Clear Sky Science · he
סגמנטציה אינטראקטיבית של תמונות מנוהלת טקסט בעזרת Vision Mamba ומודלי שפה גדולים
ללמד מחשבים לראות את מה שאנחנו מתארים
דמיינו שמהצבעה על צילום עמוס ואמירה "האישה במעיל האדום ליד הדלת", המחשב משרטט מיד רק את האדם הזה עד לרמת הפיקסל. המאמר חוקר כיצד לגרום לעריכה מבוססת שפה של תמונות ברזולוציה גבוהה להתרחש במהירות, בדיוק ובצורה אינטראקטיבית. באמצעות שילוב של התקדמויות חדשות במודלי שפה ורשת ראייה חדשה בשם "Mamba", המחברים מראים כיצד מכונות יכולות להתאים טוב יותר את המילים שלנו לאזורים המדויקים בתמונה שמעניינים אותנו.
למה קשה להתאים מילים לתמונות
לגרום למחשבים להפריד אובייקט מהרקע כבר מהווה אתגר; לדרוש זאת על סמך שפה יומיומית הופך את המשימה למורכבת עוד יותר. ביטויים כמו "הכלב הקטן יותר מאחורי הכיסא" כוללים יחד הופעה חזותית, גודל ויחסים מרחביים. מערכות מסורתיות הסתמכו לעתים על תכונות טקסט ותמונה באופן נפרד או שלבו אותן באופן פשוט, מה שהוביל לכישלונות כאשר התיאורים ארוכים או עדינים. הן עלולות להחמיץ את האובייקט הנכון, לטשטש גבולות, או להפוך ללא יציבות כאשר מאמנים אותן על מטלות פיקסל-אחר-פיקסל צפופות. הקושי המרכזי הוא התאמה בין-מודאלית: לחבר את המשמעויות הרמות והגמישות שבמשפטים עם הפרטים המדויקים והדקים שבתמונות.
שיחה דו-כיוונית בין טקסט לתמונה
המחברים מציעים רשת בצורת H של "תיאום דו-כיווני" שמתייחסת לטקסט ולתמונה כשותפים שווים במקום להשתמש בטקסט כהוראה חד-כיוונית. ענף אחד מתמקד במשימה הראשית: בהתחשב בתמונה ובתיאור, הוא מפיק מפה של הסתברויות המדגישה את האזור הרצוי. הענף השני פועל בכיוון ההפוך: הוא מנסה להסיק אילו מילים במשפט חשובות ביותר לאזור שנבחר. שני הענפים משתפים סט קומפקטי של וקטורי "שאלה" (query) שנלמדים, שמרכזים יחד את האיתותים הוויזואליים והטקסטואליים הרלוונטיים לחלל משותף. הפסד עקביות מיוחד מייצב את המערכת כך שהפיקסלים שהיא מדגישה והמילים שהיא מחשבת כחשובות יישארו מסונכרנים. ההשגחה הדו-כיוונית הזו עוזרת למנוע קפיצה לקורלציות מקריות ומקלה על פרשנות התנהגות המודל.
מנוע חזותי מהיר יותר עם מוח שפה חכם יותר
מתחת למכסה המנוע, הצד הוויזואלי נשען על Vision Mamba, ארכיטקטורת מבוססת סטייט-ספייס שנועדה להתמודד ביעילות עם תמונות גדולות וברזולוציה גבוהה. במקום להסתמך על חישובים ריבועיים כבדים של Transformers סטנדרטיים, Vision Mamba ממודלת יחסי מרחק ארוכים באופן שמדרג בקו ישר עם גודל התמונה. היא גם משלבת קונבולוציות קלות כדי להחדד קצוות ופרטים דקים, קריטיים בעת שרטוט גבולות אובייקטים. בצד הטקסט, המערכת משתמשת בגרסה קומפקטית של מודל השפה הגדול Qwen. רוב השכבות נשמרות קפואות כדי לשמור על הבנה לשונית רחבה, בעוד שהשכבות העליונות מתכווננות בעדינות כך שהמודל משתפר בביטויים ייחוסיים כמו "האדם השני משמאל" בלי להטוות יתר. מודול איחוי קטן משתמש לאחר מכן ב־queries המשותפים כדי ליישר פיצולי תמונה (patches) עם טוקני מילים, ומנגנון מודולציה מחזק או מדכא תעלות חזותיות בהתאמה לטקסט, מה שהופך משפטים מופשטים להנחיה קונקרטית ברמת הפיקסל.
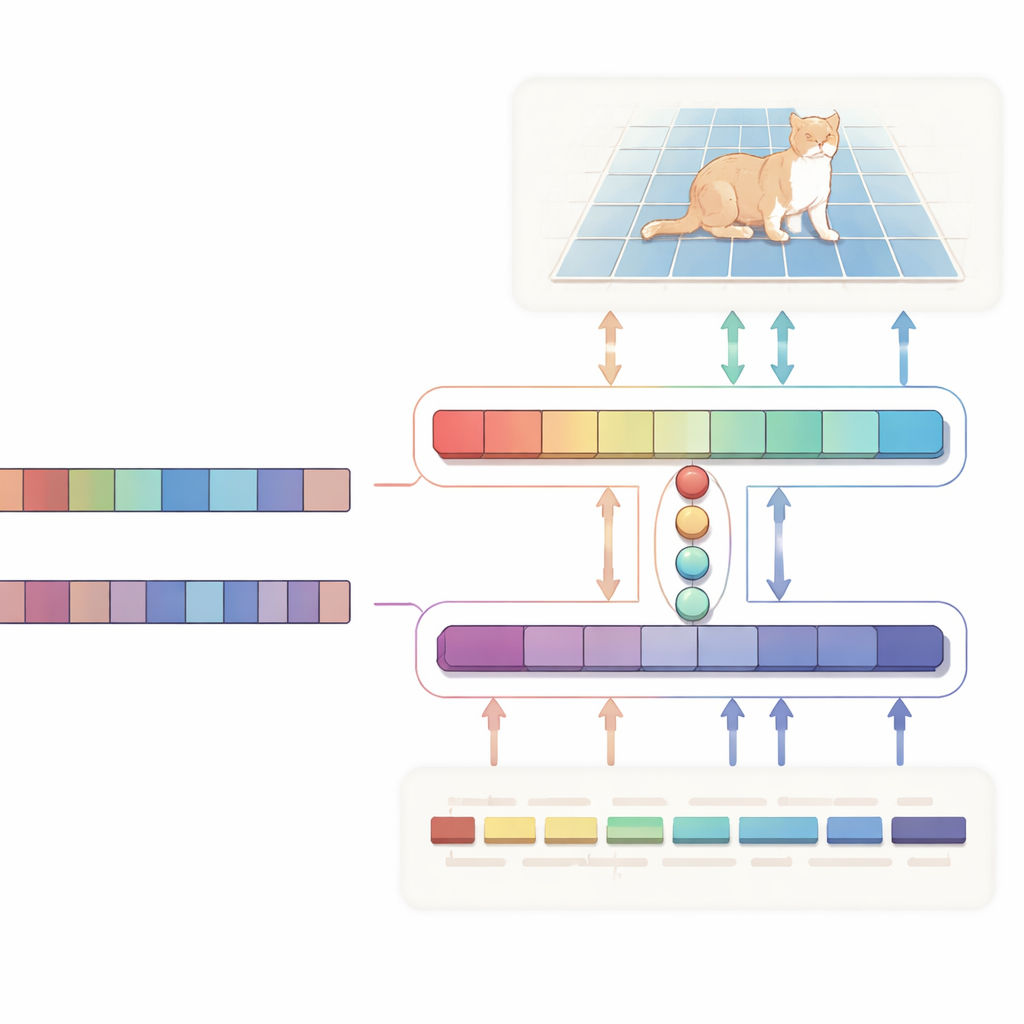
מסכות מדויקות יותר, חישוב פחות
כדי לבדוק את העיצוב שלהם, המחברים העריכו אותו על שלושה סטנדרטים נפוצים—RefCOCO, RefCOCO+ ו‑RefCOCOg—שכוללים עשרות אלפי תמונות מהעולם האמיתי עם תיאורי שפה טבעיים לאובייקטים ספציפיים. לאורך מערכי הנתונים הללו, שיטתם השיגה באופן עקבי ציוני intersection-over-union גבוהים יותר מאשר מתחרים ידועים רבים, כולל מודלים מבוססי Transformer ומערכות שהושפעו ממסגרת Segment Anything. ניסויי אבלאציה מדוקדקים מראים שכל מרכיב חשוב: החלפת Vision Mamba בעמוד שדרה קונבנציונלי, החלפת Qwen בקודד טקסט פשוט יותר, או הסרת תשומת-לב חוצת-שאלות מורידה את הדיוק. במקביל, העיצוב בקו ישר של Vision Mamba חותך בכמות הפעולות הנעות בנקודה הצפה בכמעט חצי בהשוואה לבסיס Transformer חזק ומכפיל יותר משם את קצב המסגרות לעומת זמן, מה שהופך את הגישה מתאימה יותר לשימוש אינטראקטיבי בזמן אמת.
להקרב את שיתוף הפעולה בין אדם ל-AI
עבור לא-מומחים, המסקנה המרכזית היא שהעבודה מקלה על אנשים "לדבר" עם תמונות בשפה טבעית ולקבל תוצאות מדויקות ושליטות. על ידי כך שטקסט ותמונה מפקחים זה על זה ובנייתה על מנועי ראייה ושפה יעילים, המערכת יכולה במהירות להתמקד בדיוק במה שהמשתמש מתכוון אליו ולשכלל את הקו ההיקפי בכמה קליקים בלבד. השילוב של מהירות, דיוק ושקיפות יש לו השלכות ברורות על עריכת תמונות, רובוטיקה, כלים להנגשה, וכל סביבה שבה בני אדם ו‑AI צריכים לעבוד יחד על משימות חזותיות באמצעות שפה יום-יומית.
ציטוט: Meng, Y., Sun, H. & Jiang, W. Interactive text-guided image segmentation via vision Mamba and large language models. Sci Rep 16, 14061 (2026). https://doi.org/10.1038/s41598-026-43841-w
מילות מפתח: סגמנטציה של תמונה מנוהלת טקסט, vision mamba, מודלים גדולים של שפה, תיאום מולטימודלי, ראייה אינטראקטיבית