Clear Sky Science · es
Segmentación interactiva de imágenes guiada por texto mediante Vision Mamba y grandes modelos de lenguaje
Enseñar a los ordenadores a ver lo que describimos
Imagínese señalando una fotografía concurrida y diciendo: «la mujer con el abrigo rojo junto a la puerta», y que un ordenador delimite al instante solo a esa persona hasta el nivel de píxel. Este artículo explora cómo hacer que ese tipo de edición de imagen, impulsada por el lenguaje, sea rápida, precisa e interactiva. Al combinar avances recientes en modelos de lenguaje y un nuevo tipo de red visual llamada “Mamba”, los autores muestran cómo las máquinas pueden emparejar mejor nuestras palabras con las regiones exactas que nos interesan en una imagen.
Por qué es difícil casar palabras y imágenes
Conseguir que los ordenadores separen un objeto del fondo ya es un reto; pedirles que lo hagan a partir de lenguaje cotidiano lo complica aún más. Frases como «el perro más pequeño detrás de la silla» condensan apariencia, tamaño y relaciones espaciales a la vez. Los sistemas tradicionales o bien analizaban las características de texto e imagen por separado o las combinaban de maneras sencillas, lo que a menudo fallaba cuando las descripciones se volvían largas o sutiles. Podrían pasar por alto el objeto correcto, difuminar los bordes o volverse inestables al entrenarse en tareas densas píxel a píxel. La dificultad clave es la alineación cross-modal: conectar el significado flexible y de alto nivel de las frases con los detalles precisos y de bajo nivel de las imágenes.
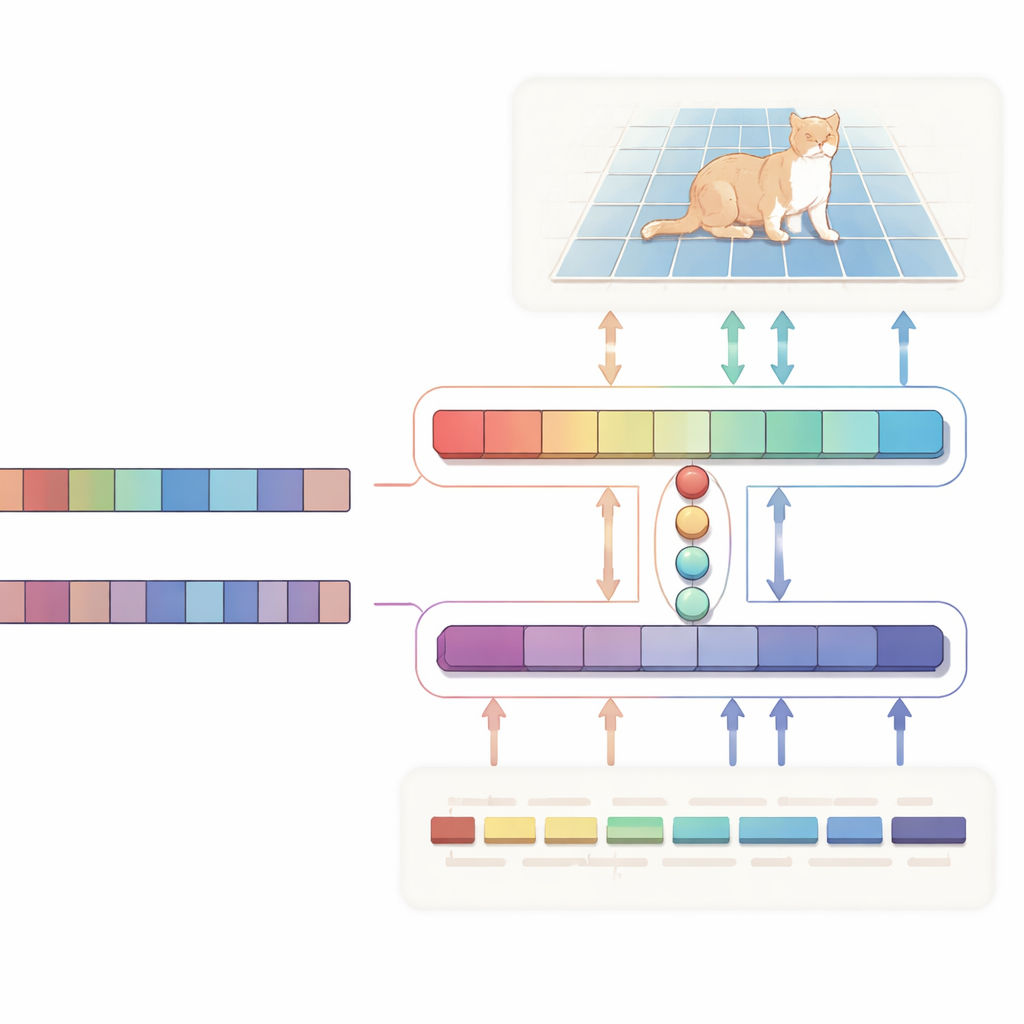
Una conversación bidireccional entre texto e imagen
Los autores proponen una red en forma de H de “alineación bidireccional” que trata el texto y la imagen como socios iguales en lugar de usar el texto como una instrucción unidireccional. Una rama se centra en la tarea principal: dada una imagen y una descripción, produce un mapa de probabilidad que resalta la región objetivo. La otra rama funciona en la dirección opuesta: intenta inferir qué palabras de la frase son las más relevantes para la región seleccionada. Ambas ramas comparten un conjunto compacto de vectores de “consulta” aprendidos que reúnen las señales visuales y textuales más relevantes en un espacio común. Una pérdida de consistencia especial empuja al sistema para que los píxeles que resalta y las palabras que considera importantes permanezcan en acuerdo. Esta supervisión bidireccional ayuda a evitar que el modelo derive en correlaciones espurias y hace su comportamiento más fácil de interpretar.
Un motor visual más rápido con un cerebro de lenguaje más inteligente
En el interior, el lado visual está impulsado por Vision Mamba, una arquitectura basada en estado-espacio diseñada para manejar de manera eficiente imágenes grandes y de alta resolución. En lugar de depender de los costosos cálculos cuadráticos de los Transformers estándar, Vision Mamba modela las relaciones a larga distancia de una forma que escala linealmente con el tamaño de la imagen. También incorpora convoluciones ligeras para afinar bordes y detalles finos, cruciales al delinear objetos. En el lado textual, el sistema usa una variante compacta del gran modelo de lenguaje Qwen. La mayoría de sus capas se mantienen congeladas para preservar una comprensión lingüística amplia, mientras que solo las capas superiores se afinan ligeramente para que el modelo mejore en frases referenciales como «la segunda persona por la izquierda» sin sobreajustarse. Un pequeño módulo de fusión emplea luego las consultas compartidas para alinear parches de imagen y tokens de palabras, y un mecanismo de modulación refuerza o suprime sutilmente canales visuales según el texto, transformando frases abstractas en orientación concreta a nivel de píxel.
Más máscaras precisas, menos cómputo
Para evaluar su diseño, los autores lo probaron en tres benchmarks muy usados—RefCOCO, RefCOCO+ y RefCOCOg—que contienen decenas de miles de imágenes del mundo real emparejadas con descripciones en lenguaje natural de objetos concretos. En estos conjuntos de datos, su método consiguió de manera consistente puntuaciones de intersección sobre unión más altas que muchos competidores conocidos, incluidos modelos basados en Transformers y sistemas inspirados en el marco Segment Anything. Experimentos de ablación cuidadosos muestran que cada ingrediente importa: sustituir Vision Mamba por una columna vertebral convencional, reemplazar Qwen con un codificador de texto más simple, o eliminar la atención cruzada basada en consultas reduce la precisión. Al mismo tiempo, el diseño de tiempo lineal de Vision Mamba reduce las operaciones de punto flotante aproximadamente a la mitad frente a una sólida línea base Transformer y más que duplica el número de fotogramas procesados por segundo, haciendo el enfoque más adecuado para uso interactivo en tiempo real.
Acercando la colaboración humano–IA
Para los no especialistas, la conclusión principal es que este trabajo facilita que las personas «hablen» con las imágenes en lenguaje natural y obtengan resultados precisos y controlables. Al permitir que texto e imagen se supervisen mutuamente y al apoyarse en motores de visión y lenguaje eficientes, el sistema puede localizar rápidamente lo que el usuario quiere y refinar el contorno con solo unos pocos clics. Esa combinación de velocidad, precisión y transparencia tiene claras implicaciones para la edición fotográfica, la robótica, herramientas de accesibilidad y cualquier contexto donde humanos e IA necesiten colaborar en tareas visuales usando lenguaje cotidiano.
Cita: Meng, Y., Sun, H. & Jiang, W. Interactive text-guided image segmentation via vision Mamba and large language models. Sci Rep 16, 14061 (2026). https://doi.org/10.1038/s41598-026-43841-w
Palabras clave: segmentación de imágenes guiada por texto, vision mamba, grandes modelos de lenguaje, alineación multimodal, visión interactiva