Clear Sky Science · nl
Interactieve tekstaandegeleide beeldsegmentatie via Vision Mamba en grote taalmodellen
Computers leren zien wat we beschrijven
Stel je voor dat je naar een drukke foto wijst en zegt: “de vrouw in de rode jas bij de deur,” en dat een computer vervolgens direct die persoon tot op pixelniveau omlijnt. Dit artikel onderzoekt hoe je dat soort fijnmazige, door taal aangestuurde bewerking van beelden snel, nauwkeurig en interactief kunt maken. Door recente vorderingen in taalmodellen te combineren met een nieuw type visueel netwerk genaamd “Mamba”, laten de auteurs zien hoe machines onze woorden beter kunnen koppelen aan precies die regio’s in een afbeelding waar het ons om gaat.
Waarom woorden en beelden moeilijk te matchen zijn
Het is al een uitdaging voor computers om een object van de achtergrond te scheiden; ze dat laten doen op basis van alledaagse taal maakt het nog moeilijker. Zinnen als “de kleinere hond achter de stoel” bevatten tegelijk informatie over uiterlijk, grootte en ruimtelijke relaties. Traditionele systemen bekeken tekst- en afbeeldingskenmerken vaak apart of combineerden ze op eenvoudige manieren, wat vaak faalde wanneer beschrijvingen lang of subtiel werden. Ze misten mogelijk het juiste object, vervaagden randen of werden instabiel bij training op dicht opeenvolgende pixelopdrachten. De kern van het probleem is cross-modale uitlijning: het verbinden van de flexibele, hoog-niveau betekenis in zinnen met de precieze, laag-niveau details in afbeeldingen.
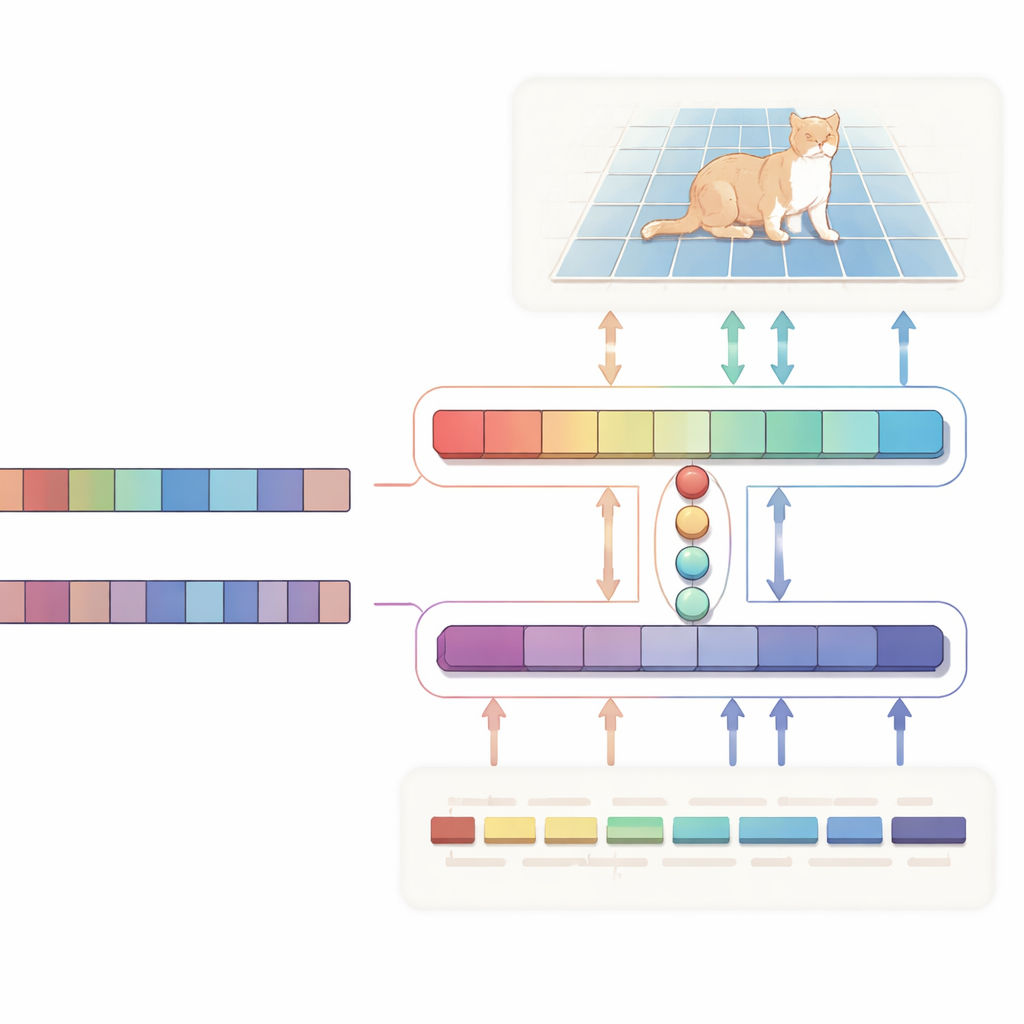
Een tweerichtingsgesprek tussen tekst en beeld
De auteurs stellen een H-vormig “bidirectioneel uitlijnings”netwerk voor dat tekst en beeld als gelijke partners behandelt in plaats van tekst alleen als eenrichtingsinstructie te gebruiken. De ene tak richt zich op de hoofdtaak: gegeven een afbeelding en een beschrijving produceert deze een waarschijnlijkheidskaart die de doelregio markeert. De andere tak werkt in de tegenovergestelde richting: die probeert te achterhalen welke woorden in de zin het belangrijkst zijn voor de gekozen regio. Beide takken delen een compacte set geleerde “query”-vectoren die de meest relevante visuele en tekstuele signalen samenbrengen in een gemeenschappelijke ruimte. Een speciale consistentieverliesfunctie dwingt het systeem ertoe dat de pixels die het benadrukt en de woorden die het belangrijk vindt in overeenstemming blijven. Deze tweerichtingssupervisie helpt voorkomen dat het model in willekeurige correlaties wegdrijft en maakt het gedrag beter te interpreteren.
Een snellere visuele motor met een slimmer taalbrein
Onder de motorkap wordt de visuele zijde aangedreven door Vision Mamba, een architectuur gebaseerd op state-space die is ontworpen om grote, hoogresolutie afbeeldingen efficiënt te verwerken. In plaats van te vertrouwen op de zware, kwadratische berekeningen van standaard Transformers, modelleert Vision Mamba langafstandrelaties op een manier die lineair schaalt met de beeldgrootte. Het mengt ook lichte convoluties om randen en fijne details aan te scherpen, wat cruciaal is bij het omlijnen van objecten. Aan de tekstzijde gebruikt het systeem een compacte variant van het Qwen-grote taalmodel. Het merendeel van de lagen blijft bevroren om brede taalbegrip te behouden, terwijl alleen de bovenste lagen voorzichtig worden fijn afgesteld zodat het model bijzonder goed wordt in referentiële uitdrukkingen zoals “de tweede persoon van links” zonder te overfitten. Een kleine fusiemodule gebruikt vervolgens de gedeelde queries om beeldpatches en woordtokens uit te lijnen, en een modulatiemechanisme versterkt of dempt subtiel visuele kanalen op basis van de tekst, waardoor abstracte zinnen in concrete, pixelniveau-aanwijzingen worden omgezet.
Meer nauwkeurige maskers, minder rekenkracht
Om hun ontwerp te testen evalueerden de auteurs het op drie veelgebruikte benchmarks — RefCOCO, RefCOCO+ en RefCOCOg — die tienduizenden real-world afbeeldingen bevatten gekoppeld aan natuurtalige beschrijvingen van specifieke objecten. Over deze datasets heen behaalde hun methode consequent hogere intersection-over-union-scores dan veel bekende concurrenten, waaronder op Transformers gebaseerde modellen en systemen geïnspireerd door het Segment Anything-framework. Zorgvuldig uitgevoerde ablatietests laten zien dat elk ingrediënt telt: het vervangen van Vision Mamba door een conventionele backbone, het vervangen van Qwen door een eenvoudiger tekstencoder, of het weglaten van de query-gebaseerde cross-attention verlaagt allemaal de nauwkeurigheid. Tegelijkertijd halveert het lineaire ontwerp van Vision Mamba ruwweg het aantal floating-point-bewerkingen vergeleken met een sterke Transformer-baseline en verdubbelt het meer dan het aantal frames dat per seconde verwerkt wordt, waardoor de aanpak beter geschikt is voor real-time, interactieve toepassingen.
Mensen–AI-samenwerking dichterbij brengen
Voor niet-specialisten is de belangrijkste conclusie dat dit werk het eenvoudiger maakt voor mensen om in natuurlijke taal met beelden te “praten” en precieze, bestuurbare resultaten te krijgen. Door tekst en beeld elkaar te laten superviseren en te bouwen op efficiënte visuele en taalmotoren kan het systeem snel uitkomen bij precies wat een gebruiker bedoelt en de omlijning met slechts een paar klikken verfijnen. Die combinatie van snelheid, nauwkeurigheid en transparantie heeft duidelijke implicaties voor fotobewerking, robotica, toegankelijkheidstools en elke situatie waarin mensen en AI met alledaagse taal samen aan visuele taken moeten werken.
Bronvermelding: Meng, Y., Sun, H. & Jiang, W. Interactive text-guided image segmentation via vision Mamba and large language models. Sci Rep 16, 14061 (2026). https://doi.org/10.1038/s41598-026-43841-w
Trefwoorden: tekstaandegeleide beeldsegmentatie, vision mamba, grote taalmodellen, multimodale uitlijning, interactief zicht