la caméra. D’autre part, une vidéo n’est pas qu’un empilement d’images : nos yeux sont très sensibles aux sauts de luminosité ou de forme d’une image à l’autre. De nombreuses méthodes existantes traitent chaque image séparément ou reposent sur des estimations grossières du mouvement entre les images. Cela peut aider un peu, mais laisse souvent des scintillements ou des visages déformés, en particulier lorsque la scène est extrêmement sombre et le mouvement complexe.
Un nouveau pipeline du sombre vers la lumière
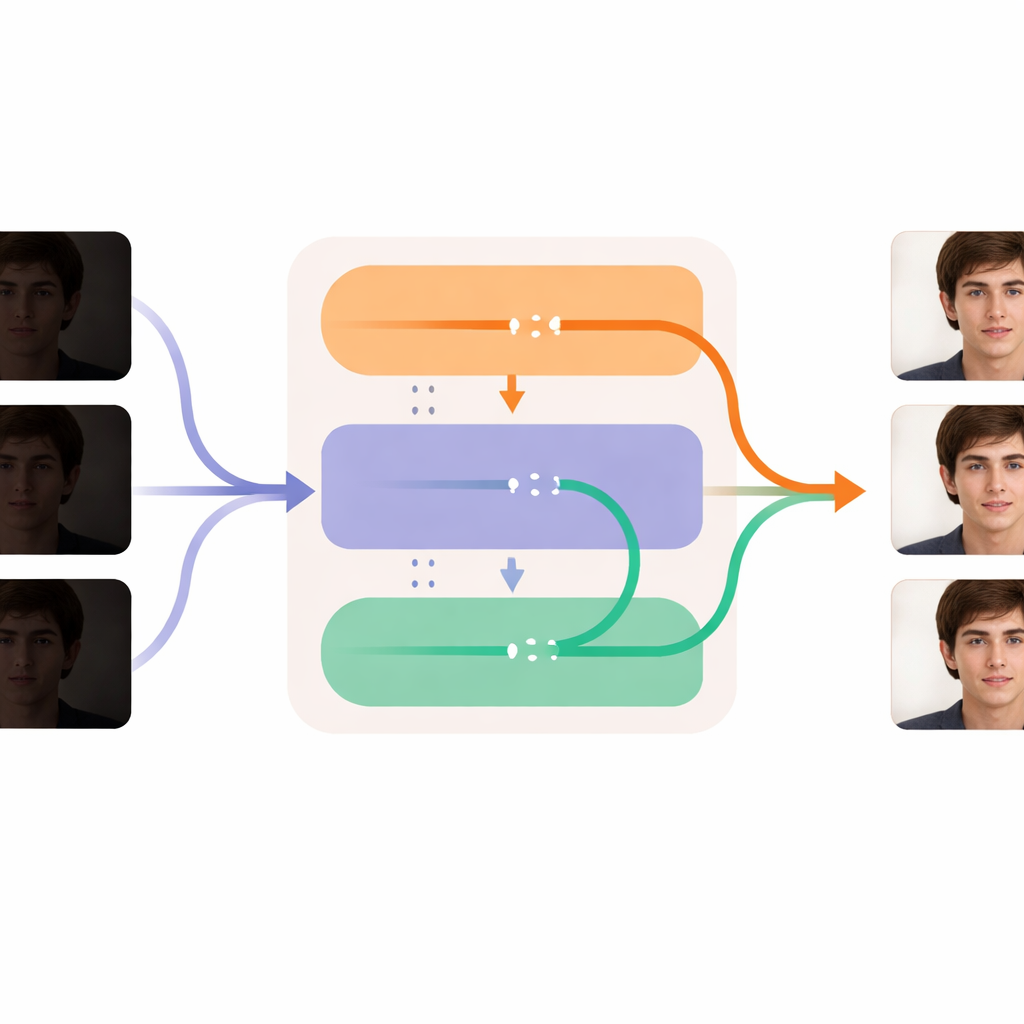
DL-Diff aborde le problème en considérant l’amélioration en faible luminosité comme une transformation complète vidéo-à-vidéo au lieu d’une retouche image par image. Il s’appuie sur de puissants générateurs « diffusion » initialement entraînés pour créer des images et de courtes vidéos à partir d’invites textuelles. Ces générateurs fonctionnent en partant d’un bruit aléatoire et en le raffinant progressivement jusqu’à obtenir une image propre. DL-Diff réaffecte un tel modèle de sorte que, au lieu de suivre une description textuelle, le générateur soit guidé par la vidéo sombre d’entrée. En opérant dans une représentation interne compacte plutôt que directement sur les pixels, le système peut éliminer le bruit et halluciner les détails manquants tout en respectant le contenu général des images d’origine.
Aiguiser chaque image tout en gardant une temporalité fluide
Le cœur de DL-Diff se divise en deux modules coopératifs qui reflètent la façon dont nous percevons la vidéo. La partie « restauration » se concentre sur l’espace : elle examine chaque image et injecte des détails supplémentaires, de la texture et des couleurs plus réalistes dans les couches internes du générateur, compensant ce qui a été perdu dans l’obscurité. Ce module est d’abord entraîné sur des paires d’images individuelles, apprenant à quoi doit ressembler un visage sombre une fois correctement éclairé. La partie « temporelle » se concentre sur le temps : elle reconfigure le modèle pour que, à des étapes clés du traitement, il puisse comparer les informations entre images et les réaligner en douceur. Cela aide les expressions, les mouvements de tête et les variations d’éclairage à évoluer de manière fluide d’une image à l’autre au lieu de trembler ou d’apparaître brusquement. Ensemble, ces modules permettent d’éclaircir et de nettoyer chaque image tout en conservant l’identité et les mouvements de la personne stables sur l’ensemble de la vidéo.
Former le modèle par étapes
Pour tirer le meilleur parti du grand générateur pré-entraîné sans perturber ce qu’il a déjà appris, les auteurs entraînent DL-Diff en trois étapes. D’abord, ils apprennent au module de restauration à corriger des images sombres individuelles tandis que le reste du réseau reste figé. Ensuite, ils entraînent le module temporel sur des vidéos propres et normalement éclairées afin qu’il apprenne comment le mouvement naturel se comporte sans être perturbé par les artefacts de faible luminosité. Enfin, ils affinent les deux modules ensemble sur des vidéos appariées sombres et lumineuses. Ce processus de type « curriculum » réduit l’écart entre images fixes et séquences animées et aide le système à rester stable même lorsque l’entrée est extrêmement bruyante ou quasi noire.

Des visages plus nets et plus naturels dans l’obscurité
Sur deux jeux de données publics de vidéos réelles en faible luminosité, DL-Diff produit des visages plus nets avec des couleurs plus naturelles que plusieurs méthodes de pointe, et le fait avec moins de scintillement visible au fil du temps. Des mesures de qualité visuelle alignées sur la perception humaine favorisent DL-Diff, même si certaines techniques plus anciennes obtiennent des scores légèrement meilleurs sur la précision stricte pixel par pixel. Ce compromis reflète un choix de conception : la nouvelle méthode privilégie ce qui semble juste pour un spectateur plutôt que de correspondre exactement à chaque pixel. Le principal inconvénient est la vitesse — parce que les modèles de diffusion affinent chaque image via de nombreuses étapes, le traitement est plus lent que des approches plus simples — mais les auteurs notent que des variantes plus récentes et plus rapides pourraient atténuer ce point à l’avenir. Dans l’ensemble, DL-Diff montre que les modèles génératifs modernes, correctement adaptés, peuvent transformer des vidéos de visages presque inutilisables en séquences lumineuses et stables, adaptées à la surveillance, la photographie et d’autres applications réelles.
Citation: Ding, X., He, K., Sun, H. et al. Temporally consistent low-light face video enhancement via video-to-video conditional diffusion. Sci Rep 16, 14097 (2026). https://doi.org/10.1038/s41598-026-44219-8
Mots-clés: vidéo en faible luminosité, amélioration de visages, modèles de diffusion, restauration vidéo, cohérence temporelle