Clear Sky Science · ar
تقسيم الصور التفاعلي الموجَّه بالنص عبر فيجن مامبا ونماذج اللغة الكبيرة
تعليم الحواسيب رؤية ما نصفه
تخيل الإشارة إلى صورة مزدحمة وقول «المرأة ذات المعطف الأحمر بجانب الباب»، ثم يحدد الحاسوب ذلك الشخص بدقة حتى على مستوى البكسل. تستكشف هذه الورقة كيفية جعل هذا النوع من التحرير المرئي الدقيق المعتمد على اللغة سريعًا ودقيقًا وتفاعليًا. من خلال مزج التقدّمات الحديثة في نماذج اللغة مع نوع جديد من شبكات الرؤية يُدعى «مامبا»، يوضح المؤلفون كيف يمكن للآلات أن تطابق كلماتنا بشكل أفضل مع المناطق الدقيقة التي نهتم بها في الصورة.
لماذا من الصعب مطابقة الكلمات بالصور
تفكيك الحاسوب لكائن واحد من الخلفية تحديًا قائمًا بحد ذاته؛ وإطالبة ذلك بالاستناد إلى لغة يومية يجعل المهمة أصعب. عبارات مثل «الكلب الأصغر خلف الكرسي» تجمع بين المظهر والحجم والعلاقات المكانية في آن واحد. الأنظمة التقليدية كانت تنظر إلى ميزات النص والصورة بشكل منفصل أو تدمجهما بطرق بسيطة، وغالبًا ما تفشل حين تصبح الأوصاف طويلة أو دقيقة. قد تخطئ في تحديد الكائن الصحيح، أو تمحو الحدود، أو تصبح غير مستقرة عند التدريب على مهام كثيفة على مستوى البكسل. الصعوبة الأساسية هي المحاذاة عبر الوسائط: ربط المعنى المرن عالي المستوى في الجمل بالتفاصيل الدقيقة منخفضة المستوى في الصور.
حوار ذهابًا وإيابًا بين النص والصورة
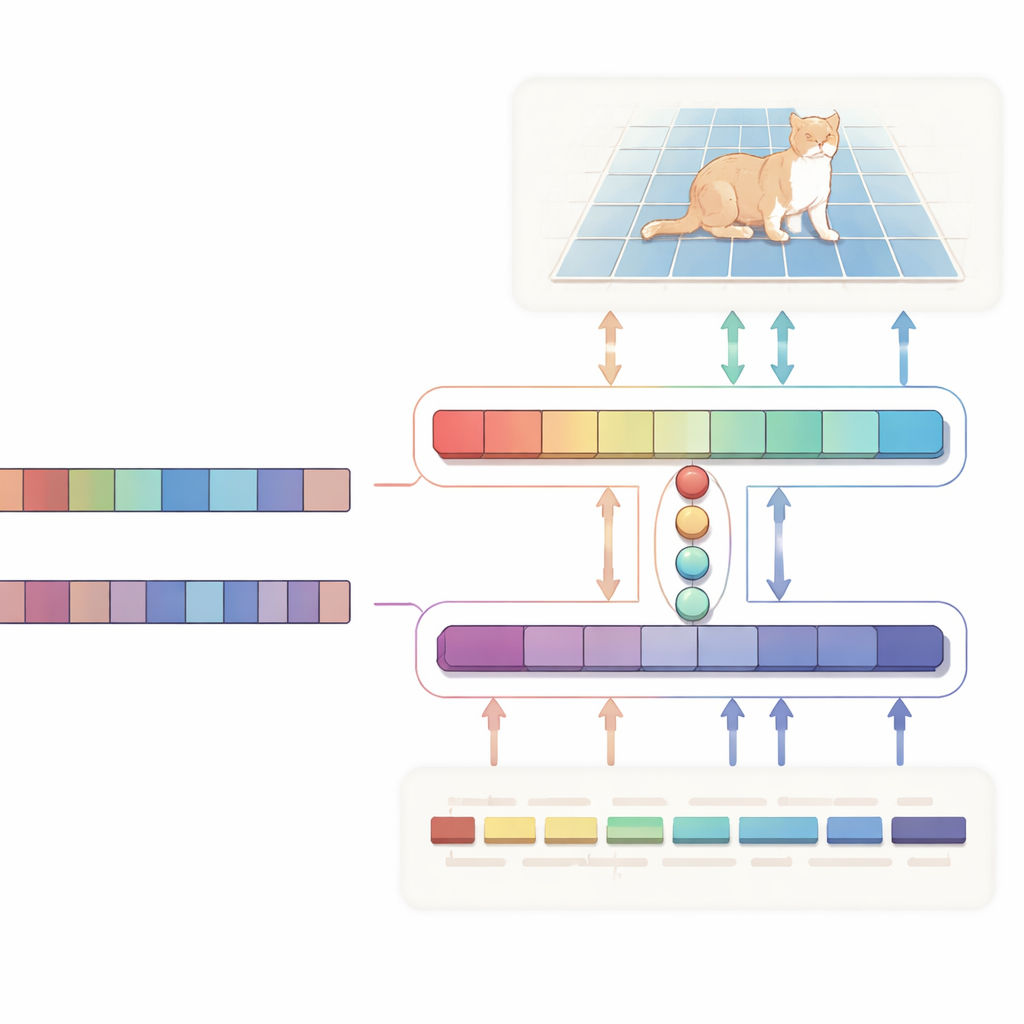
يقترح المؤلفون شبكة «محاذاة ثنائية الاتجاه» على شكل حرف H تعامل النص والصورة كشريكين متكافئين بدلاً من استخدام النص كتعليمات من اتجاه واحد فقط. يركز أحد الفروع على المهمة الرئيسية: إعطاء صورة ووصف، ينتج خريطة احتمالية تُبرز المنطقة المستهدفة. الفرع الآخر يعمل في الاتجاه المعاكس: يحاول استنتاج أي الكلمات في الجملة هي الأهم بالنسبة للمنطقة المختارة. يتشارك الفرعان مجموعة مدمجة من متجهات «الاستعلام» المتعلمة التي تجمع الإشارات البصرية واللفظية الأكثر صلة في فضاء مشترك. خسارة اتساق خاصة تُوجه النظام بحيث تبقى البكسلات التي يبرزها والكلمات التي يعتبرها مهمة متوافقة. هذه الإشراف الثنائي يساعد على منع النموذج من الانحراف إلى ارتباطات عشوائية ويجعل سلوكه أسهل في التفسير.
محرك بصري أسرع ودماغ لغوي أذكى
في العمق، الجانب البصري مدعوم بفيجن مامبا، بنية قائمة على حالة-المجال مصممة للتعامل مع صور كبيرة وعالية الدقة بكفاءة. بدلًا من الاعتماد على الحسابات المكعبة الثقيلة للمحولات التقليدية،Modeling علاقات المدى الطويل في فيجن مامبا يتم بطريقة تتدرج خطيًا مع حجم الصورة. كما تمزج أيضًا التلافيف الخفيفة لشحذ الحواف والتفاصيل الدقيقة، وهي أمور حيوية عند تحديد محيط الكائنات. وعلى جانب النص، يستخدم النظام نسخة مدمجة من نموذج اللغة الكبير Qwen. تُجمَد معظم طبقاتها للحفاظ على فهم لغوي واسع، بينما تُعدَّل فقط الطبقات العليا برفق حتى يصبح النموذج جيدًا بشكل خاص في العبارات الإشارية مثل «الشخص الثاني من اليسار» دون الإفراط في التخصيص. ثم يستخدم وحدة دمج صغيرة الاستعلامات المشتركة لمواءمة قطع الصورة ووحدات كلمات النص، وآلية تعديل ترفع أو تقلل قنوات بصرية بناءً على النص، محولة الجمل المجردة إلى إرشاد ملموس على مستوى البكسل.
أقنعة أكثر دقة وحساب أقل
لاختبار التصميم، قيّم المؤلفون النظام على ثلاث مجموعات مرجعية مستخدمة على نطاق واسع—RefCOCO وRefCOCO+ وRefCOCOg—التي تحتوي على عشرات الآلاف من الصور الواقعية المقرونة بأوصاف لغة طبيعية لأجسام محددة. عبر هذه المجموعات، حقق أسلوبهم باستمرار درجات تقاطع-على-اتحاد أعلى من العديد من المنافسين المعروفين، بما في ذلك النماذج المبنية على المحول وأنظمة مستوحاة من إطار Segment Anything. تُظهر تجارب الإبطال الدقيقة أن كل مكوّن مهم: استبدال فيجن مامبا بهيكل أساسي تقليدي، أو استبدال Qwen بترميز نصي أبسط، أو إزالة الانتباه العرضي القائم على الاستعلام يقلل جميعها الدقة. وفي الوقت نفسه، يقلل تصميم فيجن مامبا الخطي من العمليات الحسابية العائمة بحوالي النصف مقارنةً بخط أساس محول قوي ويضاعف أكثر من ضعف عدد الإطارات المعالجة في الثانية، مما يجعل النهج أكثر ملاءمة للاستخدام التفاعلي الفوري.
تقريب التعاون بين البشر والذكاء الاصطناعي
بالنسبة لغير المتخصصين، الخلاصة الرئيسية هي أن هذا العمل يجعل من الأسهل للناس «التحدث» إلى الصور بلغة طبيعية والحصول على نتائج دقيقة ويمكن التحكم فيها. من خلال السماح للنص والصورة بالإشراف على بعضهما البعض وبالاستفادة من محركات رؤية ولغة فعّالة، يمكن للنظام أن يحدد بسرعة ما يقصده المستخدم تمامًا ويصقل المخطط بخمس نقرات قليلة فقط. هذا المزيج من السرعة والدقة والشفافية له آثار واضحة على تحرير الصور والروبوتات وأدوات الوصول وأي ميدان يحتاج فيه البشر والذكاء الاصطناعي للعمل معًا في مهام بصرية باستخدام لغة يومية.
الاستشهاد: Meng, Y., Sun, H. & Jiang, W. Interactive text-guided image segmentation via vision Mamba and large language models. Sci Rep 16, 14061 (2026). https://doi.org/10.1038/s41598-026-43841-w
الكلمات المفتاحية: تقسيم الصور الموجَّه بالنص, فيجن مامبا, نماذج اللغة الكبيرة, المحاذاة متعددة الوسائط, الرؤية التفاعلية