Clear Sky Science · zh
基于核的动态集成方法用于分类类不平衡且类间重叠的数据
为何数据中的稀有样本重要
现代生活中的许多决策——从识别欺诈性信用卡交易到捕捉疾病的早期迹象——都依赖于从历史数据中学习的算法。但在大多数真实世界的数据集中,重要事件是罕见的:只有少数交易是欺诈,只有少数病人病情严重。这些稀有样本很容易被大量普通样本淹没,当“正常”和“异常”的模式看起来非常相似时,问题会变得更难。本文提出了一种新的训练机器学习系统的方法,使其能对这些难以察觉、易被忽略的样本给予特殊且智能的关注。
当常见样本掩盖了关键样本
在许多数据集中,一类样本的数量远多于其他类——例如,每一笔欺诈交易对应着成千上万笔安全交易。标准算法试图最大化整体准确率,因此最终会把注意力放在多数类上而忽视少数类。当不同类在测量特征上重叠、难以区分时,这一问题会被进一步放大。在欺诈检测、医学诊断、故障检测和异常识别等领域,少数类样本正是我们最关心的对象,对它们的错误分类可能带来高昂的代价或危险。作者将他们的工作框定在这一双重挑战上:类别规模不均和复杂高维数据中重叠的边界。
更聪明的分类器团队
作者不是依赖单一模型,而是构建了一支由支持向量机(SVM)分类器组成的团队——即集成,每个成员使用不同的观察数据方式(称为核函数)。关键思想是让这个集成具有动态性和局部感知能力。首先,对数据进行精心预处理:对特征进行归一化以使其在可比尺度上,并使用称为SMOTE的技术为欠代表类生成额外的合成样本,平衡训练集。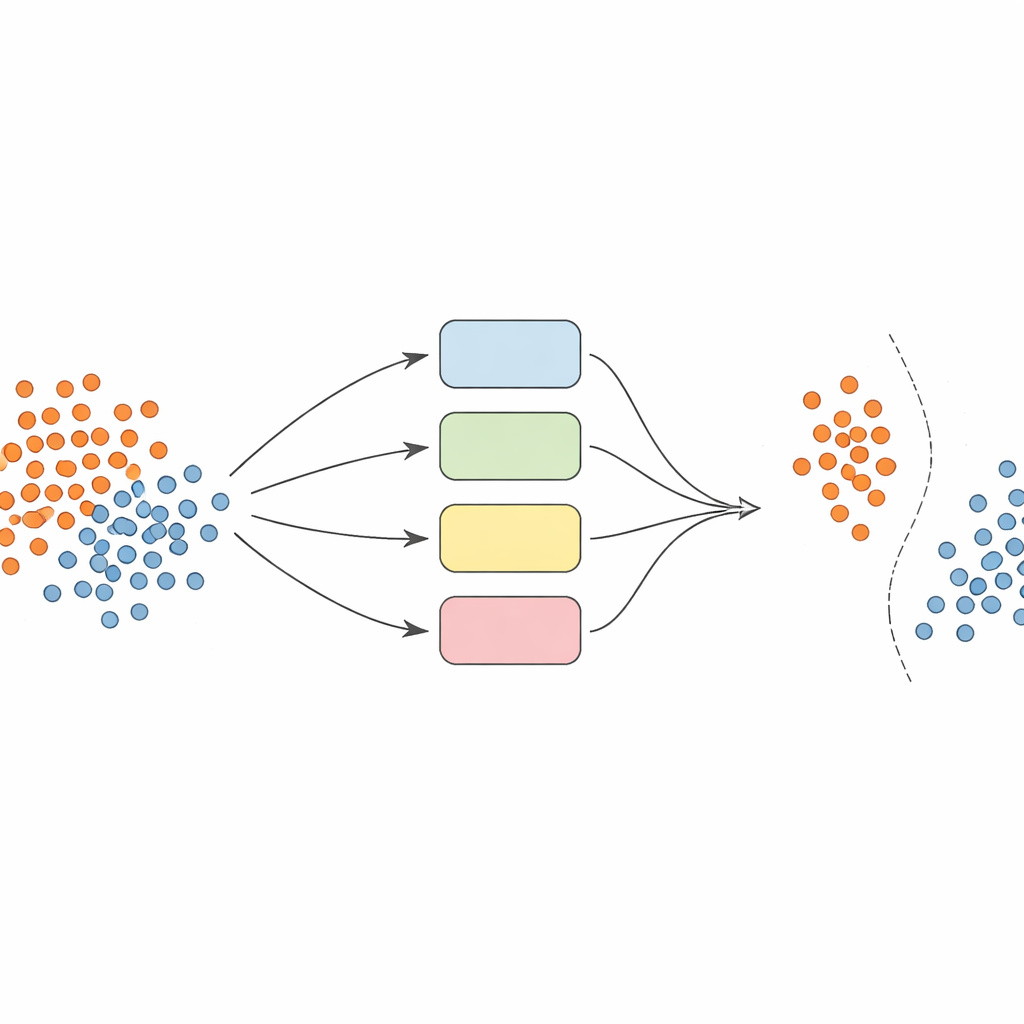
教模型关注模糊边界
该方法的核心是一个新的“边界感知”核,它有意将注意力集中在类间重叠的区域。在训练过程中,该方法寻找处在模糊邻域中的样本,通过与最近邻的距离来度量。这些重叠样本随后会得到特殊处理:每个样本用于训练的SVM其核函数会被一个权重修正,该权重反映了该样本在局部的判别信息量。靠近决策边界的少数类样本会被赋予更高的权重,而处于这些区域的多数类样本则被降低权重。实际上,该方法在稀有但重要的点周围拉伸了决策面,帮助在类间划出更清晰的界限,而无需不必要地伪造更多数据。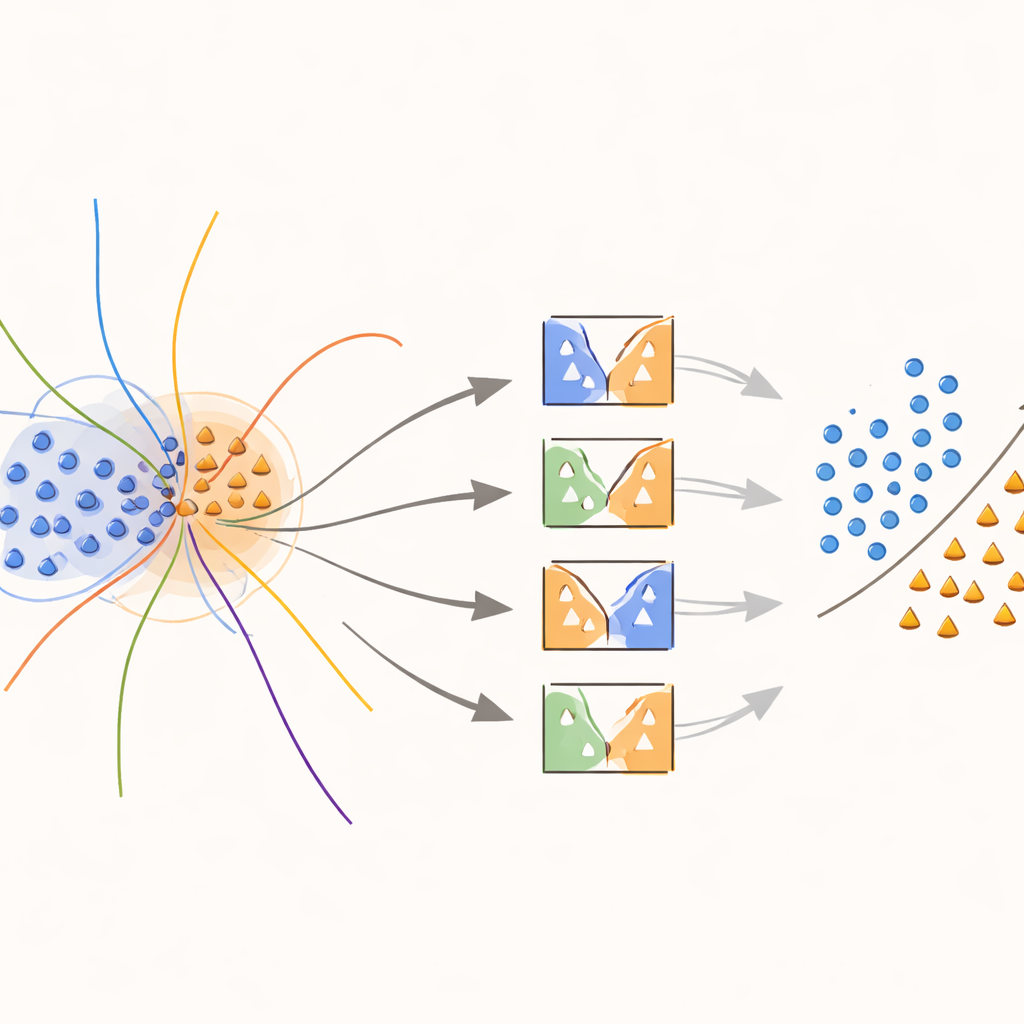
为每次预测挑选合适的专家
在对新样本进行分类时,系统不会盲目地对所有模型的意见取平均。相反,系统首先查看附近的验证样本——它已经见过的案例——并估计每个分类器在该局部区域的能力。只有表现最好的那一部分模型,即在历史上处理类似样本表现良好的模型,才被允许投票。它们的组合决定最终预测。基于实例的模型选择既可以保持计算在可控范围内,又能确保每次决策由那些最了解该数据空间特定角落的模型来支撑。
实践中效果如何?
为了验证他们的方法,研究人员在公开库中的20个多类和20个二类数据集上进行了实验,覆盖医学诊断、质量评估和模式识别等多种任务。他们将这种动态集成与强基线方法进行了比较,包括与流行的AdaBoost技术结合的改进SVM。在各个数据集上,这种新方法在总体准确率和少数类与多数类识别平衡性(由称为G-mean的统计量衡量)方面始终表现更好。在许多基准测试中,它仍保持有竞争力的精确率,意味着在更有效地捕捉稀有样本的同时避免了过多的误报。
这对现实决策意味着什么
对于非专业读者来说,结论是作者设计出了一种更细致且更具适应性的方式,使算法能够倾听数据中的“微弱声音”。通过同时应对类别不均和模糊边界,并在每次决策中仅让最相关的模型发声,他们的框架降低了忽视稀有但重要事件的风险。这使得该方法对那些错过异常样本(如欺诈交易、故障部件或疾病早期迹象)比误分类普通样本更为严重的应用特别有吸引力。
引用: Abokadr, S., Azman, A., Hamdan, H. et al. Kernel-based dynamic ensemble approach for classifying imbalanced data with overlapping classes. Sci Rep 16, 13789 (2026). https://doi.org/10.1038/s41598-026-42940-y
关键词: 数据不平衡, 类间重叠, 集成学习, 支持向量机, 欺诈与异常检测