Clear Sky Science · pt
Segmentação interativa de imagem guiada por texto via Vision Mamba e grandes modelos de linguagem
Ensinando computadores a ver o que descrevemos
Imagine apontar para uma fotografia cheia de gente e dizer: “a mulher com o casaco vermelho junto à porta”, e em seguida ter um computador contornando instantaneamente apenas essa pessoa até o nível de pixel. Este artigo explora como tornar esse tipo de edição de imagem guiada por linguagem — precisa, rápida e interativa. Ao combinar avanços recentes em modelos de linguagem com um novo tipo de rede de visão chamada “Mamba”, os autores mostram como as máquinas podem alinhar melhor nossas palavras às regiões exatas que nos interessam em uma imagem.
Por que é difícil casar palavras e imagens
Fazer computadores separar um objeto do fundo já é um desafio; pedir que o façam com base em linguagem cotidiana torna a tarefa ainda mais complexa. Frases como “o cachorro menor atrás da cadeira” condensam aparência, tamanho e relações espaciais ao mesmo tempo. Sistemas tradicionais ou analisavam texto e imagem separadamente ou os combinavam de formas simples, o que frequentemente falhava quando as descrições ficavam longas ou sutis. Podem deixar de identificar o objeto certo, borrar limites ou ficar instáveis quando treinados em tarefas densas, pixel a pixel. A dificuldade central é o alinhamento cross-modal: conectar o significado flexível e de alto nível das frases com os detalhes precisos e de baixo nível das imagens.
Uma conversa bidirecional entre texto e imagem
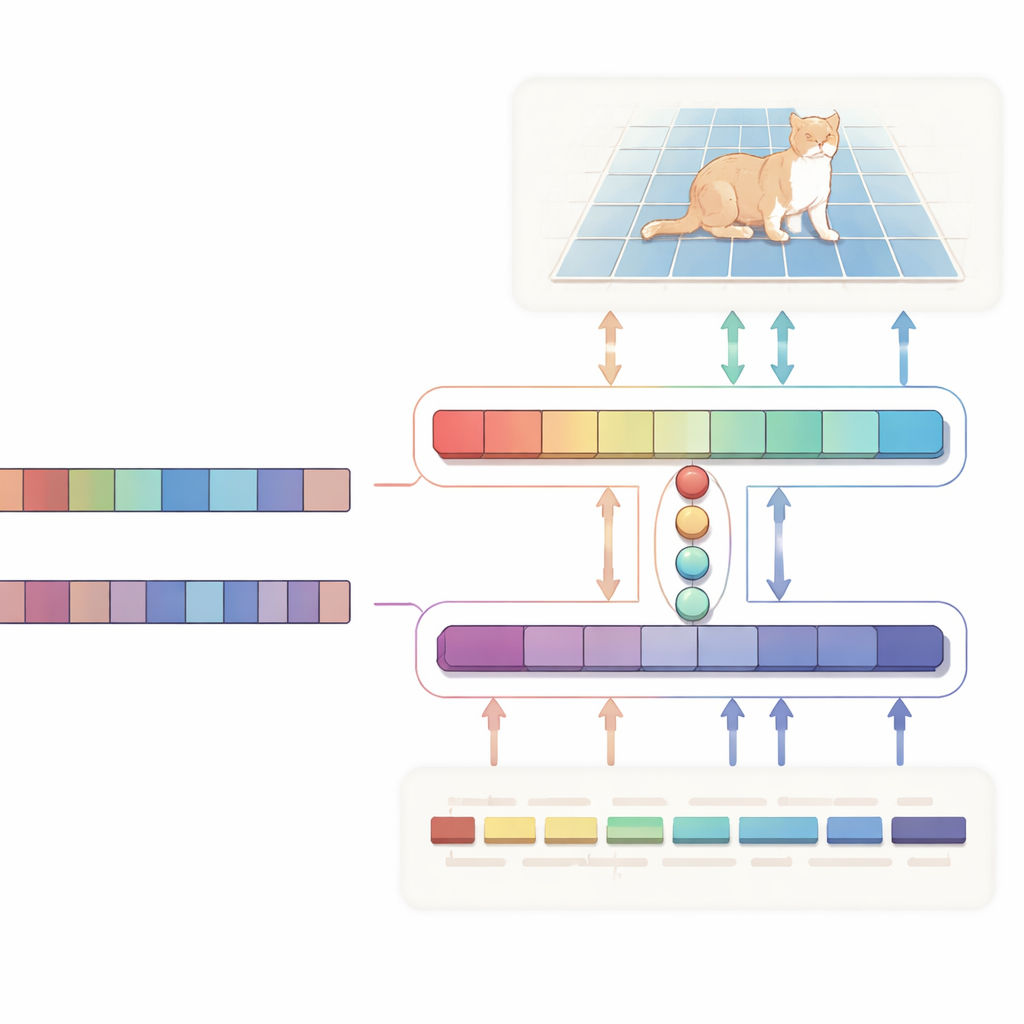
Os autores propõem uma rede em forma de H de “alinhamento bidirecional” que trata texto e imagem como parceiros iguais, em vez de usar o texto apenas como uma instrução unidirecional. Um ramo foca na tarefa principal: dado uma imagem e uma descrição, produz um mapa de probabilidade que destaca a região-alvo. O outro ramo vai no sentido oposto: tenta inferir quais palavras da sentença são mais relevantes para a região escolhida. Ambos os ramos compartilham um conjunto compacto de vetores “query” aprendidos que reúnem os sinais visuais e textuais mais pertinentes em um espaço comum. Uma perda de consistência especial empurra o sistema para que os pixels que destaca e as palavras que considera importantes permaneçam em concordância. Essa supervisão de mão dupla ajuda a evitar correlações espúrias e torna o comportamento do modelo mais fácil de interpretar.
Um motor visual mais rápido com um cérebro de linguagem mais inteligente
Por baixo do capô, o lado visual é alimentado pelo Vision Mamba, uma arquitetura baseada em espaço de estados projetada para lidar com imagens grandes e de alta resolução de forma eficiente. Em vez de depender dos pesados cálculos quadráticos dos Transformers padrão, o Vision Mamba modela relações de longo alcance de maneira que escala linearmente com o tamanho da imagem. Também incorpora convoluções leves para acentuar bordas e detalhes finos, cruciais ao contornar objetos. No lado do texto, o sistema usa uma variante compacta do grande modelo de linguagem Qwen. A maior parte de suas camadas é mantida congelada para preservar uma compreensão ampla da linguagem, enquanto apenas as camadas superiores são finamente ajustadas para tornar o modelo especialmente bom em frases referenciais como “a segunda pessoa da esquerda” sem sobreajustar. Um pequeno módulo de fusão usa então as queries compartilhadas para alinhar patches de imagem e tokens de palavras, e um mecanismo de modulação realça ou suprime sutilmente canais visuais com base no texto, transformando sentenças abstratas em orientação concreta ao nível do pixel.
Máscaras mais precisas, menos computação
Para testar o projeto, os autores o avaliaram em três benchmarks amplamente usados — RefCOCO, RefCOCO+ e RefCOCOg — que contêm dezenas de milhares de imagens do mundo real pareadas com descrições em linguagem natural de objetos específicos. Nesses conjuntos de dados, o método deles consistentemente alcançou pontuações mais altas de intersection-over-union do que muitos concorrentes conhecidos, incluindo modelos baseados em Transformer e sistemas inspirados pela estrutura Segment Anything. Experimentos de ablação cuidadosos mostram que cada ingrediente importa: trocar o Vision Mamba por um backbone convencional, substituir o Qwen por um codificador de texto mais simples ou remover a atenção cruzada baseada em queries reduz a precisão. Ao mesmo tempo, o desenho em tempo linear do Vision Mamba corta operações de ponto flutuante pela metade em comparação com um forte baseline Transformer e mais que dobra o número de quadros processados por segundo, tornando a abordagem mais adequada para uso interativo em tempo real.
Aproximando a colaboração humano–IA
Para não especialistas, a principal conclusão é que este trabalho facilita que pessoas “conversem” com imagens em linguagem natural e obtenham resultados precisos e controláveis. Ao permitir que texto e imagem supervisionem um ao outro e ao construir sobre motores de visão e linguagem eficientes, o sistema pode rapidamente identificar exatamente o que o usuário quer e refinar o contorno com apenas alguns cliques. Essa combinação de velocidade, precisão e transparência tem implicações claras para edição de fotos, robótica, ferramentas de acessibilidade e qualquer cenário em que humanos e IA precisem colaborar em tarefas visuais usando linguagem cotidiana.
Citação: Meng, Y., Sun, H. & Jiang, W. Interactive text-guided image segmentation via vision Mamba and large language models. Sci Rep 16, 14061 (2026). https://doi.org/10.1038/s41598-026-43841-w
Palavras-chave: segmentação de imagem guiada por texto, vision mamba, grandes modelos de linguagem, alinhamento multimodal, visão interativa