Clear Sky Science · de
Interaktive, textgesteuerte Bildsegmentierung mittels Vision Mamba und großen Sprachmodellen
Computern beibringen, das zu sehen, was wir beschreiben
Stellen Sie sich vor, Sie zeigen auf ein geschäftiges Foto und sagen „die Frau im roten Mantel an der Tür“, und ein Computer umrundet sofort genau diese Person bis auf Pixel-Ebene. Dieses Paper untersucht, wie man eine derart fein granulare, sprachgesteuerte Bildbearbeitung schnell, präzise und interaktiv macht. Durch die Verknüpfung jüngster Fortschritte in Sprachmodellen mit einer neuen Art von Visionsnetz namens „Mamba“ zeigen die Autorinnen und Autoren, wie Maschinen unsere Worte besser mit den exakt relevanten Bildregionen in Einklang bringen können.
Warum Wörter und Bilder schwer zuzuordnen sind
Ein Objekt vom Hintergrund zu trennen ist für Computer bereits eine Herausforderung; bittet man sie, dies anhand alltäglicher Sprache zu tun, wird es noch komplizierter. Formulierungen wie „der kleinere Hund hinter dem Stuhl“ enthalten gleichzeitig Informationen zu Erscheinung, Größe und räumlichen Beziehungen. Traditionelle Systeme betrachteten Text- und Bildmerkmale oft getrennt oder kombinierten sie auf einfache Weise, was bei langen oder feinen Beschreibungen häufig versagte. Sie konnten das richtige Objekt übersehen, Kanten verwischen oder instabil werden, wenn sie auf dichte Pixel-zu-Pixel-Aufgaben trainiert wurden. Der zentrale Schwierigkeitsgrad liegt in der cross-modalen Ausrichtung: die flexible, hochgradige Bedeutung von Sätzen mit den präzisen, niedergradigen Bilddetails zu verbinden.
Ein zweiseitiges Gespräch zwischen Text und Bild
Die Autorinnen und Autoren schlagen ein H-förmiges „bidirektionales Ausrichtungs“-Netzwerk vor, das Text und Bild als gleichwertige Partner behandelt, statt Text nur als einseitige Anweisung zu nutzen. Ein Zweig konzentriert sich auf die Hauptaufgabe: Für ein Bild und eine Beschreibung erzeugt er eine Wahrscheinlichkeitskarte, die die Zielregion hervorhebt. Der andere Zweig läuft in entgegengesetzter Richtung: Er versucht zu ermitteln, welche Wörter im Satz für die gewählte Region am wichtigsten sind. Beide Zweige teilen einen kompakten Satz gelernter „Query“-Vektoren, die die relevantesten visuellen und textuellen Hinweise in einem gemeinsamen Raum zusammenführen. Ein spezieller Konsistenzverlust sorgt dafür, dass die hervorgehobenen Pixel und die als wichtig eingestuften Wörter in Übereinstimmung bleiben. Diese zweiseitige Aufsicht hilft, das Modell von zufälligen Korrelationen fernzuhalten und macht sein Verhalten leichter interpretierbar.
Ein schnellerer visueller Motor mit einem schlaueren Sprachkern
Unter der Haube wird die visuelle Seite von Vision Mamba angetrieben, einer auf Zustandsraumprinzipien basierenden Architektur, die darauf ausgelegt ist, große, hochauflösende Bilder effizient zu verarbeiten. Anstatt auf die schweren, quadratischen Berechnungen herkömmlicher Transformer zu setzen, modelliert Vision Mamba Langstreckenbeziehungen auf eine Weise, die linear mit der Bildgröße skaliert. Zudem mischt sie leichte Faltungen ein, um Kanten und feine Details zu schärfen — entscheidend beim Umreißen von Objekten. Auf der Textseite verwendet das System eine kompakte Variante des großen Sprachmodells Qwen. Die meisten seiner Schichten bleiben eingefroren, um breites Sprachverständnis zu bewahren, während nur die oberen Schichten behutsam feinabgestimmt werden, sodass das Modell besonders gut mit referentiellen Ausdrücken wie „die zweite Person von links“ umgehen kann, ohne zu überfitten. Ein kleines Fusionsmodul nutzt dann die gemeinsamen Queries, um Bildausschnitte und Wort-Token zu verbinden, und ein Modulationsmechanismus verstärkt oder dämpft visuelle Kanäle basierend auf dem Text, wodurch abstrakte Sätze in konkrete, pixelgenaue Anweisungen verwandelt werden.
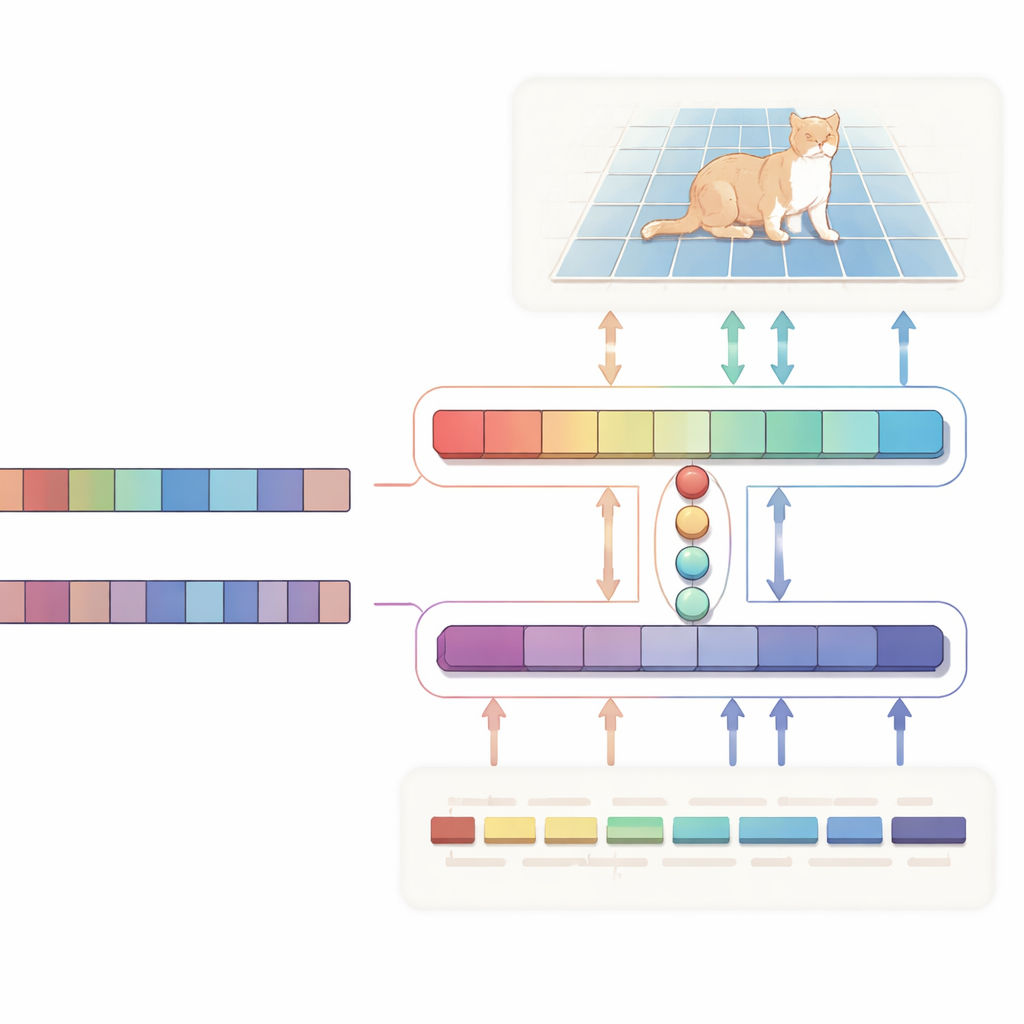
Genauere Masken, weniger Rechenaufwand
Um ihr Design zu testen, evaluierten die Autorinnen und Autoren es auf drei weit verbreiteten Benchmarks — RefCOCO, RefCOCO+ und RefCOCOg — die zehntausende realer Bilder mit natürlichsprachlichen Beschreibungen spezifischer Objekte enthalten. Über diese Datensätze hinweg erreichte ihre Methode konsistent höhere Intersection-over-Union-Werte als viele bekannte Konkurrenten, darunter transformer-basierte Modelle und Systeme, die vom Segment-Anything-Framework inspiriert sind. Sorgfältige Ablationsstudien zeigen, dass jede Komponente zählt: Der Austausch von Vision Mamba gegen ein konventionelles Backbone, das Ersetzen von Qwen durch einen einfacheren Textencoder oder das Entfernen der query-basierten Kreuzaufmerksamkeit reduziert die Genauigkeit. Gleichzeitig halbiert das linearzeitliche Design von Vision Mamba ungefähr die Gleitkommaoperationen gegenüber einem starken Transformer-Baseline und mehr als verdoppelt die Anzahl der pro Sekunde verarbeiteten Frames, was den Ansatz besser für Echtzeit-Interaktion geeignet macht.
Mensch–KI-Zusammenarbeit näherbringen
Für Nicht-Fachleute ist die wichtigste Erkenntnis, dass diese Arbeit es Menschen erleichtert, in natürlicher Sprache „mit“ Bildern zu sprechen und präzise, kontrollierbare Ergebnisse zu erhalten. Indem Text und Bild sich gegenseitig beaufsichtigen und auf effiziente Vision- und Sprachmotoren aufgebaut wird, kann das System schnell genau das erfassen, was ein Nutzer meint, und den Umriss mit nur wenigen Klicks verfeinern. Diese Kombination aus Geschwindigkeit, Genauigkeit und Transparenz hat klare Implikationen für Fotobearbeitung, Robotik, Hilfstechnologien und alle Bereiche, in denen Menschen und KI gemeinsam an visuellen Aufgaben mit alltäglicher Sprache arbeiten müssen.
Zitation: Meng, Y., Sun, H. & Jiang, W. Interactive text-guided image segmentation via vision Mamba and large language models. Sci Rep 16, 14061 (2026). https://doi.org/10.1038/s41598-026-43841-w
Schlüsselwörter: textgesteuerte Bildsegmentierung, vision mamba, große Sprachmodelle, multimodale Ausrichtung, interaktive Bildverarbeitung