Clear Sky Science · en
Interactive text-guided image segmentation via vision Mamba and large language models
Teaching Computers to See What We Describe
Imagine pointing at a busy photograph and saying, “the woman in the red coat by the door,” then having a computer instantly outline just that person down to the pixel. This paper explores how to make that kind of fine-grained, language-driven image editing fast, accurate, and interactive. By blending recent advances in language models and a new kind of vision network called “Mamba,” the authors show how machines can better match our words to the exact regions we care about in an image.
Why Words and Pictures Are Hard to Match
Getting computers to separate one object from the background is already a challenge; asking them to do it based on everyday language makes it even harder. Phrases like “the smaller dog behind the chair” pack in appearance, size, and spatial relationships all at once. Traditional systems either looked at text and image features separately or combined them in simple ways, which often failed when descriptions became long or subtle. They might miss the right object, blur boundaries, or become unstable when trained on dense, pixel-by-pixel tasks. The key difficulty is cross-modal alignment: connecting the flexible, high-level meaning in sentences with the precise, low-level details in images.
A Two-Way Conversation Between Text and Image
The authors propose an H-shaped “bidirectional alignment” network that treats text and image as equal partners rather than simply using text as a one-way instruction. One branch focuses on the main job: given an image and a description, it produces a probability map highlighting the target region. The other branch runs in the opposite direction: it tries to infer which words in the sentence matter most for the chosen region. Both branches share a compact set of learned “query” vectors that pull together the most relevant visual and textual cues into a common space. A special consistency loss nudges the system so that the pixels it highlights and the words it deems important stay in agreement. This two-way supervision helps keep the model from drifting into spurious correlations and makes its behavior easier to interpret.
A Faster Visual Engine with a Smarter Language Brain
Under the hood, the visual side is powered by Vision Mamba, a state-space–based architecture designed to handle large, high-resolution images efficiently. Instead of relying on the heavy, quadratic computations of standard Transformers, Vision Mamba models long-range relationships in a way that scales linearly with image size. It also mixes in lightweight convolutions to sharpen edges and fine details, which are crucial when outlining objects. On the text side, the system uses a compact variant of the Qwen large language model. Most of its layers are kept frozen to preserve broad language understanding, while only the top layers are gently fine-tuned so the model becomes especially good at referential phrases like “the second person from the left” without overfitting. A small fusion module then uses the shared queries to align image patches and word tokens, and a modulation mechanism subtly boosts or suppresses visual channels based on the text, turning abstract sentences into concrete, pixel-level guidance.
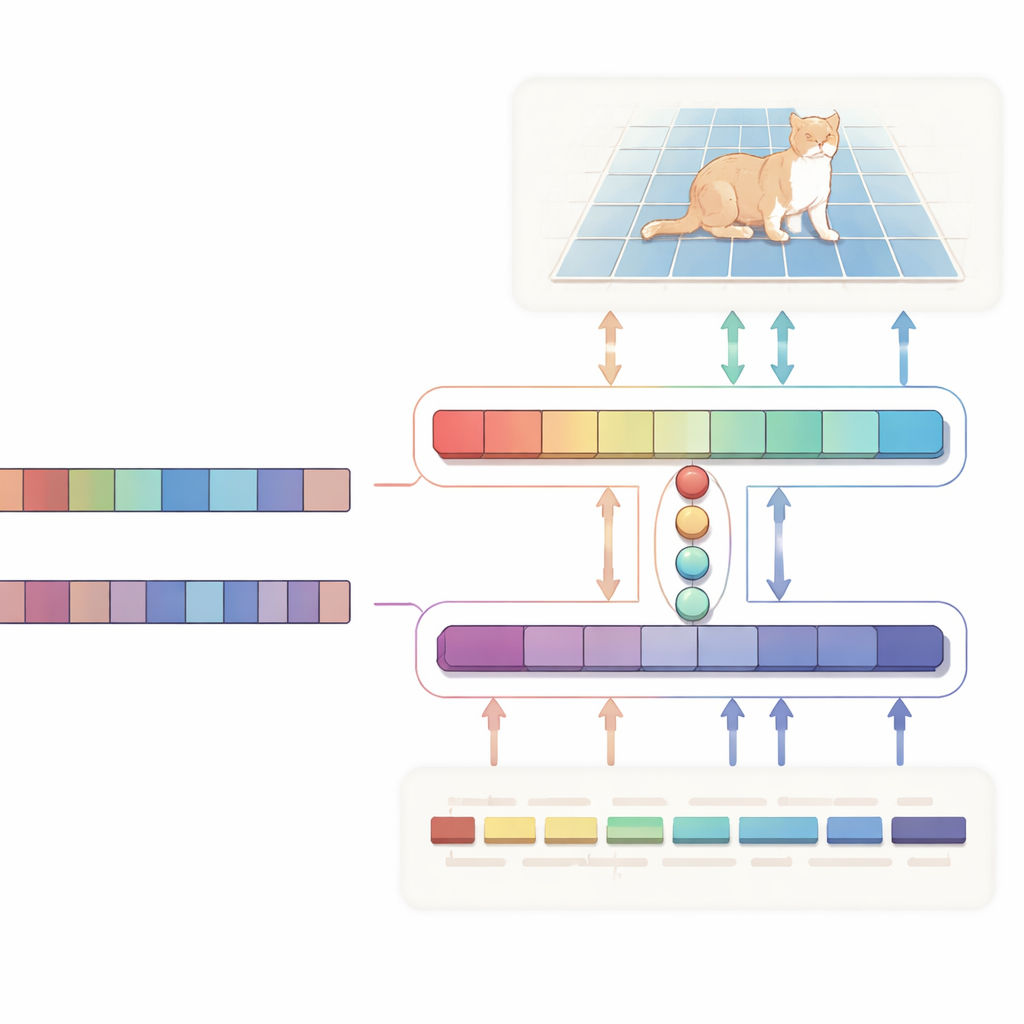
More Accurate Masks, Less Computation
To test their design, the authors evaluated it on three widely used benchmarks—RefCOCO, RefCOCO+, and RefCOCOg—which contain tens of thousands of real-world images paired with natural-language descriptions of specific objects. Across these datasets, their method consistently achieved higher intersection-over-union scores than many well-known competitors, including Transformer-based models and systems inspired by the Segment Anything framework. Careful ablation experiments show that each ingredient matters: swapping out Vision Mamba for a conventional backbone, replacing Qwen with a simpler text encoder, or removing the query-based cross-attention all reduces accuracy. At the same time, Vision Mamba’s linear-time design cuts floating-point operations by roughly half compared with a strong Transformer baseline and more than doubles the number of frames processed per second, making the approach more suitable for real-time, interactive use.
Bringing Human–AI Collaboration Closer
For non-specialists, the main takeaway is that this work makes it easier for people to “talk” to images in natural language and get precise, controllable results. By allowing text and image to supervise each other and by building on efficient vision and language engines, the system can quickly home in on exactly what a user means and refine the outline with just a few clicks. That combination of speed, accuracy, and transparency has clear implications for photo editing, robotics, accessibility tools, and any setting where humans and AI need to work together on visual tasks using everyday language.
Citation: Meng, Y., Sun, H. & Jiang, W. Interactive text-guided image segmentation via vision Mamba and large language models. Sci Rep 16, 14061 (2026). https://doi.org/10.1038/s41598-026-43841-w
Keywords: text-guided image segmentation, vision mamba, large language models, multimodal alignment, interactive vision