Clear Sky Science · pl
Interaktywna segmentacja obrazów sterowana tekstem za pomocą Vision Mamba i dużych modeli językowych
Nauczanie komputerów rozumienia tego, co opisujemy
Wyobraź sobie wskazanie zatłoczonego zdjęcia i powiedzenie: „kobieta w czerwonym płaszczu przy drzwiach”, a komputer natychmiast obrysowuje tylko tę osobę aż do poziomu pikseli. W artykule badane są sposoby, by tego typu szczegółowa, sterowana językowo edycja obrazów była szybka, dokładna i interaktywna. Łącząc najnowsze osiągnięcia w modelach językowych z nowym typem sieci wizualnej nazwaną „Mamba”, autorzy pokazują, jak maszyny mogą lepiej dopasowywać nasze słowa do dokładnych regionów obrazu, które nas interesują.
Dlaczego trudne jest łączenie słów i obrazów
Oddzielenie obiektu od tła to już wyzwanie; poproszenie o to na podstawie codziennego języka czyni zadanie jeszcze trudniejszym. Zwroty takie jak „mniejszy pies za krzesłem” zawierają jednocześnie informacje o wyglądzie, rozmiarze i relacjach przestrzennych. Tradycyjne systemy albo analizowały cechy tekstu i obrazu osobno, albo łączyły je w proste sposoby, które często zawodziły przy dłuższych lub subtelnych opisach. Mogły przegapić właściwy obiekt, rozmazać granice lub stać się niestabilne podczas trenowania na gęstych, piksel-do-piksela zadaniach. Kluczową trudnością jest wyrównanie międzymodalne: powiązanie elastycznego, wysokopoziomowego znaczenia zdań z precyzyjnymi, niskopoziomowymi szczegółami obrazów.
Dwukierunkowa konwersacja między tekstem a obrazem
Autorzy proponują sieć w kształcie litery H nazwaną „dwukierunkowym wyrównaniem”, która traktuje tekst i obraz jako równorzędnych partnerów, zamiast używać tekstu jedynie jako jednostronnej instrukcji. Jedna gałąź koncentruje się na głównym zadaniu: na podstawie obrazu i opisu generuje mapę prawdopodobieństwa wskazującą docelowy region. Druga gałąź działa w przeciwnym kierunku: stara się wywnioskować, które słowa w zdaniu mają największe znaczenie dla wybranego regionu. Obie gałęzie współdzielą zwięzły zestaw uczonych wektorów „zapytań”, które gromadzą najbardziej istotne wskazówki wizualne i tekstowe w wspólnej przestrzeni. Specjalna funkcja straty zgodności skłania system do tego, by piksele, które podkreśla, i słowa, które uznaje za ważne, pozostawały w zgodzie. Tego rodzaju dwukierunkowy nadzór pomaga zapobiegać dryfowi modelu w kierunku pozornych korelacji i ułatwia interpretację jego zachowania.
Szybszy silnik wizualny i inteligentniejszy mózg językowy
W warstwie wizualnej działa Vision Mamba, architektura oparta na modelach stanu zaprojektowana do efektywnego przetwarzania dużych, wysokorozdzielczych obrazów. Zamiast polegać na kosztownych, kwadratowych obliczeniach standardowych Transformerów, Vision Mamba modeluje relacje na długich dystansach w sposób skalujący się liniowo względem rozmiaru obrazu. Dodatkowo miesza lekkie konwolucje, aby wyostrzyć krawędzie i drobne detale, co jest kluczowe przy obrysowywaniu obiektów. Po stronie tekstowej system używa kompaktowej odmiany dużego modelu językowego Qwen. Większość jego warstw jest zamrożona, by zachować szerokie rozumienie języka, podczas gdy jedynie górne warstwy są łagodnie dostrajane, aby model stał się szczególnie dobry w rozpoznawaniu odniesień typu „druga osoba od lewej”, bez nadmiernego dopasowania. Mały moduł fuzji wykorzystuje współdzielone zapytania do wyrównania fragmentów obrazu i tokenów słów, a mechanizm modulacji subtelnie wzmacnia lub tłumi kanały wizualne na podstawie tekstu, przekształcając abstrakcyjne zdania w konkretne wskazówki na poziomie pikseli.
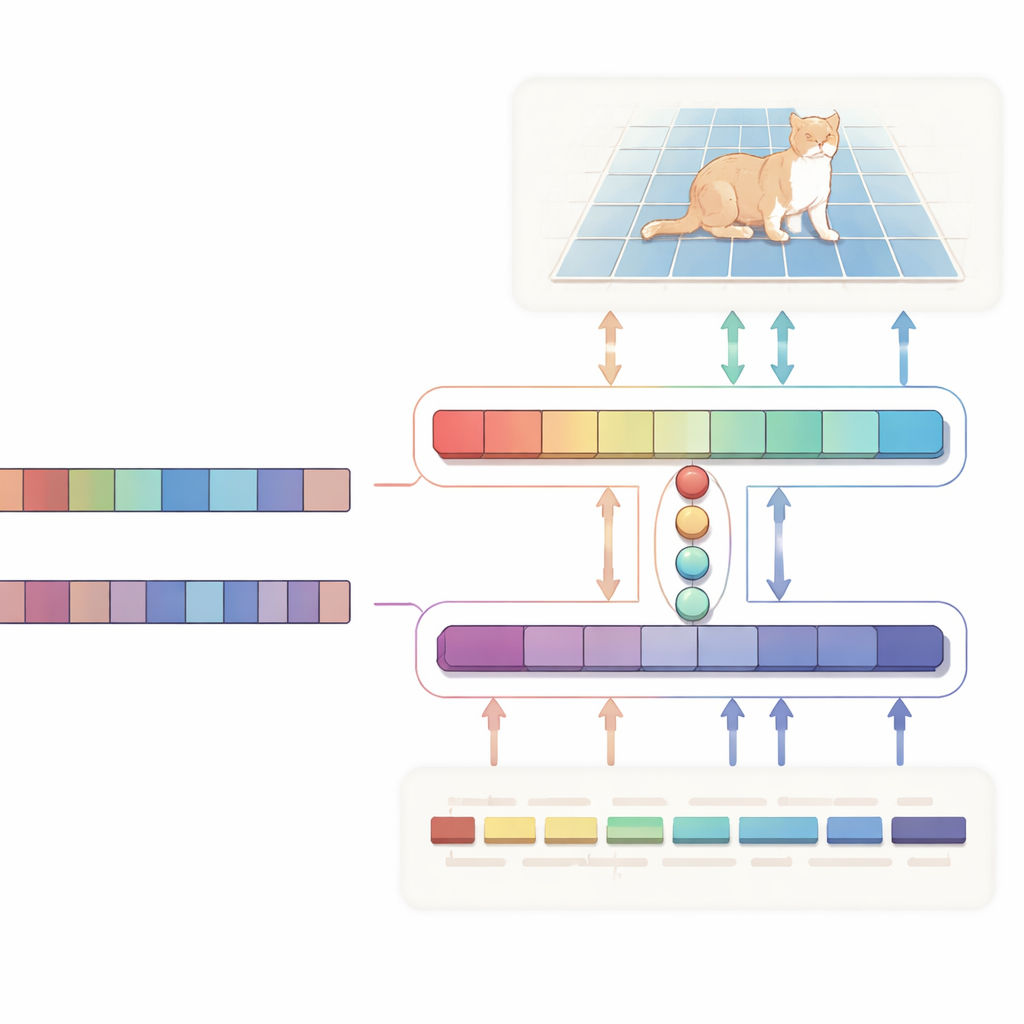
Dokładniejsze maski, mniejsze obciążenie obliczeniowe
Aby przetestować projekt, autorzy ocenili go na trzech powszechnie używanych zestawach referencyjnych — RefCOCO, RefCOCO+ i RefCOCOg — które zawierają dziesiątki tysięcy realistycznych obrazów sparowanych z opisami w języku naturalnym dotyczącymi konkretnych obiektów. W tych zbiorach ich metoda konsekwentnie osiągała wyższe wyniki intersection-over-union niż wiele znanych konkurencyjnych rozwiązań, w tym modele oparte na Transformerach i systemy inspirowane ramą Segment Anything. Dokładne eksperymenty ablacyjne wykazują, że każdy składnik ma znaczenie: zastąpienie Vision Mamba konwencjonalnym trzonem, wymiana Qwen na prostszy enkoder tekstu lub usunięcie zapytań używanych w cross-attention obniża dokładność. Jednocześnie liniowy projekt Vision Mamba zmniejsza liczbę operacji zmiennoprzecinkowych mniej więcej o połowę w porównaniu z mocnym baseline’em Transformerowym i ponad podwaja liczbę klatek przetwarzanych na sekundę, co czyni podejście bardziej odpowiednim do zastosowań w czasie rzeczywistym i interaktywnych.
Zbliżając współpracę ludzi i AI
Dla osób niebędących specjalistami główny wniosek jest taki, że praca ta ułatwia ludziom „rozmawianie” z obrazami w języku naturalnym i uzyskiwanie precyzyjnych, kontrolowalnych rezultatów. Pozwalając tekstowi i obrazowi nadzorować się nawzajem oraz opierając się na wydajnych silnikach wizji i języka, system szybko odnajduje dokładnie to, co użytkownik ma na myśli, i może dopracować obrys kilkoma kliknięciami. To połączenie szybkości, dokładności i przejrzystości ma jasne implikacje dla edycji zdjęć, robotyki, narzędzi dostępności oraz wszędzie tam, gdzie ludzie i AI muszą współpracować nad zadaniami wizualnymi przy użyciu codziennego języka.
Cytowanie: Meng, Y., Sun, H. & Jiang, W. Interactive text-guided image segmentation via vision Mamba and large language models. Sci Rep 16, 14061 (2026). https://doi.org/10.1038/s41598-026-43841-w
Słowa kluczowe: segmentacja obrazów sterowana tekstem, vision mamba, duże modele językowe, multimodalne wyrównanie, interaktywna wizja