Clear Sky Science · it
Approccio ensemble dinamico basato su kernel per classificare dati sbilanciati con classi sovrapposte
Perché i casi rari nei dati contano
Molte decisioni nella vita moderna — dallo scovare un acquisto fraudolento con carta di credito al cogliere un segnale precoce di malattia — dipendono da algoritmi che apprendono dai dati passati. Ma nella maggior parte dei dataset reali, gli eventi importanti sono rari: solo alcune transazioni sono fraudolente, solo pochi pazienti sono gravemente malati. Questi casi rari possono facilmente essere sommersi dalla massa di esempi ordinari, e la situazione peggiora quando i modelli di “normale” e “anormale” sono molto simili. Questo articolo presenta un nuovo modo di addestrare sistemi di machine learning in modo che prestino attenzione speciale e intelligente a questi casi difficili da vedere e facili da perdere.
Quando gli esempi comuni nascondono quelli cruciali
In molti dataset, una classe di esempi supera di gran lunga le altre — per esempio, migliaia di transazioni sicure per ogni transazione fraudolenta. Gli algoritmi standard cercano di massimizzare l’accuratezza complessiva, quindi finiscono per concentrarsi sulla maggioranza e ignorare la minoranza. Il problema si complica quando le diverse classi si sovrappongono nelle caratteristiche misurate, rendendole difficili da distinguere. In ambiti come il rilevamento delle frodi, la diagnosi medica, l’individuazione di guasti e il riconoscimento di anomalie, questi esempi di minoranza sono proprio quelli che ci interessano di più, e classificarli erroneamente può essere costoso o pericoloso. Gli autori inquadrano il loro lavoro attorno a questa doppia sfida: dimensioni delle classi diseguali e confini sovrapposti in dati complessi e ad alta dimensionalità.
Una squadra di classificatori più intelligente
Invece di fare affidamento su un singolo modello, gli autori costruiscono una squadra — o ensemble — di classificatori support vector machine (SVM), ognuno dei quali usa diversi modi di guardare i dati (chiamati kernel). L’idea chiave è rendere questo ensemble dinamico e consapevole del contesto locale. Innanzitutto i dati sono accuratamente preprocessati: le feature vengono normalizzate per porle su scale comparabili, e una tecnica chiamata SMOTE è usata per generare esempi sintetici aggiuntivi per le classi sottorappresentate, bilanciando i set di addestramento. 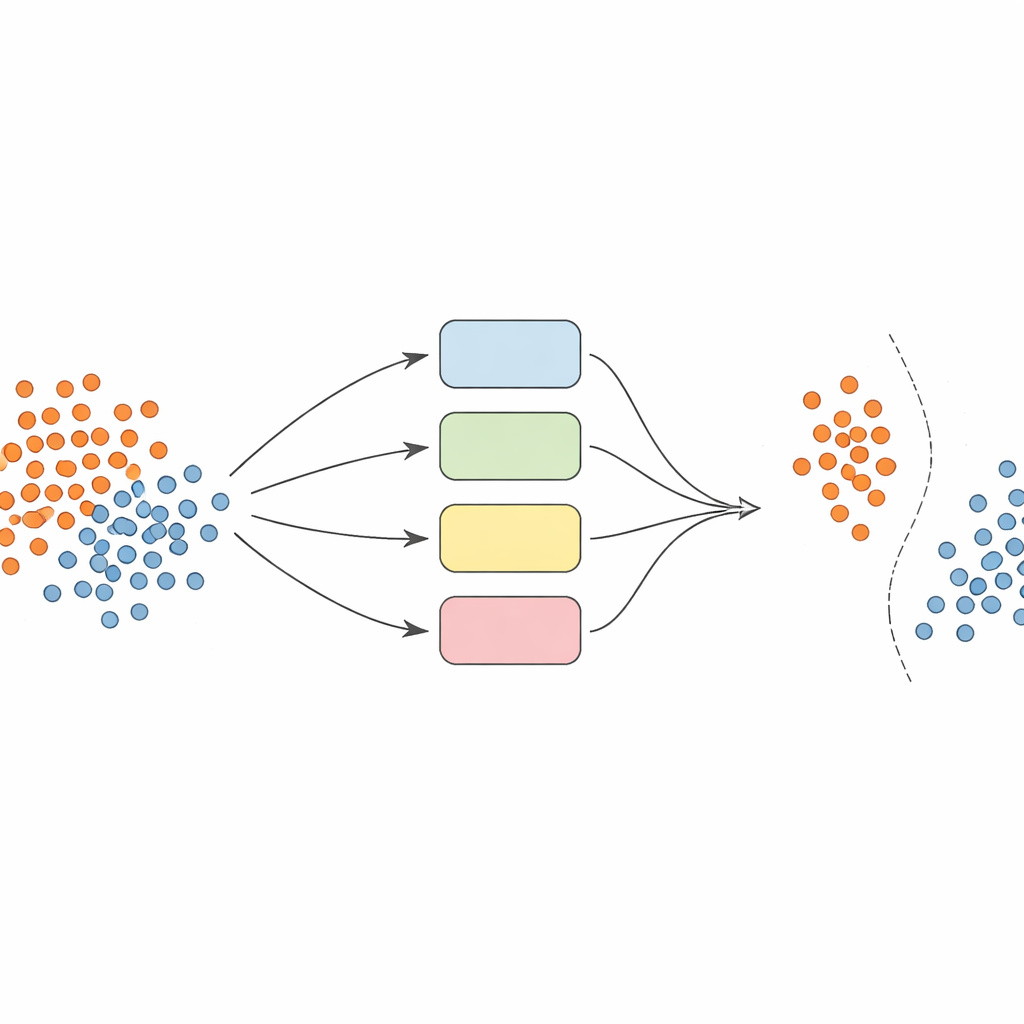
Insegnare ai modelli a concentrarsi sui confini sfumati
Il cuore dell’approccio è un nuovo kernel “consapevole del confine” che concentra intenzionalmente gli sforzi sulle regioni dove le classi si sovrappongono. Durante l’addestramento, il metodo cerca campioni che si trovano in vicinanze ambigue, misurate dalle distanze ai loro vicini più prossimi. Questi campioni sovrapposti ricevono quindi un trattamento speciale: ciascuno viene usato per addestrare SVM il cui kernel è modificato da un peso che cattura quanto quel campione sia informativo a livello locale. I campioni della classe minoritaria vicini al confine decisionale ricevono pesi più alti, mentre i campioni della classe maggioritaria in quelle zone vengono ridimensionati al ribasso. Di fatto, il metodo estende la superficie decisionale attorno a punti rari ma importanti, aiutando a tracciare una linea più netta tra le classi senza inventare più dati del necessario. 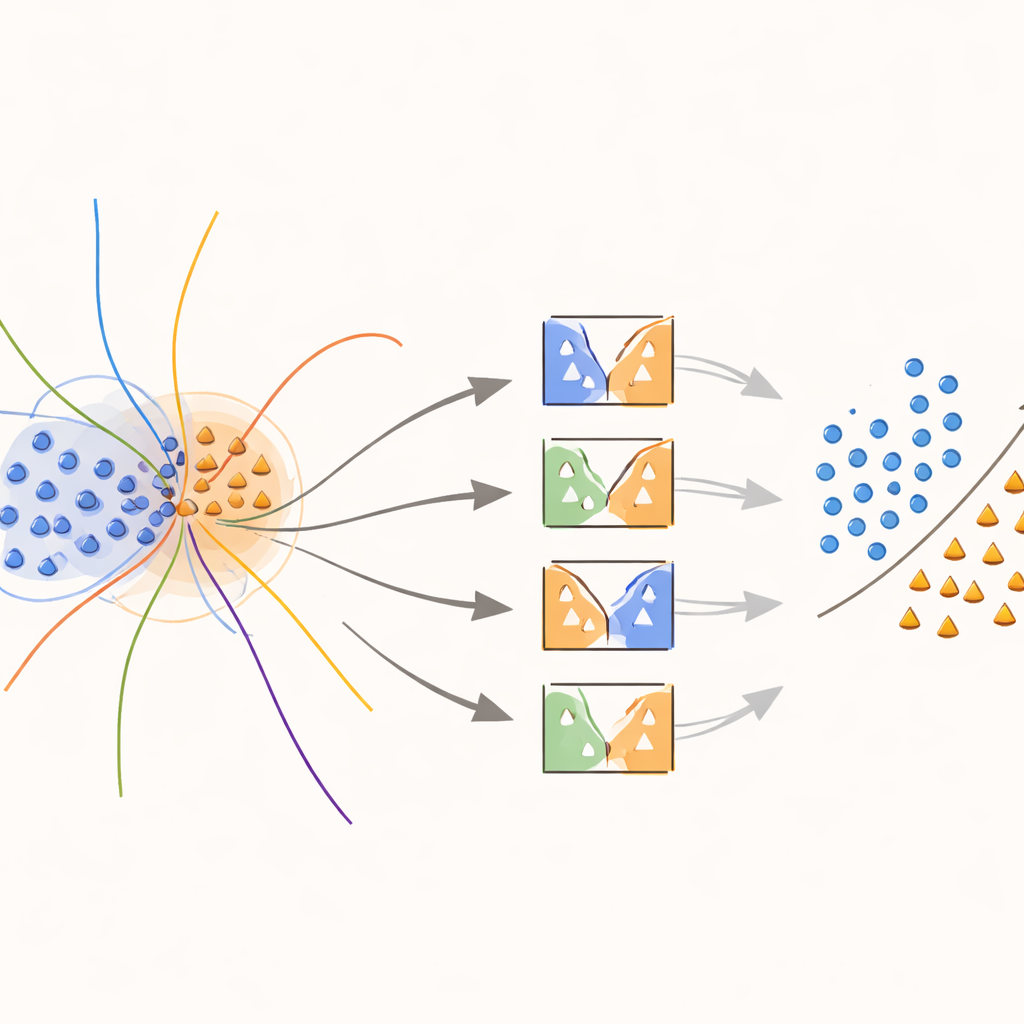
Scegliere gli esperti giusti per ogni previsione
Quando è il momento di prevedere la classe di un nuovo esempio, il sistema non media ciecamente le opinioni di tutti i modelli. Invece, osserva prima i campioni di validazione vicini — casi che ha già visto — e stima quanto sia competente ciascun classificatore in quella regione locale. Solo la frazione di modelli con le migliori prestazioni, quelli che storicamente hanno gestito bene esempi simili, è autorizzata a votare. La loro decisione combinata determina la previsione finale. Questa selezione di modelli dipendente dall’istanza mantiene il calcolo gestibile assicurando che ogni decisione sia informata dai modelli che comprendono meglio quello specifico angolo dello spazio dei dati.
Quanto funziona in pratica?
Per testare il loro metodo, i ricercatori hanno condotto esperimenti su 20 dataset multi‑classe e 20 binari presi da un repository pubblico, coprendo compiti diversi come diagnosi medica, valutazione della qualità e riconoscimento di pattern. Hanno confrontato il loro ensemble dinamico con solide baseline, inclusa una SVM modificata combinata con la popolare tecnica AdaBoost. Attraverso i dataset, il nuovo approccio ha costantemente raggiunto maggiore accuratezza complessiva e un miglior equilibrio tra il riconoscimento corretto delle classi di maggioranza e di minoranza, misurato da una statistica chiamata G‑mean. In molti benchmark ha mantenuto anche una precisione competitiva, cioè ha evitato di segnalare troppi falsi allarmi pur catturando i casi rari in modo più efficace.
Cosa significa per le decisioni nel mondo reale
Per i non specialisti, il punto è che gli autori hanno progettato un modo più attento e adattabile affinché gli algoritmi ascoltino le “voci calme” nei dati. Affrontando congiuntamente scale di classe sbilanciate e confini sfumati, e permettendo solo ai modelli più rilevanti di esprimersi per ogni decisione, il loro quadro riduce la probabilità che eventi rari ma cruciali vengano trascurati. Ciò lo rende particolarmente promettente per applicazioni in cui perdere un caso insolito — una transazione fraudolenta, un componente in guasto o un segno precoce di malattia — conta molto più che classificare erroneamente un caso ordinario.
Citazione: Abokadr, S., Azman, A., Hamdan, H. et al. Kernel-based dynamic ensemble approach for classifying imbalanced data with overlapping classes. Sci Rep 16, 13789 (2026). https://doi.org/10.1038/s41598-026-42940-y
Parole chiave: dati sbilanciati, classi sovrapposte, apprendimento ensemble, macchine a vettori di supporto, rilevamento frodi e anomalie