Clear Sky Science · ru
Интерактивная текстовая сегментация изображений с помощью Vision Mamba и больших языковых моделей
Учим компьютеры видеть то, что мы описываем
Представьте, что вы указываете на оживлённую фотографию и говорите: «женщина в красном пальто у двери», — а компьютер мгновенно обводит именно этого человека по пикселям. В этой работе исследуют, как сделать подобное детализированное редактирование изображений, управляемое языком, быстрым, точным и интерактивным. Сочетая последние достижения в области языковых моделей и новую архитектуру зрения под названием «Mamba», авторы показывают, как машины могут лучше сопоставлять наши слова с точными областями изображения, которые нас интересуют.
Почему слова и изображения трудно сопоставить
Заставить компьютер отделить один объект от фона уже нелегко; потребовать сделать это на основе повседневного языка — ещё сложнее. Фразы вроде «маленькая собака за креслом» объединяют в себе характеристики внешности, размер и пространственные отношения одновременно. Традиционные системы либо анализировали текстовые и визуальные признаки по отдельности, либо комбинировали их простыми способами, что часто давало сбои при длинных или тонких описаниях. Они могли пропускать нужный объект, размывать границы или становиться нестабильными при обучении на плотных, поксельно ориентированных задачах. Ключевая трудность — мультимодальное выравнивание: связать гибкое, высокоуровневое значение в предложениях с точными, низкоуровневыми деталями изображения.
Двусторонний диалог между текстом и изображением
Авторы предлагают H-образную сеть «двунаправленного выравнивания», которая рассматривает текст и изображение как равноправных партнёров, а не использует текст только как одностороннюю инструкцию. Одна ветвь сосредоточена на основной задаче: по изображению и описанию она выдаёт карту вероятностей, выделяющую целевую область. Другая ветвь работает в обратном направлении: пытается выяснить, какие слова в предложении наиболее важны для выбранной области. Обе ветви разделяют компактный набор обучаемых «запросных» векторов, которые собирают воедино наиболее релевантные визуальные и текстовые подсказки в общем пространстве. Специальный штраф согласованности подтягивает систему так, чтобы пиксели, которые она выделяет, и слова, которые считает важными, оставались в согласии. Такая двусторонняя супервизия помогает избежать ложных корреляций и делает поведение модели более интерпретируемым.
Более быстрый визуальный двигатель и более «умный» языковой модуль
Под капотом визуальная часть работает на основе Vision Mamba — архитектуры на базе состояний, созданной для эффективной работы с большими высокоразрешёнными изображениями. Вместо тяжёлых квадратичных вычислений стандартных Transformer-ов, Vision Mamba моделирует дальние связи способом, масштабируемым линейно по размеру изображения. Она также включает лёгкие свёртки для повышения резкости краёв и тонких деталей, что критично при обводке объектов. С текстовой стороны система использует компактный вариант большой языковой модели Qwen. Большая часть её слоёв остаётся замороженной, чтобы сохранить широкое языковое понимание, а только верхние слои аккуратно донастраиваются, чтобы модель особенно хорошо работала с референциальными фразами вроде «второй человек слева», не переобучаясь. Небольшой модуль слияния затем использует общие запросы для выравнивания патчей изображения и токенов слов, а механизм модуляции тонко усиливает или подавляет визуальные каналы на основе текста, превращая абстрактные предложения в конкретные поксельные указания.
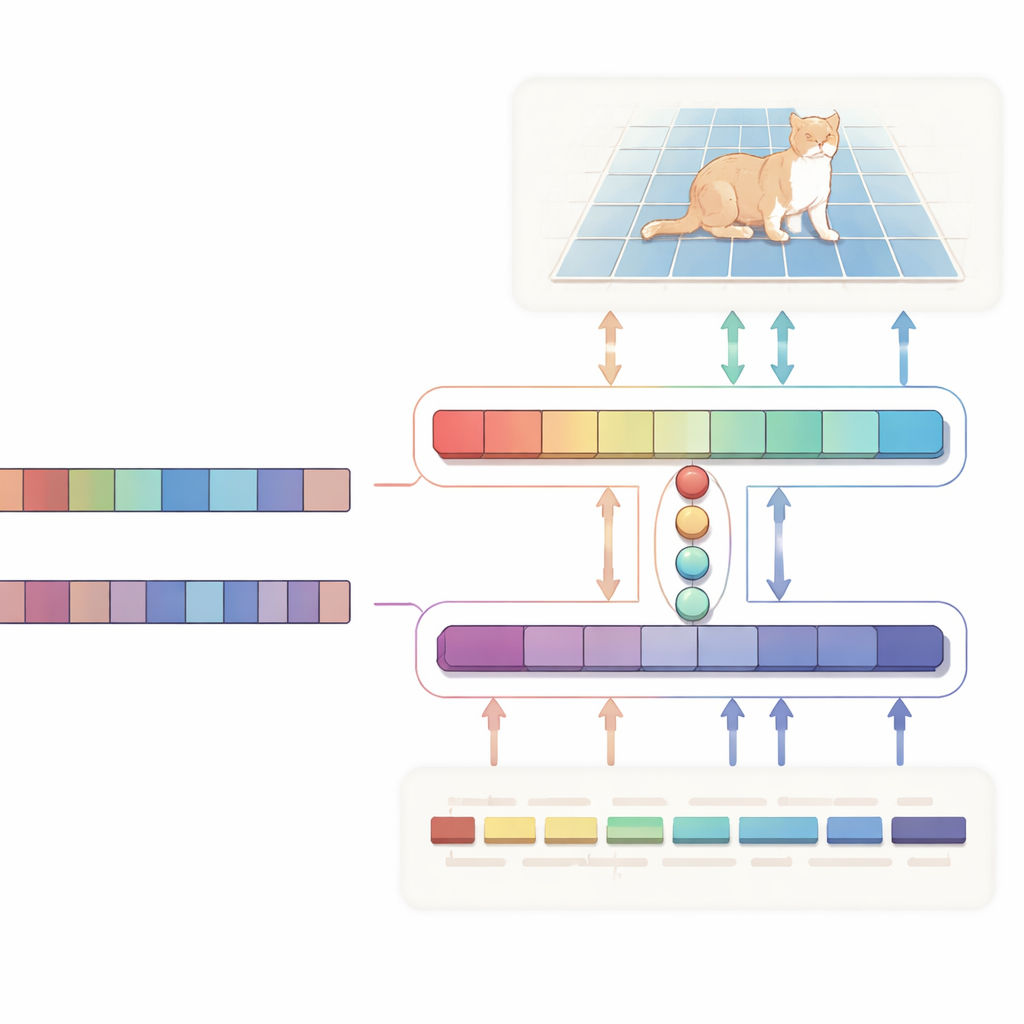
Более точные маски при меньших вычислениях
Для оценки своей конструкции авторы протестировали её на трёх широко используемых бенчмарках — RefCOCO, RefCOCO+ и RefCOCOg — которые содержат десятки тысяч реальных изображений с описаниями конкретных объектов на естественном языке. На этих наборах их метод последовательно показывал более высокие значения метрики пересечения по объединению (IoU) по сравнению со многими известными конкурентами, включая модели на основе Transformer-ов и системы, вдохновлённые фреймворком Segment Anything. Тщательные эксперименты абляции демонстрируют, что каждый компонент важен: замена Vision Mamba на традиционный бэкбон, замена Qwen на более простой текстовый энкодер или удаление кросс-аттенции на основе запросов всё уменьшает точность. В то же время линейная по времени архитектура Vision Mamba сокращает количество операций с плавающей точкой примерно вдвое по сравнению с сильным Transformer-базовым эталоном и более чем вдвое увеличивает число кадров, обрабатываемых в секунду, делая подход более пригодным для реального времени и интерактивного использования.
Сближение сотрудничества человека и ИИ
Для неспециалистов главный вывод в том, что эта работа упрощает возможность «разговаривать» с изображениями на естественном языке и получать точные, управляемые результаты. Благодаря тому, что текст и изображение контролируют друг друга, а также благодаря эффективным визуальным и языковым механизмам, система может быстро сфокусироваться на том, что именно имел в виду пользователь, и уточнить контур всего несколькими кликами. Это сочетание скорости, точности и прозрачности имеет очевидные последствия для фоторедактирования, робототехники, инструментов доступности и любых задач, где людям и ИИ нужно совместно решать визуальные задачи на повседневном языке.
Цитирование: Meng, Y., Sun, H. & Jiang, W. Interactive text-guided image segmentation via vision Mamba and large language models. Sci Rep 16, 14061 (2026). https://doi.org/10.1038/s41598-026-43841-w
Ключевые слова: текстовая сегментация изображений, vision mamba, большие языковые модели, мультимодальное выравнивание, интерактивное зрение