Clear Sky Science · zh
通过视觉 Mamba 与大型语言模型实现交互式文本引导图像分割
教计算机看懂我们所描述的内容
想象一下指着一张繁忙的照片说:“门边穿红色外套的那位女士”,然后计算机立即将那个人精确地描边到像素级。本论文探讨如何使这种细粒度、以语言驱动的图像编辑变得快速、准确且可交互。通过融合最新的语言模型进展和一种名为“Mamba”的新型视觉网络,作者展示了机器如何更好地将我们的文字与图像中我们关心的精确区域匹配起来。
为什么文字与图像难以匹配
让计算机将一个对象从背景中分离出来本身就是挑战;要求它们根据日常语言来完成这项任务则更为困难。像“椅子后面较小的那只狗”这样的短语同时包含外观、尺寸和空间关系。传统系统要么分别处理文本和图像特征,要么以简单方式将二者结合,当描述变长或更为微妙时常常会失败。它们可能找错目标、模糊边界,或者在针对密集像素级任务训练时变得不稳定。关键难点在于跨模态对齐:把句子中灵活的、高层次的语义与图像中精确的、低层次的细节连接起来。
文本与图像之间的双向对话
作者提出了一种 H 形的“双向对齐”网络,将文本和图像视为平等的合作伙伴,而不是仅仅把文本当作单向指令处理。一个分支专注于主要任务:给定图像和描述,生成高亮目标区域的概率图。另一个分支则反向运行:尝试推断句子中哪些词对所选区域最重要。两个分支共享一组紧凑的学习“查询”向量,这些向量将最相关的视觉和文本线索拉到一个共同空间。一个特殊的一致性损失促使系统保持它突出显示的像素与它认为重要的词之间的一致性。这种双向监督有助于防止模型陷入虚假相关,并使其行为更易解释。
更快的视觉引擎与更聪明的语言大脑
在系统内部,视觉部分由 Vision Mamba 提供动力,这是一种基于状态空间的架构,旨在高效处理大尺度、高分辨率图像。与依赖标准 Transformer 的高开销二次计算不同,Vision Mamba 以随图像尺寸线性增长的方式建模长程关系。它还混入轻量级卷积以锐化边缘和细节,这在描绘对象轮廓时至关重要。文本方面,系统使用了 Qwen 的紧凑变体。为了保留广泛的语言理解能力,大多数层保持冻结,仅对顶层进行轻微微调,使模型在像“从左数第二个人”这样的指称短语上表现得尤其好而不过拟合。一个小型融合模块随后使用共享查询来对齐图像补丁与词元,并通过调制机制基于文本微妙地增强或抑制视觉通道,将抽象句子转化为具体的像素级指引。
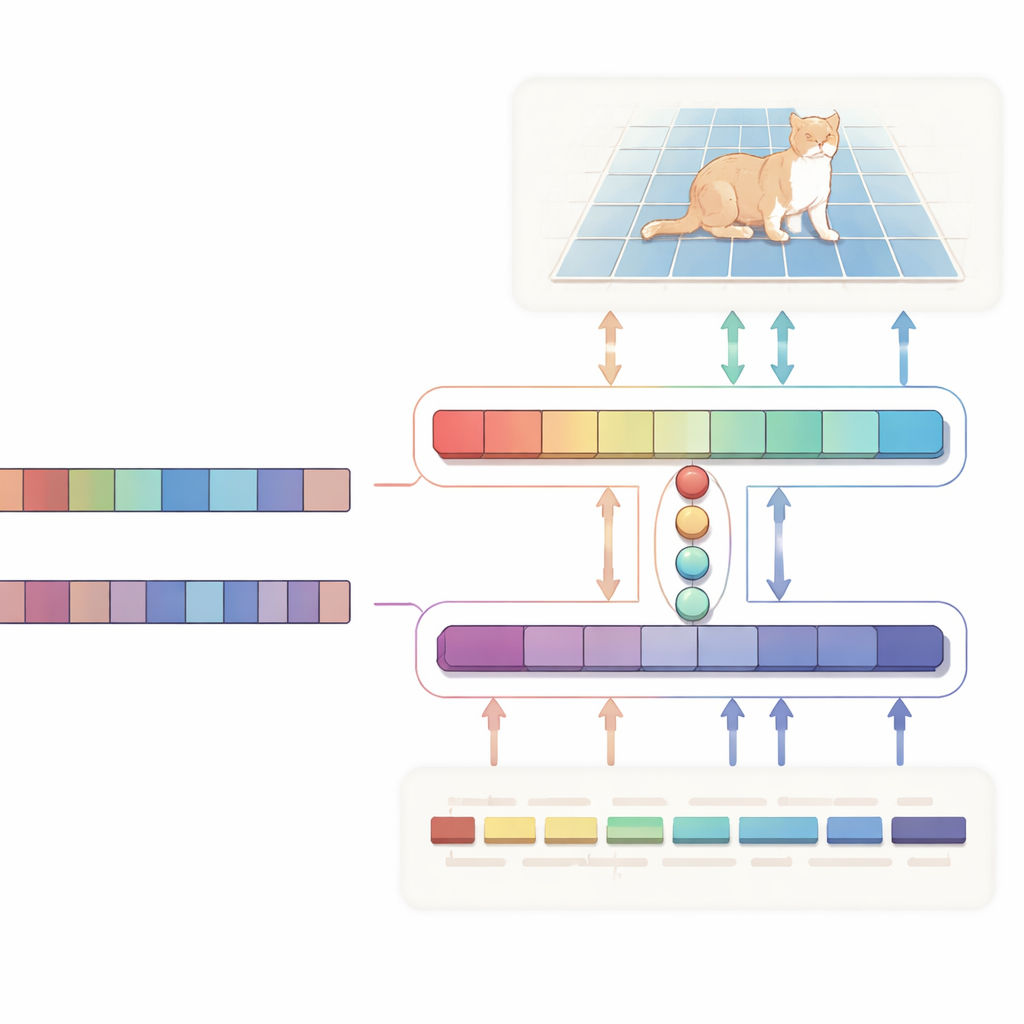
更准确的掩膜、更少的计算量
为检验其设计,作者在三个广泛使用的基准数据集——RefCOCO、RefCOCO+ 和 RefCOCOg——上进行了评估,这些数据集包含数万张真实世界图像及其针对特定对象的自然语言描述。在这些数据集上,他们的方法在交并比(IoU)得分上持续优于许多知名竞争方法,包括基于 Transformer 的模型和受 Segment Anything 框架启发的系统。细致的消融实验表明每个组成部分都很重要:将 Vision Mamba 换成传统主干网络、用更简单的文本编码器替换 Qwen,或移除基于查询的交叉注意力,都会降低精度。与此同时,Vision Mamba 的线性时间设计使浮点运算量相比强大的 Transformer 基线大约减少一半,并将每秒处理帧数提高超过两倍,使该方法更适合实时交互使用。
让人机协作更进一步
对非专业人士而言,主要结论是这项工作让人们更容易用自然语言“与图像对话”并获得精确、可控的结果。通过让文本和图像互相监督,并基于高效的视觉与语言引擎构建,系统可以快速定位用户意图,并在仅需几次点击的情况下细化轮廓。这种速度、准确性与透明性的结合对照片编辑、机器人技术、无障碍工具以及任何需要人类与人工智能使用日常语言共同处理视觉任务的场景都有明确的意义。
引用: Meng, Y., Sun, H. & Jiang, W. Interactive text-guided image segmentation via vision Mamba and large language models. Sci Rep 16, 14061 (2026). https://doi.org/10.1038/s41598-026-43841-w
关键词: 文本引导图像分割, 视觉 Mamba, 大型语言模型, 多模态对齐, 交互式视觉