Clear Sky Science · tr
Görsel Mamba ve büyük dil modelleri ile etkileşimli metin yönlendirmeli görüntü segmentasyonu
Bilgisayarlara Tanımladığımızı Görmeyi Öğretmek
Yoğun bir fotoğrafa işaret edip “kapı kenarındaki kırmızı kabanlı kadın” dediğinizi ve bilgisayarın tam da o kişiyi piksel düzeyinde anında çevrelemesini hayal edin. Bu makale, bu tür ince ayrıntılı, dil güdümlü görüntü düzenlemeyi nasıl hızlı, doğru ve etkileşimli hale getirebileceğimizi inceliyor. Dil modellerindeki son ilerlemeleri ve “Mamba” adını verdikleri yeni bir görsel ağ türünü harmanlayarak, yazarlar makinelerin sözlerimizi görüntüde önem verdiğimiz bölgelere daha iyi eşleştirmesini gösteriyor.
Sözlerle Görüntüleri Eşleştirmenin Zorluğu
Bilgisayarların bir nesneyi arka plandan ayırması zaten zor bir görev; bunu günlük dil kullanarak yapmalarını istemek işi daha da zorlaştırır. “Sandalyenin arkasındaki daha küçük köpek” gibi ifadeler görünüm, boyut ve mekânsal ilişkileri aynı anda taşır. Geleneksel sistemler ya metin ve görüntü özelliklerine ayrı ayrı bakıyor ya da bunları basit yollarla birleştiriyordu; bu da açıklamalar uzadıkça veya inceleştikçe başarısız olabiliyordu. Doğru nesneyi kaçırabilir, sınırları bulanıklaştırabilir veya piksel piksele yoğun görevlerde eğitim sırasında kararsız hale gelebilirler. Temel zorluk, çapraz modal hizalama: cümlelerdeki esnek, üst düzey anlamı görüntülerdeki kesin, düşük düzey ayrıntılarla bağlamak.
Metin ve Görüntü Arasında İki Yönlü Bir Konuşma
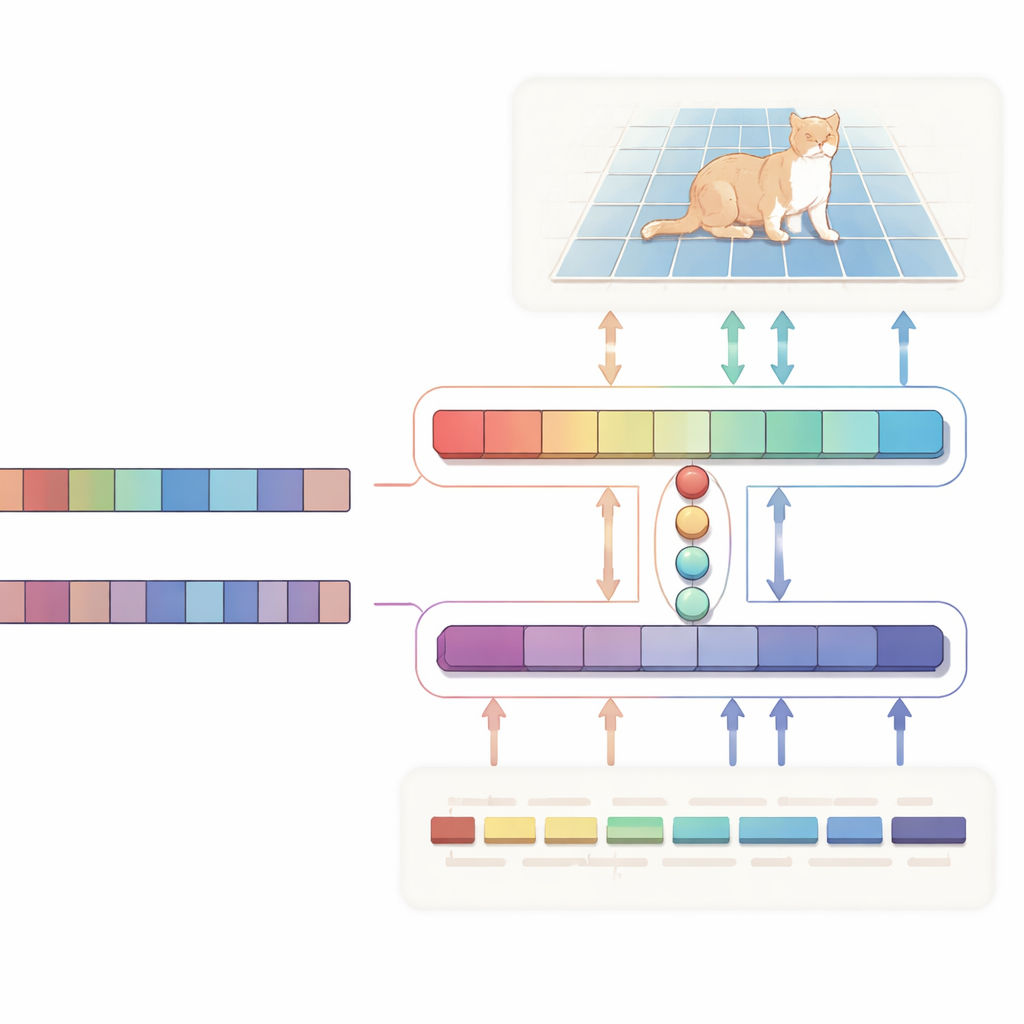
Yazarlar, metni tek yönlü bir talimattan ziyade eşit bir ortak olarak ele alan H biçimli “çift yönlü hizalama” ağı öneriyor. Bir dal, ana işe odaklanıyor: bir görüntü ve açıklama verildiğinde hedef bölgeyi vurgulayan olasılık haritası üretiyor. Diğer dal ters yönde çalışıyor: seçilen bölge için cümlede hangi kelimelerin daha önemli olduğunu çıkarmaya çalışıyor. Her iki dal da, en ilgili görsel ve metinsel ipuçlarını ortak bir uzayda bir araya getiren sıkıştırılmış bir öğrenilmiş “sorgu” vektörleri kümesini paylaşıyor. Özel bir tutarlılık kaybı, sistemin vurguladığı piksellerle önemli bulduğu kelimelerin uyum içinde kalmasını teşvik ediyor. Bu iki yönlü denetim, modelin yanlış ilişkiler kurmasının önüne geçmeye ve davranışını daha yorumlanabilir kılmaya yardımcı oluyor.
Daha Hızlı Bir Görsel Motor ve Daha Akıllı Bir Dil Beyni
Görsel tarafın altında, büyük, yüksek çözünürlüklü görüntülerle verimli çalışmak üzere tasarlanmış durum-uzay tabanlı bir mimari olan Vision Mamba yer alıyor. Standart Transformer’ların ağır, kuadratik hesaplamalarına güvenmek yerine, Vision Mamba uzun menzilli ilişkileri görüntü boyutuyla doğrusal ölçeklenen bir şekilde modeller. Ayrıca nesnelerin çevrelerini ve ince ayrıntılarını keskinleştirmek için hafif konvolüsyonlar karıştırır; bu, nesneleri çizerken kritik öneme sahiptir. Metin tarafında ise sistem, Qwen büyük dil modelinin kompakt bir varyantını kullanıyor. Katmanlarının çoğu geniş dil anlayışını korumak için donduruluyor; yalnızca üst katmanlar, “soldan ikinci kişi” gibi referansal ifadelerde özellikle iyi olabilmesi için nazikçe ince ayar yapılıyor, aşırı öğrenmeyi önlemek için. Küçük bir füzyon modülü paylaşılan sorguları kullanarak görüntü yamalarını ve kelime tokenlarını hizalıyor ve bir modülasyon mekanizması, metne dayanarak görsel kanalları hafifçe güçlendirip bastırarak soyut cümleleri somut, piksel düzeyinde yönlendirmelere dönüştürüyor.
Daha Doğru Maskeler, Daha Az Hesaplama
Tasarımı test etmek için yazarlar, belirli nesnelerin doğal dil açıklamalarıyla eşleştirilmiş on binlerce gerçek dünya görüntüsü içeren yaygın üç ölçüt—RefCOCO, RefCOCO+ ve RefCOCOg—üzerinde değerlendirme yapmışlar. Bu veri setlerinde yöntemleri, Transformer tabanlı modeller ve Segment Anything çerçevesinden esinlenen sistemler dahil olmak üzere birçok tanınmış rakibe kıyasla tutarlı olarak daha yüksek kesişim-bölme (IoU) puanları elde etmiş. Titiz ablatyon deneyleri her bileşenin önemli olduğunu gösteriyor: Vision Mamba’yı geleneksel bir omurga ile değiştirmek, Qwen’i daha basit bir metin kodlayıcıyla ikame etmek veya sorgu tabanlı çapraz-dikkati kaldırmak doğruluğu azaltıyor. Aynı zamanda Vision Mamba’nın doğrusal zamanlı tasarımı, güçlü bir Transformer karşılayana göre kayan nokta işlemlerini yaklaşık yarıya indiriyor ve saniye başına işlenen kare sayısını iki kattan fazla artırarak yaklaşımı gerçek zamanlı, etkileşimli kullanıma daha uygun hale getiriyor.
İnsan–YZ İşbirliğini Yakınlaştırmak
Uzman olmayanlar için ana çıkarım, bu çalışmanın insanların görüntülerle doğal dil kullanarak “konuşmasını” ve kesin, kontrol edilebilir sonuçlar almasını kolaylaştırmasıdır. Metin ve görüntünün birbirini denetlemesine izin vererek ve verimli görsel ve dil motorları üzerine inşa ederek, sistem kullanıcının ne demek istediğine hızla odaklanabiliyor ve sadece birkaç tıklamayla konturu iyileştirebiliyor. Bu hız, doğruluk ve şeffaflık bileşimi fotoğraf düzenleme, robotik, erişilebilirlik araçları ve insanların ve Yapay Zekâ’nın günlük dil kullanarak görsel görevlerde birlikte çalışması gereken her ortam için açık sonuçlar taşıyor.
Atıf: Meng, Y., Sun, H. & Jiang, W. Interactive text-guided image segmentation via vision Mamba and large language models. Sci Rep 16, 14061 (2026). https://doi.org/10.1038/s41598-026-43841-w
Anahtar kelimeler: metin yönlendirmeli görüntü segmentasyonu, görsel mamba, büyük dil modelleri, multimodal hizalama, etkileşimli görme