Clear Sky Science · pl
Dynamiczne podejście zespołowe oparte na jądrze do klasyfikacji niezrównoważonych danych z nakładającymi się klasami
Dlaczego rzadkie przypadki w danych mają znaczenie
Wiele decyzji we współczesnym życiu — od wykrycia oszukańczej transakcji kartą kredytową po wychwycenie wczesnego sygnału choroby — zależy od algorytmów uczących się na podstawie danych historycznych. W większości rzeczywistych zbiorów danych ważne zdarzenia są jednak rzadkie: tylko niewielka część transakcji to oszustwa, tylko kilku pacjentów jest poważnie chorych. Te rzadkie przypadki mogą łatwo zginąć w morzu zwykłych przykładów, a sytuacja staje się jeszcze trudniejsza, gdy wzorce „normalne” i „nieprawidłowe” wyglądają bardzo podobnie. W artykule przedstawiono nowy sposób trenowania systemów uczenia maszynowego, aby poświęcały szczególną, inteligentną uwagę tym trudnym do zauważenia, łatwym do przeoczenia przypadkom.
Kiedy pospolite przykłady ukrywają kluczowe
W wielu zbiorach jeden typ przykładów znacznie przeważa nad innymi — na przykład tysiące bezpiecznych transakcji na każde oszustwo. Standardowe algorytmy dążą do maksymalizacji ogólnej dokładności, więc koncentrują się na większości i ignorują mniejszość. Problem pogłębia się, gdy różne klasy nakładają się w przestrzeni cech, co utrudnia ich rozróżnienie. W obszarach takich jak wykrywanie oszustw, diagnoza medyczna, wykrywanie usterek i anomalii, właśnie te przykłady z mniejszości są najważniejsze, a ich błędna klasyfikacja może być kosztowna lub niebezpieczna. Autorzy stawiają swoje rozwiązanie w kontekście tego podwójnego wyzwania: nierównych rozmiarów klas i nakładających się granic w złożonych, wysokowymiarowych danych.
Sprytniejszy zespół klasyfikatorów
Zamiast polegać na jednym modelu, autorzy budują zespół — ensemble — klasyfikatorów typu SVM (support vector machine), z których każdy patrzy na dane w nieco inny sposób (tzw. jądra). Kluczową ideą jest uczynienie tego zespołu dynamicznym i świadomym lokalnie. Najpierw dane są starannie wstępnie przetworzone: cechy są znormalizowane, by były porównywalne, a technika SMOTE jest użyta do generowania dodatkowych syntetycznych przykładów dla niedoreprezentowanych klas, wyrównując zbiory treningowe. 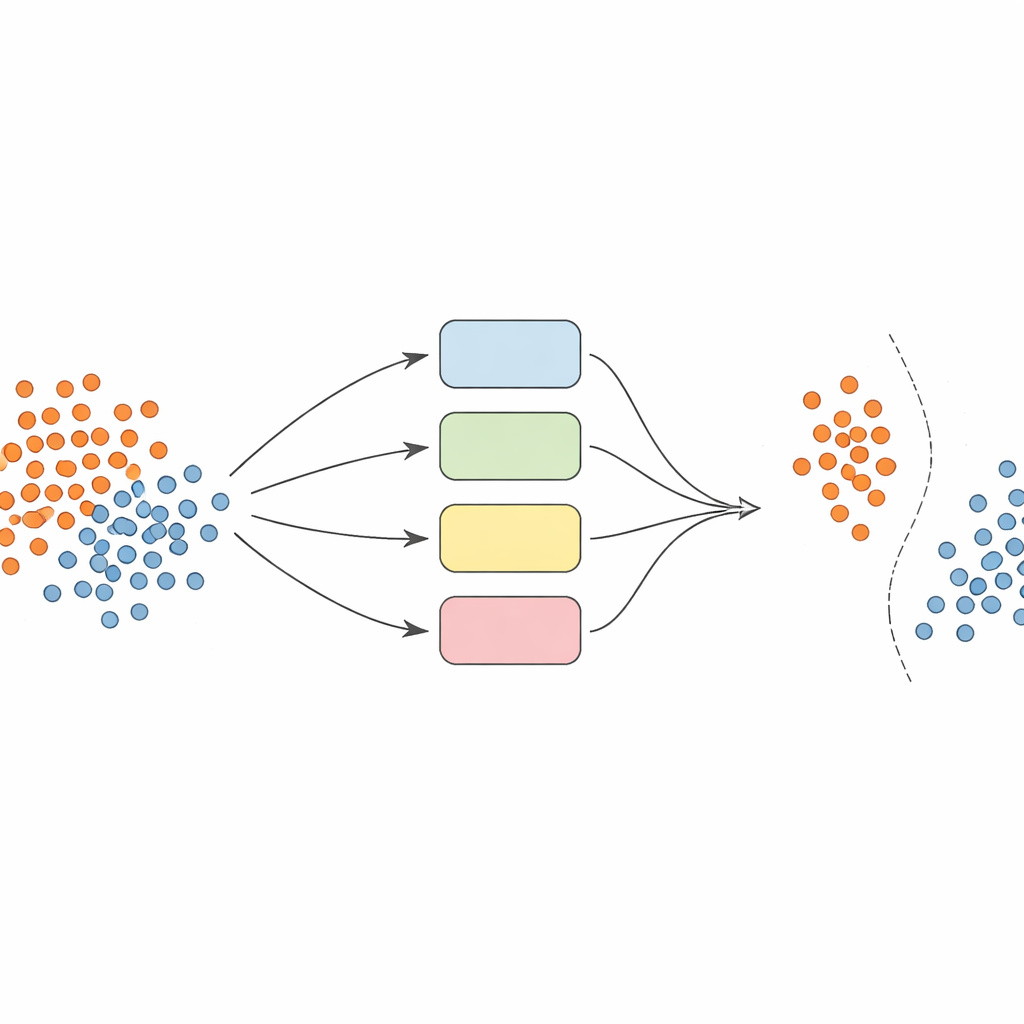
Nauczanie modeli koncentracji na zamazanych granicach
Rdzeniem podejścia jest nowe „jądro świadome granicy”, które celowo skupia wysiłek na obszarach, gdzie klasy się nakładają. Podczas treningu metoda wyszukuje próbki znajdujące się w niejednoznacznych sąsiedztwach, mierząc to odległościami do najbliższych sąsiadów. Takie nakładające się próbki otrzymują specjalne traktowanie: każda z nich służy do trenowania SVM-ów, których funkcja jądra jest modyfikowana przez wagę odzwierciedlającą, jak informatywna jest ta próbka lokalnie. Próbkom z klas mniejszości znajdującym się blisko granicy decyzyjnej przypisuje się wyższe wagi, podczas gdy próbki większościowe w tych strefach są osłabiane wagowo. W efekcie metoda „rozciąga” powierzchnię decyzyjną wokół rzadkich, ale istotnych punktów, pomagając wyznaczyć wyraźniejszą granicę między klasami bez sztucznego generowania nadmiernej ilości danych. 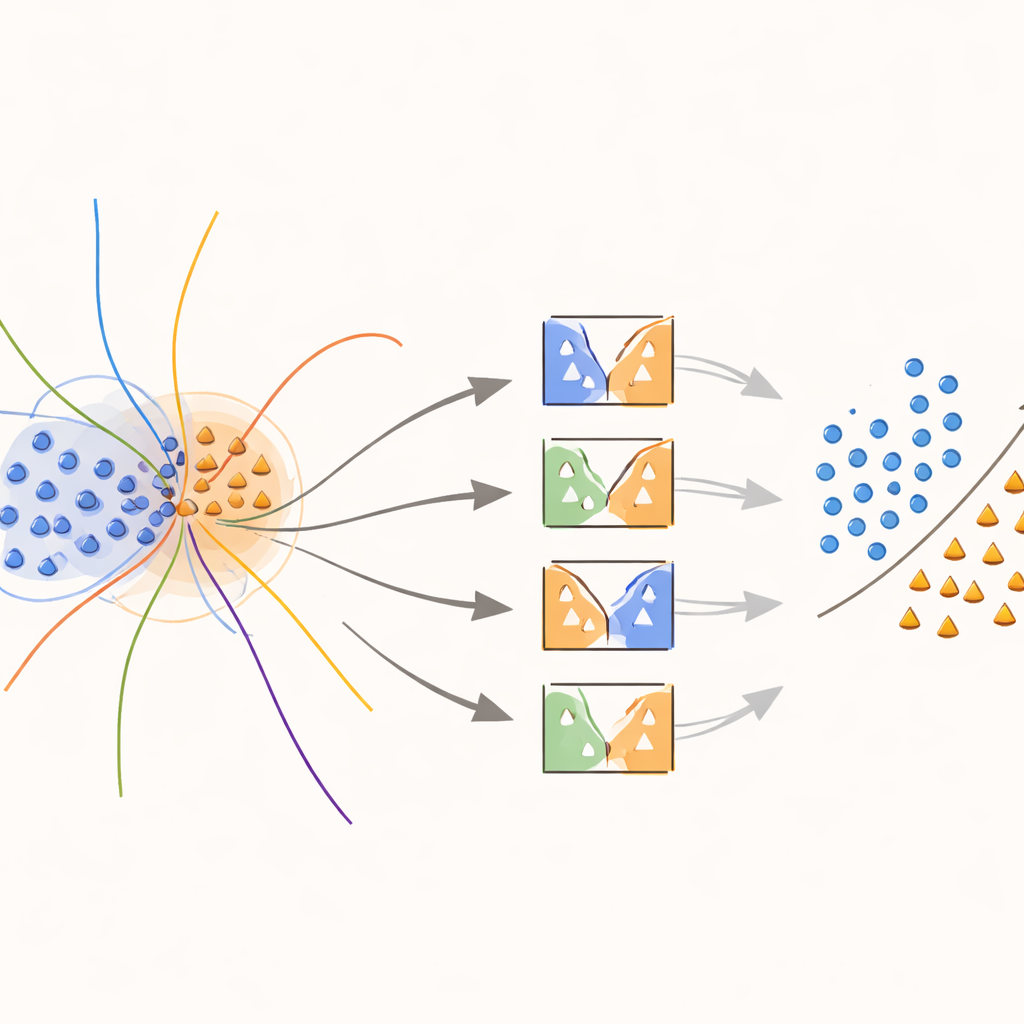
Wybór właściwych ekspertów dla każdej predykcji
Gdy przychodzi czas przewidzieć klasę nowego przykładu, system nie uśrednia bezmyślnie opinii wszystkich modeli. Zamiast tego najpierw spogląda na pobliskie próbki walidacyjne — przypadki, które już widział — i ocenia, jak kompetentny jest każdy klasyfikator w tym lokalnym regionie. Tylko najlepiej sprawdzający się ułamek modeli, te które historycznie dobrze radziły sobie z podobnymi przykładami, mogą głosować. Ich skonsolidowana decyzja determinuje ostateczną predykcję. Ten dobór modeli zależny od instancji utrzymuje koszty obliczeniowe na rozsądnym poziomie, jednocześnie zapewniając, że każda decyzja jest oparta na modelach, które najlepiej rozumieją dany zakątek przestrzeni danych.
Na ile to działa w praktyce?
Aby przetestować swoją metodę, badacze przeprowadzili eksperymenty na 20 zbiorach wieloklasowych i 20 binarnych ze publicznego repozytorium, obejmujących różne zadania, takie jak diagnoza medyczna, ocena jakości i rozpoznawanie wzorców. Porównali swoje dynamiczne ensemble z silnymi punktami odniesienia, w tym zmodyfikowanym SVM połączonym z popularną techniką AdaBoost. W przekroju zbiorów nowe podejście konsekwentnie osiągało wyższą ogólną dokładność i lepszą równowagę między prawidłowym rozpoznawaniem klas większościowych i mniejszościowych, mierzoną statystyką zwaną G‑mean. W wielu benchmarkach utrzymywało też konkurencyjną precyzję, co oznacza, że unikało sygnalizowania zbyt wielu fałszywych alarmów, a jednocześnie skuteczniej wychwytywało rzadkie przypadki.
Co to oznacza dla decyzji w świecie rzeczywistym
Dla osób niezajmujących się specjalistycznie tematem kluczowy wniosek jest taki, że autorzy zaprojektowali uważniejszy i bardziej adaptacyjny sposób, w jaki algorytmy słuchają „cichych głosów” w danych. Poprzez jednoczesne podejście do skośnych rozkładów klas i zamazanych granic oraz przez dopuszczanie do głosu tylko najbardziej odpowiednich modeli przy każdej decyzji, ich ramy zmniejszają ryzyko przeoczenia rzadkich, lecz istotnych zdarzeń. To czyni metodę szczególnie obiecującą w zastosowaniach, gdzie pominięcie nietypowego przypadku — oszukańczej transakcji, uszkodzonego komponentu czy wczesnego sygnału choroby — ma znacznie większe konsekwencje niż błędna klasyfikacja zwykłego przypadku.
Cytowanie: Abokadr, S., Azman, A., Hamdan, H. et al. Kernel-based dynamic ensemble approach for classifying imbalanced data with overlapping classes. Sci Rep 16, 13789 (2026). https://doi.org/10.1038/s41598-026-42940-y
Słowa kluczowe: dane niezrównoważone, nakładające się klasy, uczenie zespołowe, maszyny wektorów nośnych, wykrywanie oszustw i anomalii