Clear Sky Science · ja
ビジョンMambaと大規模言語モデルによる対話式テキスト誘導画像セグメンテーション
私たちが描写するものをコンピュータに見せる方法
混み合った写真を指さして「ドアのそばにいる赤いコートの女性」と言うだけで、コンピュータがその人物だけをピクセル単位で即座に囲い出すことを想像してください。本論文は、その種の細粒度で言語駆動の画像編集を高速かつ正確、かつ対話的に実現する方法を探ります。最近の言語モデルの進展と「Mamba」と呼ばれる新しい種類のビジョンネットワークを組み合わせることで、機械が私たちの言葉を画像内の正確な領域によりよく対応させられることを示しています。
言葉と画像を一致させることが難しい理由
コンピュータに対象物を背景から分離させるだけでも難しい課題です。それを日常的な言語に基づいて行うよう求めると、さらに難度が上がります。「椅子の後ろの小さな犬」のようなフレーズは、外観、サイズ、空間関係を同時に含みます。従来のシステムはテキストと画像の特徴を別々に見たり単純に結合したりすることが多く、説明が長くなったり微妙になったりすると失敗しがちでした。正しい対象を見逃したり、境界がぼやけたり、ピクセル単位の密なタスクで学習すると不安定になることがあります。本質的な難しさはクロスモーダル整合にあり、文の持つ柔軟で高次の意味を画像の正確で低レベルな詳細情報に結びつけることです。
テキストと画像の双方向の対話
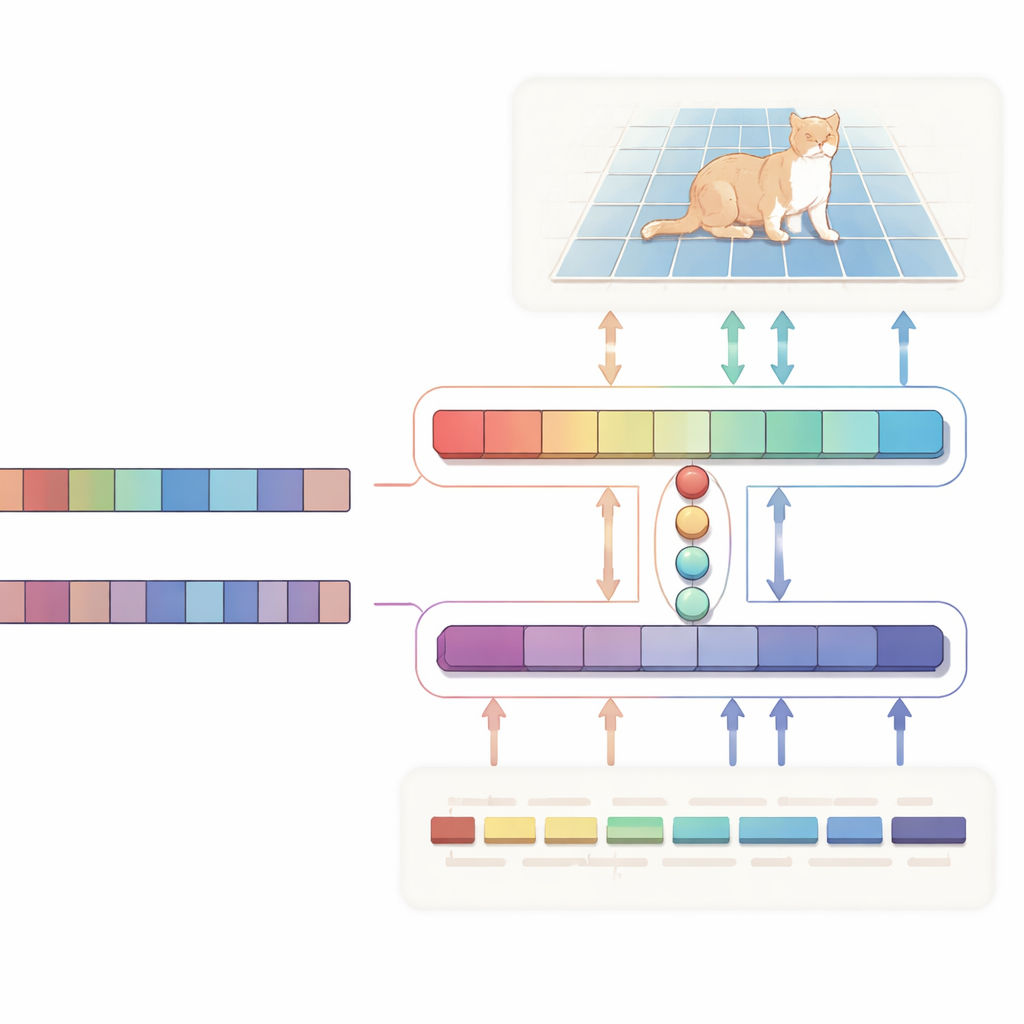
著者らは、テキストと画像を一方向の命令として扱うのではなく同等のパートナーとして扱うH字型の「双方向整合」ネットワークを提案します。一方のブランチは主タスクに集中します:画像と説明からターゲット領域を強調する確率マップを生成します。もう一方のブランチは逆方向に動作し、選ばれた領域にとって文中のどの単語が重要かを推定しようとします。両ブランチは、関連する視覚的・テキスト的手がかりを共通空間に引き寄せる学習済みの小さな“クエリ”ベクトルセットを共有します。特別な一貫性損失により、強調されたピクセルと重要と判断された単語が一致するようにシステムが促されます。この双方向の監督により、モデルが偶発的な相関に流されるのを防ぎ、挙動の解釈もしやすくなります。
より高速な視覚エンジンと賢い言語ブレイン
内部では、視覚側はVision Mambaによって駆動されており、これは大きく高解像度な画像を効率的に扱うための状態空間ベースのアーキテクチャです。標準的なTransformerの二乗的な計算に依存するのではなく、Vision Mambaは画像サイズに対して線形にスケールする形で長距離関係をモデル化します。また、輪郭や細部を際立たせるために軽量な畳み込みを混ぜ込み、物体の輪郭を描く際に重要な細部を強化します。テキスト側ではQwenの小型変種を用いており、その大部分の層は広範な言語理解を保持するために固定され、上位層のみを穏やかに微調整して「左から2番目の人」のような参照表現に特化させつつ過学習を避けます。小さな融合モジュールが共有クエリを用いて画像パッチと単語トークンを整合させ、モジュレーション機構がテキストに基づいて視覚チャネルを微妙に増幅または抑制することで、抽象的な文を具体的なピクセルレベルの指示に変換します。
より正確なマスク、少ない計算量
設計を評価するために、著者らはRefCOCO、RefCOCO+、RefCOCOgという広く使われる三つのベンチマークで検証しました。これらは数万件規模の実世界画像と特定の物体を記述する自然言語のペアを含みます。これらのデータセット全体で、本手法はTransformerベースのモデルやSegment Anythingに触発されたシステムを含む多くの有名な競合より一貫して高いIoU(交差/合計)スコアを達成しました。注意深いアブレーション実験により、各構成要素が重要であることが示されています:Vision Mambaを従来のバックボーンに差し替える、Qwenをより単純なテキストエンコーダに置き換える、またはクエリベースのクロスアテンションを取り除くといずれも精度が低下します。同時に、Vision Mambaの線形時間設計は強力なTransformerベースラインと比較して浮動小数点演算量を概ね半分に削減し、1秒あたりの処理フレーム数を二倍以上に増やしており、リアルタイムでの対話的利用により適しています。
人間とAIの協働をより身近に
非専門家にとっての主な結論は、本研究により人が自然言語で「画像に話しかけ」て正確で制御可能な結果を得やすくなったという点です。テキストと画像が互いに監督し合うことを可能にし、効率的な視覚と言語のエンジンを組み合わせることで、システムはユーザーの意図を素早く特定し、数回のクリックで輪郭を洗練できます。その速度、精度、透明性の組み合わせは、写真編集、ロボティクス、アクセシビリティツール、そして日常言語で視覚タスクを扱う人間とAIの共同作業が必要なあらゆる場面に明確な影響を与えます。
引用: Meng, Y., Sun, H. & Jiang, W. Interactive text-guided image segmentation via vision Mamba and large language models. Sci Rep 16, 14061 (2026). https://doi.org/10.1038/s41598-026-43841-w
キーワード: テキスト誘導画像セグメンテーション, vision mamba, 大規模言語モデル, マルチモーダル整合, 対話型ビジョン