Clear Sky Science · ja
クラスが重なり合う不均衡データの分類のためのカーネルベース動的アンサンブル手法
データ中の稀な事例が重要な理由
不正なクレジットカード取引の発見から病気の早期兆候の検出まで、現代の多くの意思決定は過去のデータから学ぶアルゴリズムに依存しています。しかし実世界のほとんどのデータセットでは、重要な事象は稀です:不正取引はごく一部、重篤な患者もごく少数しかいません。こうした稀な事例は多数の通常例に埋もれやすく、さらに「正常」と「異常」のパターンが非常によく似ていると状況は一層難しくなります。本論文は、こうした見つけにくく見落とされがちな事例に対して、賢く重点を置いて学習する新しい機械学習の訓練法を紹介します。
一般例が重要な例を隠してしまうとき
多くのデータセットでは、あるクラスの例が他を圧倒的に上回ります—たとえば、不正取引1件に対して安全な取引が何千件というように。標準的なアルゴリズムは全体の精度を最大化しようとするため、結果として多数派に注目し少数派を無視してしまいます。問題は、異なるクラスが測定された特徴空間で重なり合っているときにさらに厄介になります。詐欺検出、医療診断、故障検知、異常検出のような分野では、少数派の事例こそが最も重要であり、それらを誤分類することはコストや危険を招く可能性があります。著者らは、本研究を不均衡なクラスサイズと高次元データにおける重なり合う境界という二重の課題のもとで位置づけています。
賢い分類器のチーム
単一モデルに頼る代わりに、著者らは複数のサポートベクターマシン(SVM)分類器からなるチーム、すなわちアンサンブルを構築します。各モデルはデータを異なる見方(カーネル)で見るようにします。重要なアイデアは、このアンサンブルを動的かつ局所的に認識させることです。まずデータを慎重に前処理します:特徴量を比較可能なスケールに正規化し、SMOTEと呼ばれる手法で少数クラスの合成例を生成して訓練セットをバランスさせます。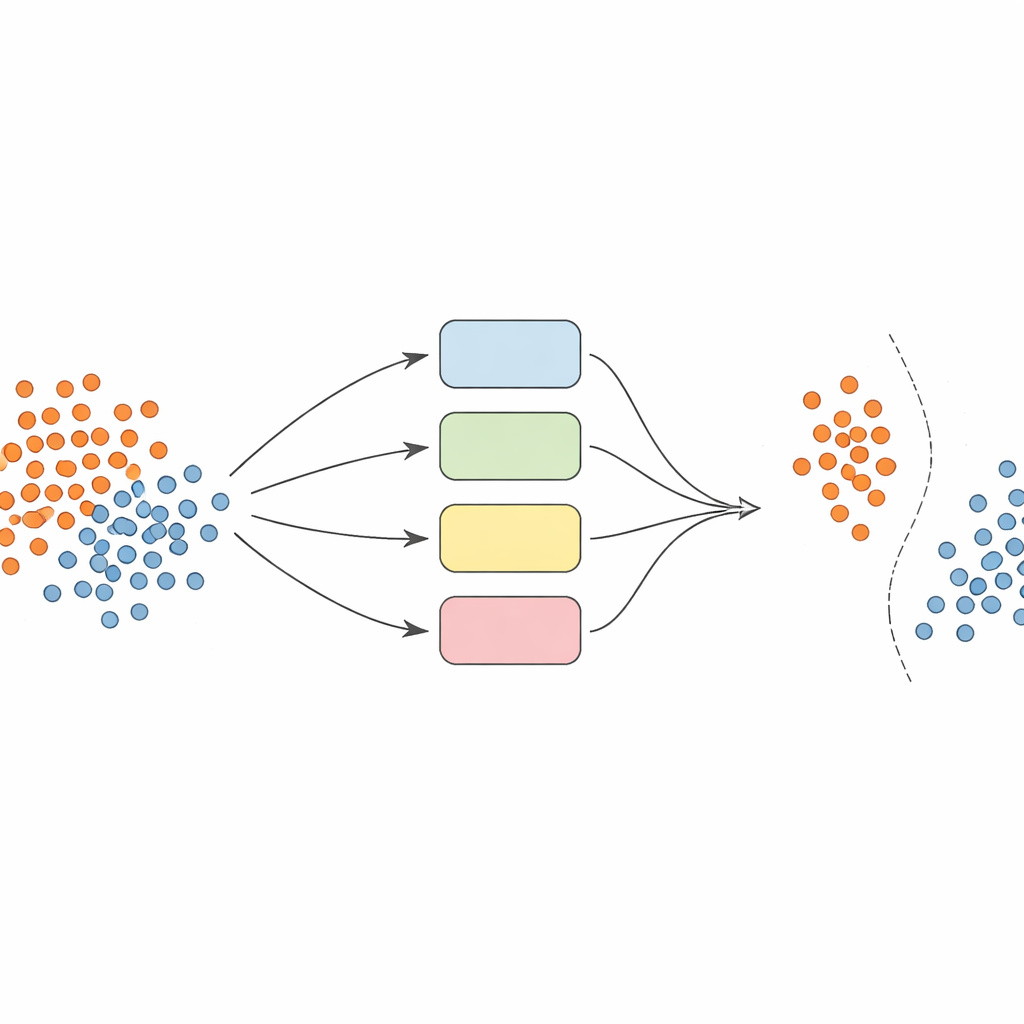
あいまいな境界に注目させる学習
本手法の核心は、「境界認識」カーネルという新しいカーネルで、クラスが重なり合う領域に意図的に注力します。訓練中、手法は最近傍までの距離で測った曖昧な近傍に位置するサンプルを探します。こうした重なり合うサンプルには特別な扱いがなされ、それぞれが局所的にどれだけ情報を持つかを表す重みでカーネル関数を修正したSVMの訓練に用いられます。決定境界付近の少数クラスのサンプルには高い重みが与えられ、同じ領域にある多数クラスのサンプルは重みを下げられます。結果として、この手法は稀だが重要な点の周りで決定面を引き伸ばし、必要以上にデータを生成することなくクラス間の線引きを明瞭にします。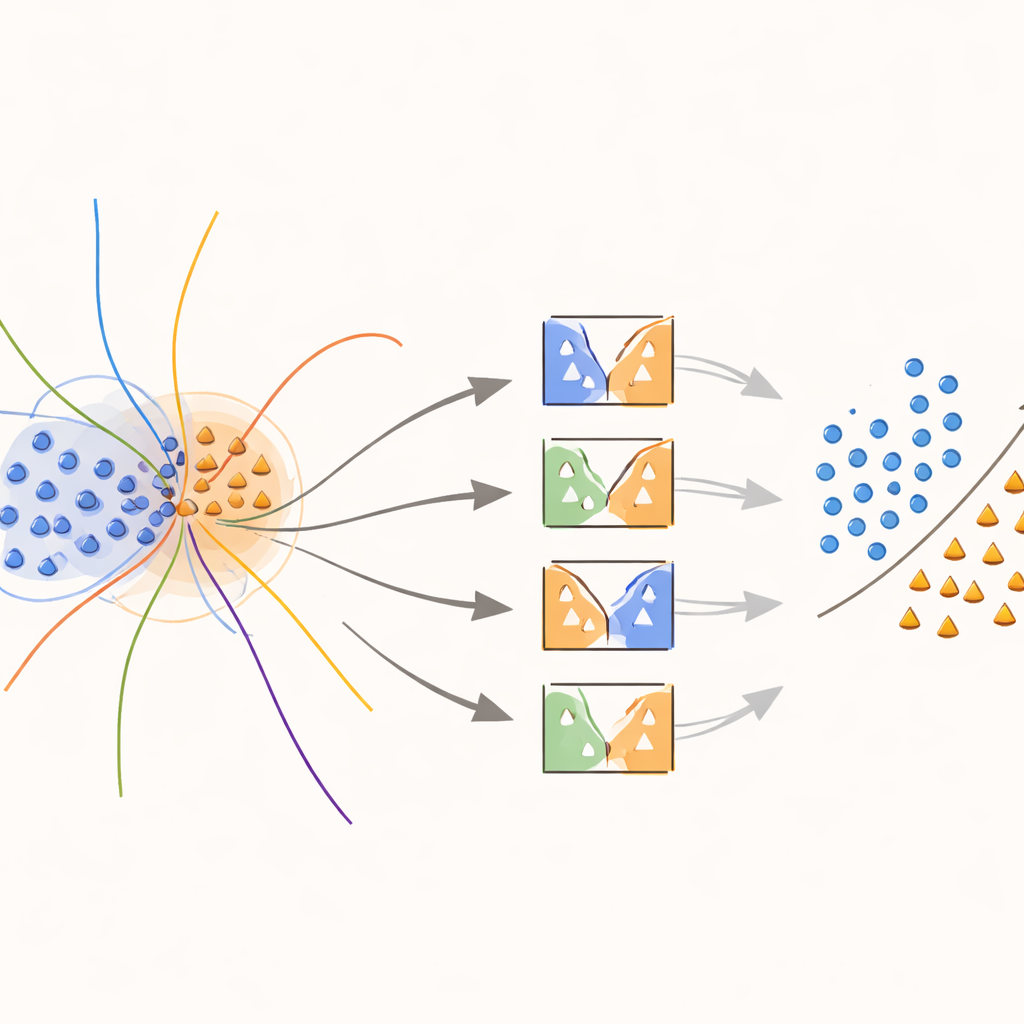
各予測に適した専門家を選ぶ
新しい例のクラスを予測する際、システムはすべてのモデルの意見を盲目的に平均しません。代わりにまず近傍の検証サンプル—既に見たことのある事例—を見て、その局所領域で各分類器がどれほど有能かを推定します。類似の例をうまく扱ってきた上位のモデル群のみが投票を許されます。これらの選ばれたモデルの結合判断が最終予測を決定します。この事例依存のモデル選択により、計算負荷を抑えつつ、それぞれの判断がそのデータ空間の特定の領域を最もよく理解するモデルによって支えられるようになります。
実際の性能はどれほどか
手法を検証するため、研究者らは公開リポジトリから取得した20の多クラスデータセットと20の二値データセットを用いて実験を行いました。対象は医療診断、品質評価、パターン認識など多岐にわたります。彼らは提案する動的アンサンブルを、改良版SVMと広く使われるAdaBoost手法を組み合わせた強力なベースラインなどと比較しました。データセット全体で、新手法は総合精度と多数派・少数派クラスの両方の認識バランスを示すG‑meanという統計量で一貫して高い成績を示しました。多くのベンチマークでは精度(precision)も競争力を維持しており、誤検知を過度に出すことなく稀な事例をより効果的に捕捉していました。
現実世界の意思決定への意味
専門外の読者への要点は、著者らがデータ中の「静かな声」に対してより注意深く適応的に耳を傾ける方法を設計したことです。不均衡なクラスサイズとあいまいな境界を同時に扱い、各判断に最も関連のあるモデルだけを選んで用いることで、本手法は稀ではあるが重要な事象が見落とされる可能性を減らします。これは、異常な事例—不正取引、故障しつつある部品、病気の初期兆候—を見落とすことが通常の誤分類よりもはるかに重大となる応用において、特に有望です。
引用: Abokadr, S., Azman, A., Hamdan, H. et al. Kernel-based dynamic ensemble approach for classifying imbalanced data with overlapping classes. Sci Rep 16, 13789 (2026). https://doi.org/10.1038/s41598-026-42940-y
キーワード: 不均衡データ, 重なり合うクラス, アンサンブル学習, サポートベクターマシン, 不正検出と異常検知