Clear Sky Science · sv
Interaktiv textstyrd bildsegmentering via Vision Mamba och stora språkmodeller
Lära datorer att se det vi beskriver
Föreställ dig att du pekar på ett livligt fotografi och säger "kvinnan i den röda kappan vid dörren", och att en dator omedelbart ritar en kontur runt just den personen ner på pixelnivå. Denna artikel utforskar hur man kan göra den typen av finslipad, språkdriven bildredigering snabb, exakt och interaktiv. Genom att blanda nyare framsteg inom språkmodeller och en ny typ av visuell nätverksarkitektur kallad "Mamba" visar författarna hur maskiner bättre kan matcha våra ord med de exakta områden i en bild som vi bryr oss om.
Varför ord och bilder är svåra att matcha
Att få datorer att skilja ett objekt från bakgrunden är redan en utmaning; att be dem göra det utifrån vardagligt språk gör det ännu svårare. Fraser som "den mindre hunden bakom stolen" rymmer samtidigt information om utseende, storlek och rumsliga relationer. Traditionella system antingen betraktade text- och bildfunktioner separat eller kombinerade dem på enkla sätt, vilket ofta misslyckades när beskrivningar blev långa eller subtila. De kunde missa rätt objekt, sudda ut gränser eller bli instabila när de tränades på täta, pixel-för-pixel-uppgifter. Den centrala svårigheten är tvärmodal inriktning: att koppla den flexibla, hög-nivå betydelsen i meningar till de precisa, låg-nivå detaljerna i bilder.
En tvåvägskonversation mellan text och bild
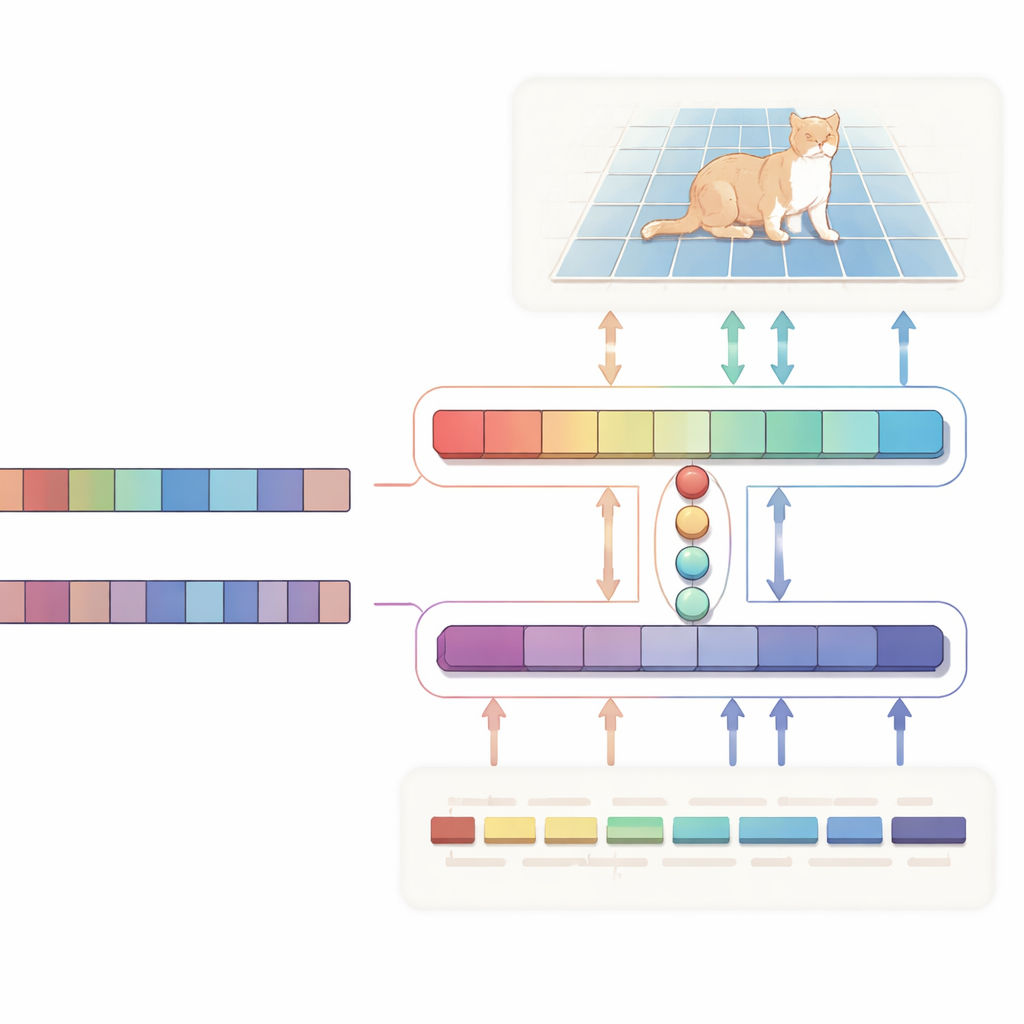
Författarna föreslår ett H-format "tvåvägsanpassnings"-nätverk som behandlar text och bild som jämställda parter istället för att enbart använda text som en envägssignal. En gren fokuserar på huvuduppgiften: givet en bild och en beskrivning producerar den en sannolikhetskarta som lyfter fram målregionen. Den andra grenen går åt motsatt håll: den försöker härleda vilka ord i meningen som är viktigast för den valda regionen. Båda grenarna delar en kompakt uppsättning inlärda "query"-vektorer som samlar de mest relevanta visuella och textuella ledtrådarna i ett gemensamt utrymme. En särskild konsistensförlust styr systemet så att pixlarna det markerar och de ord det bedömer som viktiga förblir i överensstämmelse. Denna tvåvägsövervakning hjälper till att förhindra att modellen driver iväg mot felaktiga korrelationer och gör dess beteende lättare att tolka.
En snabbare visuell motor med ett smartare språkcentrum
Under huven drivs den visuella sidan av Vision Mamba, en arkitektur baserad på tillståndsrum designad för att effektivt hantera stora, högupplösta bilder. Istället för att förlita sig på de tunga, kvadratiska beräkningarna hos standardtransformers modellerar Vision Mamba långräckviddsrelationer på ett sätt som skalar linjärt med bildstorleken. Den blandar också in lätta convolutioner för att skärpa kanter och fina detaljer, vilket är avgörande när man ritar objektgränser. På textsidan använder systemet en kompakt variant av Qwen-stor språkmodellen. De flesta lager hålls frysta för att bevara bred språkförståelse, medan endast de övre lagren finjusteras försiktigt så att modellen blir särskilt bra på referentiella fraser som "den andra personen från vänster" utan att överanpassa. En liten fusionsmodul använder sedan de delade query-vektorerna för att anpassa bildpatchar och ordtoken, och en modulationsmekanism stärker eller dämpar subtilt visuella kanaler baserat på texten, vilket förvandlar abstrakta satser till konkret, pixel-nivå vägledning.
Mer precisa masker, mindre beräkning
För att testa sin design utvärderade författarna den på tre välanvända benchmarkar—RefCOCO, RefCOCO+ och RefCOCOg—som innehåller tiotusentals verkliga bilder parade med naturligt språk som beskriver specifika objekt. Över dessa datamängder uppnådde deras metod konsekvent högre intersection-over-union-poäng än många välkända konkurrenter, inklusive transformerbaserade modeller och system inspirerade av Segment Anything-ramverket. Noggranna ablationsexperiment visar att varje beståndsdel spelar roll: att byta ut Vision Mamba mot en konventionell backbone, ersätta Qwen med en enklare textkodare eller ta bort query-baserad korsuppmärksamhet minskar alla noggrannheten. Samtidigt halverar Vision Mambas linjära design ungefär flyttal-beräkningarna jämfört med en stark transformer-baslinje och mer än fördubblar antalet bildrutor som kan bearbetas per sekund, vilket gör tillvägagångssättet mer lämpligt för realtidsinteraktivt bruk.
Närma människa–AI-samarbete
För icke-specialister är huvudpoängen att detta arbete gör det enklare för människor att "prata" med bilder på naturligt språk och få precisa, kontrollerbara resultat. Genom att låta text och bild övervaka varandra och genom att bygga på effektiva visuella och språkliga motorer kan systemet snabbt fokusera på exakt vad en användare menar och förfina konturen med bara några få klick. Denna kombination av hastighet, noggrannhet och transparens har tydliga tillämpningar för fotoredigering, robotik, hjälpmedel och alla sammanhang där människor och AI behöver samarbeta i visuella uppgifter med vardagligt språk.
Citering: Meng, Y., Sun, H. & Jiang, W. Interactive text-guided image segmentation via vision Mamba and large language models. Sci Rep 16, 14061 (2026). https://doi.org/10.1038/s41598-026-43841-w
Nyckelord: textstyrd bildsegmentering, vision mamba, stora språkmodeller, multimodal inriktning, interaktiv datorseende