Clear Sky Science · sv
Kernelbaserat dynamiskt ensemble‑tillvägagångssätt för klassificering av obalanserade data med överlappande klasser
Varför sällsynta fall i data är viktiga
Många beslut i det moderna livet — från att upptäcka ett bedrägligt kreditkortsköp till att fånga ett tidigt tecken på sjukdom — förlitar sig på algoritmer som lär av historiska data. I de flesta verkliga datamängder är viktiga händelser dock sällsynta: bara ett fåtal transaktioner är bedrägliga, bara ett fåtal patienter är allvarligt sjuka. Dessa sällsynta fall kan lätt dränkas av mängden vanliga exempel, och det blir ännu svårare när mönstren för ”normalt” och ”onormalt” ser mycket lika ut. Denna artikel presenterar ett nytt sätt att träna maskininlärningssystem så att de ägnar särskild, intelligent uppmärksamhet åt dessa svårupptäckta, lättförbisedda fall.
När vanliga exempel döljer de avgörande
I många datamängder överväger en klass av exempel de andra kraftigt — till exempel tusentals säkra transaktioner för varje bedräglig. Standardalgoritmer försöker maximera den övergripande noggrannheten och fokuserar därför på majoriteten och ignorerar minoriteten. Problemet förvärras när de olika klasserna överlappar i sina observerade egenskaper, vilket gör dem svåra att särskilja. Inom områden som bedrägeridetektion, medicinsk diagnostik, felupptäckt och avvikelsesökning är dessa minoritetsexempel precis de vi bryr oss mest om, och felklassificering kan vara kostsamt eller farligt. Författarna ramar in sitt arbete kring denna dubbla utmaning: ojämna klassstorlekar och överlappande gränser i komplexa, högdimensionella data.
Ett smartare team av klassificerare
I stället för att förlita sig på en enda modell bygger författarna ett team — eller ensemble — av supportvektormaskiner (SVM), där varje modell använder olika sätt att betrakta data (så kallade kernel‑funktioner). Nyckelidén är att göra denna ensemble dynamisk och lokalt medveten. Först förbehandlas data noggrant: funktioner normaliseras så att de ligger på jämförbar skala, och en teknik kallad SMOTE används för att generera ytterligare syntetiska exempel för underrepresenterade klasser och balansera träningsuppsättningarna. 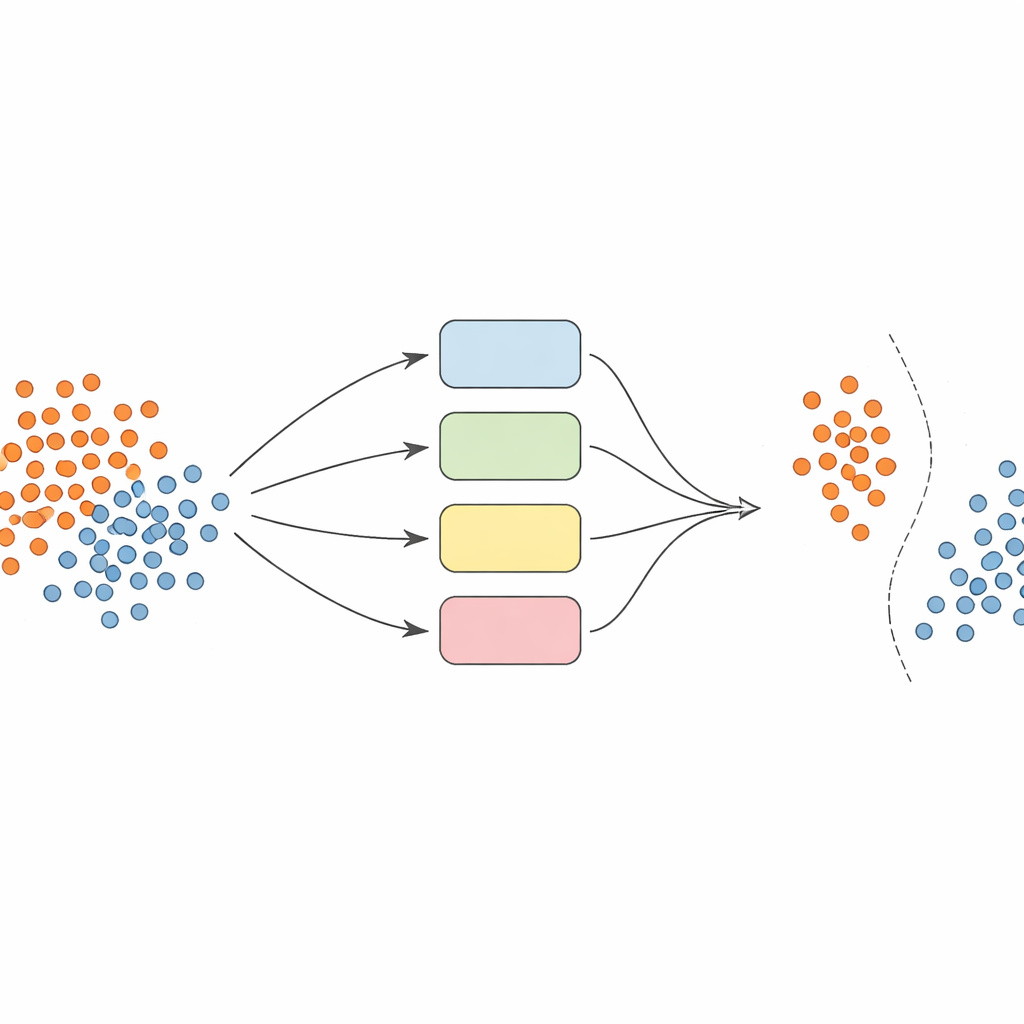
Lära modeller att fokusera på suddiga gränser
Kärnan i tillvägagångssättet är en ny ”gränsmedveten” kernel som avsiktligt koncentrerar insatsen på områden där klasser överlappar. Under träningen letar metoden efter prover som befinner sig i tvetydiga grannskap, mätt genom avstånd till närmaste grannar. Dessa överlappande prov ges särskild behandling: varje sådant prov används för att träna SVM:er vars kernel‑funktion modifieras med en vikt som fångar hur informativt provet är lokalt. Minoritetsklassprover nära beslutgränsen tilldelas högre vikter, medan majoritetsklassprover i samma zoner nedviktas. I praktiken sträcker metoden ut beslutytan runt sällsynta men viktiga punkter, vilket hjälper till att dra en tydligare skiljelinje mellan klasser utan att skapa mer data än nödvändigt. 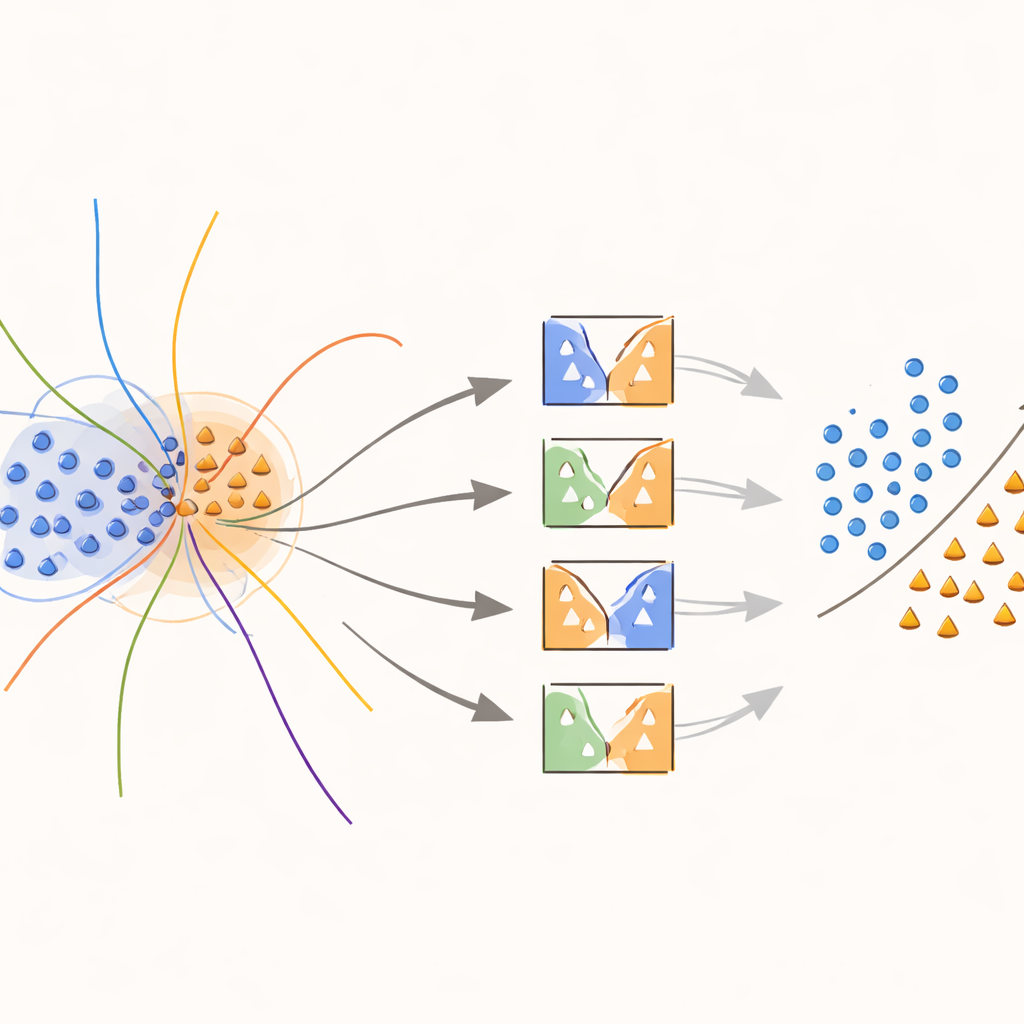
Välja rätt experter för varje förutsägelse
När det är dags att förutsäga klassen för ett nytt exempel tar systemet inte blint genomsnittet av alla modellernas åsikter. I stället tittar det först på närliggande valideringsprover — fall det redan sett — och uppskattar hur kompetent varje klassificerare är i den lokala regionen. Endast den toppresterande andelen modeller, de som historiskt hanterat liknande exempel väl, tillåts rösta. Deras kombinerade beslut avgör slutgiltig förutsägelse. Denna instansberoende modellurval håller beräkningen hanterbar samtidigt som det säkerställs att varje beslut informeras av de modeller som förstår just den delen av datastrummet bäst.
Hur väl fungerar det i praktiken?
För att testa sin metod genomförde forskarna experiment på 20 flerklass‑ och 20 binära datamängder från ett offentligt arkiv, vilket täckte skilda uppgifter som medicinsk diagnostik, kvalitetsbedömning och mönsterigenkänning. De jämförde sin dynamiska ensemble med starka referensmetoder, inklusive en modifierad SVM kombinerad med den populära AdaBoost‑tekniken. Över datamängderna uppnådde det nya tillvägagångssättet konsekvent högre total noggrannhet och bättre balans mellan korrekt igenkänning av majoritets‑ och minoritetsklasser, mätt med en statistisk måttstock kallad G‑mean. I många benchmarktester höll det också konkurrenskraftig precision, vilket innebär att det undvek att flagga alltför många falska larm samtidigt som det fångade sällsynta fall mer effektivt.
Vad detta betyder för verkliga beslut
För icke‑specialister är slutsatsen att författarna utformat ett mer uppmärksamt och anpassningsbart sätt för algoritmer att lyssna på datans ”tysta röster”. Genom att gemensamt hantera snedfördelade klassstorlekar och suddiga gränser, och genom att låta endast de mest relevanta modellerna tala i varje beslut, minskar deras ramverk risken att sällsynta men viktiga händelser förbises. Detta gör metoden särskilt lovande för tillämpningar där det att missa ett ovanligt fall — en bedräglig transaktion, en felande komponent eller ett tidigt sjukdomstecken — betyder mycket mer än att felklassificera ett vanligt exempel.
Citering: Abokadr, S., Azman, A., Hamdan, H. et al. Kernel-based dynamic ensemble approach for classifying imbalanced data with overlapping classes. Sci Rep 16, 13789 (2026). https://doi.org/10.1038/s41598-026-42940-y
Nyckelord: obalanserade data, överlappande klasser, ensembleinlärning, supportvektormaskiner, bedrägeri- och avvikelsedetektion