Clear Sky Science · fr
Segmentation d’image interactive guidée par le texte via Vision Mamba et de grands modèles de langage
Apprendre aux ordinateurs à voir ce que nous décrivons
Imaginez pointer une photo animée et dire « la femme au manteau rouge près de la porte », puis voir un ordinateur tracer instantanément le contour de cette personne jusqu’au pixel. Cet article explore comment rendre ce type d’édition d’image guidée par le langage à la fois fine, rapide et interactive. En combinant des progrès récents des modèles de langage et un nouveau type de réseau visuel appelé « Mamba », les auteurs montrent comment les machines peuvent mieux faire correspondre nos mots aux régions exactes qui nous intéressent dans une image.
Pourquoi il est difficile d’associer mots et images
Demander à un ordinateur de séparer un objet de l’arrière-plan est déjà un défi ; l’exiger sur la base d’un langage courant complique encore la tâche. Des phrases comme « le petit chien derrière la chaise » condensent simultanément l’apparence, la taille et les relations spatiales. Les systèmes traditionnels traitaient souvent les caractéristiques textuelles et visuelles séparément ou les combinaient de façon trop simple, ce qui échouait quand les descriptions devenaient longues ou subtiles. Ils pouvaient manquer l’objet correct, estomper les contours ou devenir instables lors d’un entraînement sur des tâches denses au niveau du pixel. La difficulté centrale est l’alignement intermodal : relier le sens flexible et de haut niveau des phrases aux détails précis et de bas niveau des images.
Une conversation à double sens entre texte et image
Les auteurs proposent un réseau en H de « alignement bidirectionnel » qui traite texte et image comme des partenaires égaux plutôt que d’utiliser le texte comme une instruction unidirectionnelle. Une branche se concentre sur la tâche principale : étant donné une image et une description, elle produit une carte de probabilité mettant en évidence la région ciblée. L’autre branche fonctionne dans la direction opposée : elle essaie d’inférer quels mots de la phrase comptent le plus pour la région choisie. Les deux branches partagent un petit ensemble de vecteurs de « requête » appris qui rassemblent les indices visuels et textuels les plus pertinents dans un espace commun. Une perte de cohérence spécifique incite le système à garder l’accord entre les pixels qu’il met en évidence et les mots qu’il juge importants. Cette supervision à double sens aide à éviter que le modèle ne dérive vers des corrélations fallacieuses et rend son comportement plus facile à interpréter.
Un moteur visuel plus rapide et un cerveau linguistique plus affiné
Sous le capot, la partie visuelle est alimentée par Vision Mamba, une architecture basée sur des espaces d’état conçue pour traiter efficacement de grandes images haute résolution. Plutôt que de s’appuyer sur les calculs quadratiques lourds des Transformers classiques, Vision Mamba modélise les relations à longue portée d’une manière qui évolue linéairement avec la taille de l’image. Il intègre aussi des convolutions légères pour affiner les contours et les détails fins, essentiels pour tracer des objets. Côté texte, le système utilise une variante compacte du grand modèle de langage Qwen. La plupart de ses couches restent gelées pour préserver une compréhension linguistique large, tandis que seules les couches supérieures sont légèrement ajustées afin que le modèle excelle particulièrement sur des phrases référentielles telles que « la deuxième personne à partir de la gauche » sans surapprendre. Un petit module de fusion utilise ensuite les requêtes partagées pour aligner les patches d’image et les tokens de mots, et un mécanisme de modulation renforce ou atténue subtilement des canaux visuels en fonction du texte, transformant des phrases abstraites en indications concrètes au niveau du pixel.
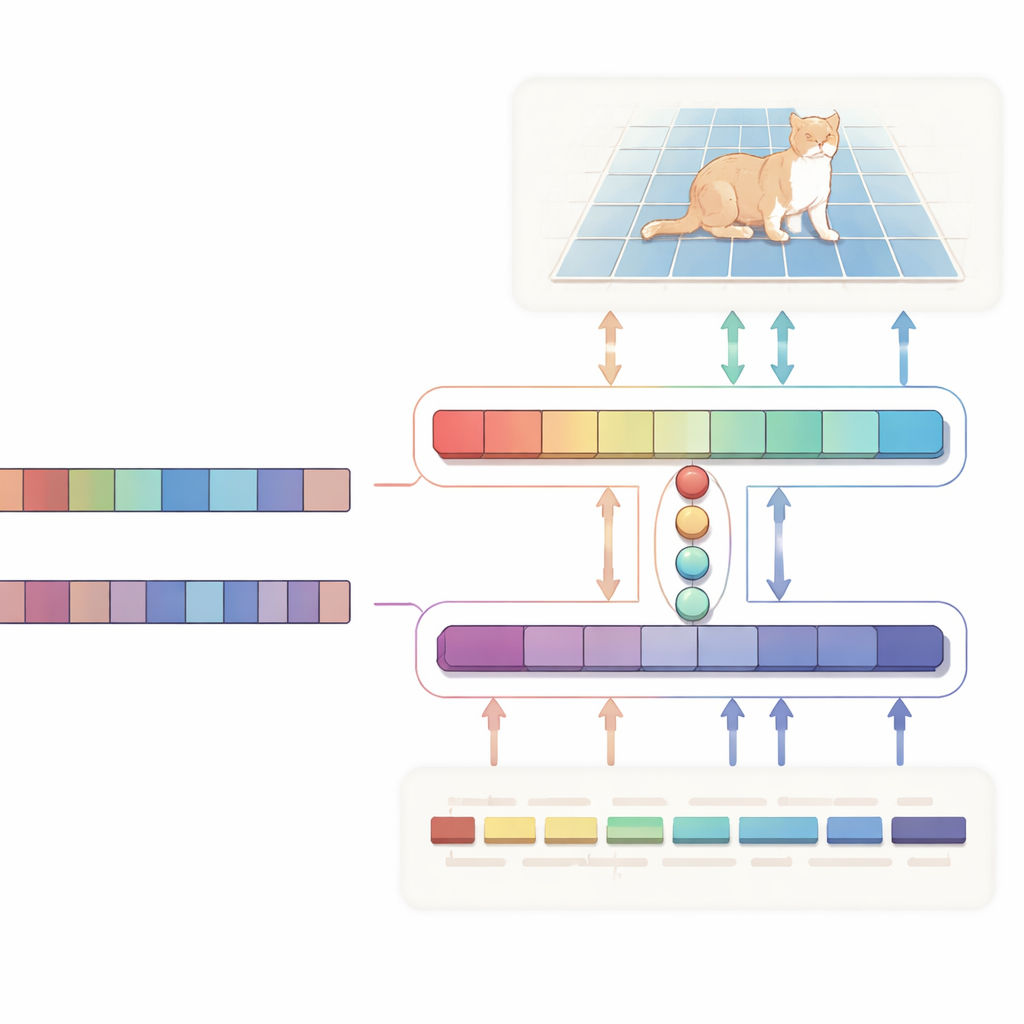
Des masques plus précis, moins de calcul
Pour évaluer leur conception, les auteurs l’ont testée sur trois benchmarks largement utilisés — RefCOCO, RefCOCO+ et RefCOCOg — qui contiennent des dizaines de milliers d’images du monde réel assorties de descriptions en langage naturel d’objets spécifiques. Sur ces ensembles de données, leur méthode obtient systématiquement des scores d’intersection sur union plus élevés que de nombreux concurrents connus, y compris des modèles basés sur Transformer et des systèmes inspirés par le cadre Segment Anything. Des expériences d’ablation soignées montrent que chaque composant compte : remplacer Vision Mamba par un backbone conventionnel, substituer Qwen par un encodeur de texte plus simple ou supprimer l’attention croisée basée sur les requêtes réduit tous la précision. En parallèle, la conception en temps linéaire de Vision Mamba réduit les opérations à virgule flottante d’environ moitié par rapport à un solide baseline Transformer et plus que double le nombre d’images traitées par seconde, rendant l’approche mieux adaptée à une utilisation interactive en temps réel.
Rapprocher la collaboration humain–IA
Pour les non-spécialistes, la principale conclusion est que ce travail facilite la « communication » avec les images en langage naturel et l’obtention de résultats précis et contrôlables. En permettant au texte et à l’image de se superviser mutuellement et en s’appuyant sur des moteurs visuels et linguistiques efficaces, le système peut rapidement cibler exactement ce que l’utilisateur entend et affiner le contour en seulement quelques clics. Cette combinaison de rapidité, précision et transparence a des implications claires pour la retouche photo, la robotique, les outils d’accessibilité et tout contexte où humains et IA doivent collaborer sur des tâches visuelles en utilisant le langage courant.
Citation: Meng, Y., Sun, H. & Jiang, W. Interactive text-guided image segmentation via vision Mamba and large language models. Sci Rep 16, 14061 (2026). https://doi.org/10.1038/s41598-026-43841-w
Mots-clés: segmentation d’image guidée par le texte, vision mamba, grands modèles de langage, alignement multimodal, vision interactive