Clear Sky Science · it
Segmentazione interattiva di immagini guidata da testo tramite Vision Mamba e modelli linguistici di grandi dimensioni
Insegnare ai computer a vedere ciò che descriviamo
Immaginate di indicare una fotografia affollata e dire: “la donna con il cappotto rosso vicino alla porta”, e che un computer delinei istantaneamente solo quella persona fino al livello dei pixel. Questo articolo esplora come rendere questo tipo di modifica dell’immagine, guidata dal linguaggio, precisa, rapida e interattiva. Fondendo i progressi recenti nei modelli linguistici con un nuovo tipo di rete visiva chiamata “Mamba”, gli autori mostrano come le macchine possano meglio associare le nostre parole alle esatte regioni di un’immagine che ci interessano.
Perché è difficile mettere in corrispondenza parole e immagini
Far sì che i computer separino un oggetto dallo sfondo è già una sfida; chiedere loro di farlo sulla base del linguaggio quotidiano la rende ancora più complessa. Frasi come “il cane più piccolo dietro la sedia” condensano aspetto, dimensione e relazioni spaziali tutte insieme. I sistemi tradizionali guardavano alle caratteristiche testuali e visive separatamente o le combinavano in modi semplici, spesso fallendo quando le descrizioni diventavano lunghe o sottili. Potrebbero individuare l’oggetto sbagliato, sfumare i bordi o diventare instabili se addestrati su compiti densi a livello di pixel. La difficoltà chiave è l’allineamento cross-modale: collegare il significato flessibile e di alto livello nelle frasi con i dettagli precisi e di basso livello nelle immagini.
Una conversazione a doppio senso tra testo e immagine
Gli autori propongono una rete a forma di H di “allineamento bidirezionale” che tratta testo e immagine come partner alla pari, invece di usare il testo come una semplice istruzione unidirezionale. Un ramo si concentra sul compito principale: data un’immagine e una descrizione, produce una mappa di probabilità che evidenzia la regione target. L’altro ramo va nella direzione opposta: cerca di inferire quali parole della frase siano più rilevanti per la regione scelta. Entrambi i rami condividono un compatto insieme di vettori di “query” appresi che mettono insieme i segnali visivi e testuali più pertinenti in uno spazio comune. Una loss di consistenza speciale spinge il sistema affinché i pixel evidenziati e le parole ritenute importanti rimangano in accordo. Questa supervisione a doppio senso aiuta a impedire che il modello scivoli in correlazioni spurie e rende il suo comportamento più facile da interpretare.
Un motore visivo più veloce con un cervello linguistico più intelligente
Sotto il cofano, il lato visivo è alimentato da Vision Mamba, un’architettura basata su state-space progettata per gestire immagini grandi e ad alta risoluzione in modo efficiente. Invece di affidarsi ai pesanti calcoli quadratici dei Transformer standard, Vision Mamba modella le relazioni a lungo raggio in modo scalabile linearmente con la dimensione dell’immagine. Mescola inoltre convoluzioni leggere per enfatizzare bordi e dettagli fini, cruciali quando si delineano oggetti. Sul lato testuale, il sistema usa una variante compatta del grande modello linguistico Qwen. La maggior parte dei suoi strati rimane congelata per preservare una comprensione linguistica ampia, mentre solo gli strati superiori vengono lievemente fine-tuned in modo che il modello diventi particolarmente abile con frasi referenziali come “la seconda persona da sinistra” senza sovraddestrarsi. Un piccolo modulo di fusione utilizza poi le query condivise per allineare i patch dell’immagine e i token delle parole, e un meccanismo di modulazione aumenta o sopprime sottilmente canali visivi in base al testo, trasformando frasi astratte in guida concreta a livello di pixel.
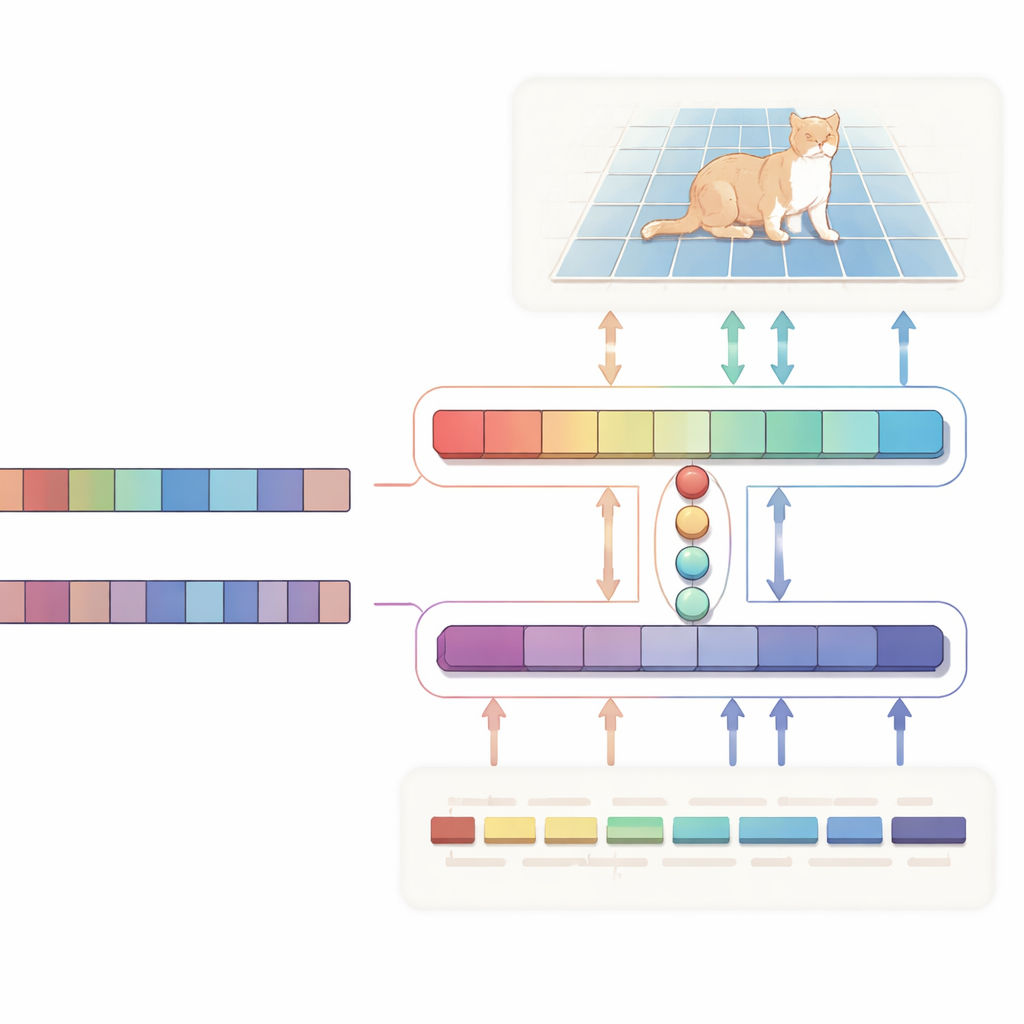
Maschere più accurate, meno calcolo
Per testare il loro progetto, gli autori lo hanno valutato su tre benchmark ampiamente usati—RefCOCO, RefCOCO+ e RefCOCOg—which contengono decine di migliaia di immagini del mondo reale abbinate a descrizioni in linguaggio naturale di oggetti specifici. Su questi dataset, il loro metodo ha costantemente raggiunto punteggi di intersection-over-union più alti rispetto a molti concorrenti ben noti, inclusi modelli basati sui Transformer e sistemi ispirati al framework Segment Anything. Esperimenti di ablazione accurati mostrano che ogni componente è importante: sostituire Vision Mamba con un backbone convenzionale, rimpiazzare Qwen con un encoder testuale più semplice o rimuovere l’attenzione incrociata basata su query riduce tutte le prestazioni. Allo stesso tempo, il design a tempo lineare di Vision Mamba dimezza approssimativamente le operazioni in virgola mobile rispetto a un forte baseline Transformer e più che raddoppia il numero di frame processati al secondo, rendendo l’approccio più adatto all’uso in tempo reale e interattivo.
Avvicinare la collaborazione uomo–IA
Per i non specialisti, la conclusione principale è che questo lavoro rende più facile per le persone “parlare” con le immagini in linguaggio naturale e ottenere risultati precisi e controllabili. Consentendo a testo e immagine di supervisionarsi a vicenda e basandosi su motori visivi e linguistici efficienti, il sistema può individuare rapidamente ciò che l’utente intende e perfezionare il contorno con pochi click. Questa combinazione di velocità, accuratezza e trasparenza ha implicazioni evidenti per l’editing fotografico, la robotica, gli strumenti di accessibilità e qualsiasi contesto in cui umani e IA debbano collaborare su compiti visivi usando il linguaggio quotidiano.
Citazione: Meng, Y., Sun, H. & Jiang, W. Interactive text-guided image segmentation via vision Mamba and large language models. Sci Rep 16, 14061 (2026). https://doi.org/10.1038/s41598-026-43841-w
Parole chiave: segmentazione di immagini guidata da testo, vision mamba, modelli linguistici di grandi dimensioni, allineamento multimodale, visione interattiva