Clear Sky Science · tr
Sınıfları örtüşen dengesiz verileri sınıflandırmak için çekirdek tabanlı dinamik topluluk yaklaşımı
Veride nadir durumlar neden önemli
Modern hayattaki pek çok karar —sahte bir kredi kartı işlemini görmekten bir hastalığın erken belirtisini yakalamaya kadar— geçmiş verilerden öğrenen algoritmalara dayanır. Ancak gerçek dünya veri kümelerinin çoğunda önemli olaylar nadirdir: sadece birkaç işlem sahte olabilir, sadece birkaç hasta ciddi derecede hasta olabilir. Bu nadir durumlar sıradan örneklerin çoğunluğu arasında kolayca gözden kaçabilir ve “normal” ile “anormal” örüntüler çok benzer görünüyorsa iş daha da zorlaşır. Bu makale, makine öğrenmesi sistemlerini bu zor görünen, kolay kaçırılan durumlara özel ve akıllı bir biçimde dikkat etmeye yönlendiren yeni bir eğitim yöntemi sunar.
Yaygın örnekler kritik olanları nasıl gizler
Birçok veri kümesinde bir sınıf diğerlerini büyük ölçüde aşar—örneğin her sahte işlem için binlerce güvenli işlem olabilir. Standart algoritmalar genel doğruluğu maksimize etmeye çalıştıkları için çoğunluğa odaklanır ve azınlığı görmezden gelirler. Farklı sınıflar ölçülen özellikler açısından örtüştüğünde, onları ayırt etmek daha da zorlaşır. Dolandırıcılık tespiti, tıbbi tanı, arıza tespiti ve anomali bulma gibi alanlarda bu azınlık örnekleri tam da en çok önem verdiğimiz örneklerdir ve bunların yanlış sınıflandırılması maliyetli veya tehlikeli olabilir. Yazarlar çalışmalarını bu çift zorluk etrafında kurgular: dengesiz sınıf büyüklükleri ve karmaşık, yüksek boyutlu verilerde örtüşen sınırlar.
Daha akıllı bir sınıflayıcı takımı
Tek bir modele güvenmek yerine yazarlar, veriye farklı bakış açıları (çekirdekler) kullanan bir destek vektör makineleri (SVM) topluluğu—yani bir ensemble—oluştururlar. Temel fikir bu topluluğu dinamik ve yerel olarak bilinçli hale getirmektir. Önce veriler dikkatli şekilde ön işleme tabi tutulur: özellikler karşılaştırılabilir bir ölçeğe getirilir ve az temsil edilen sınıflar için ek sentetik örnekler üretmek üzere SMOTE adlı teknik kullanılarak eğitim setleri dengelenir. 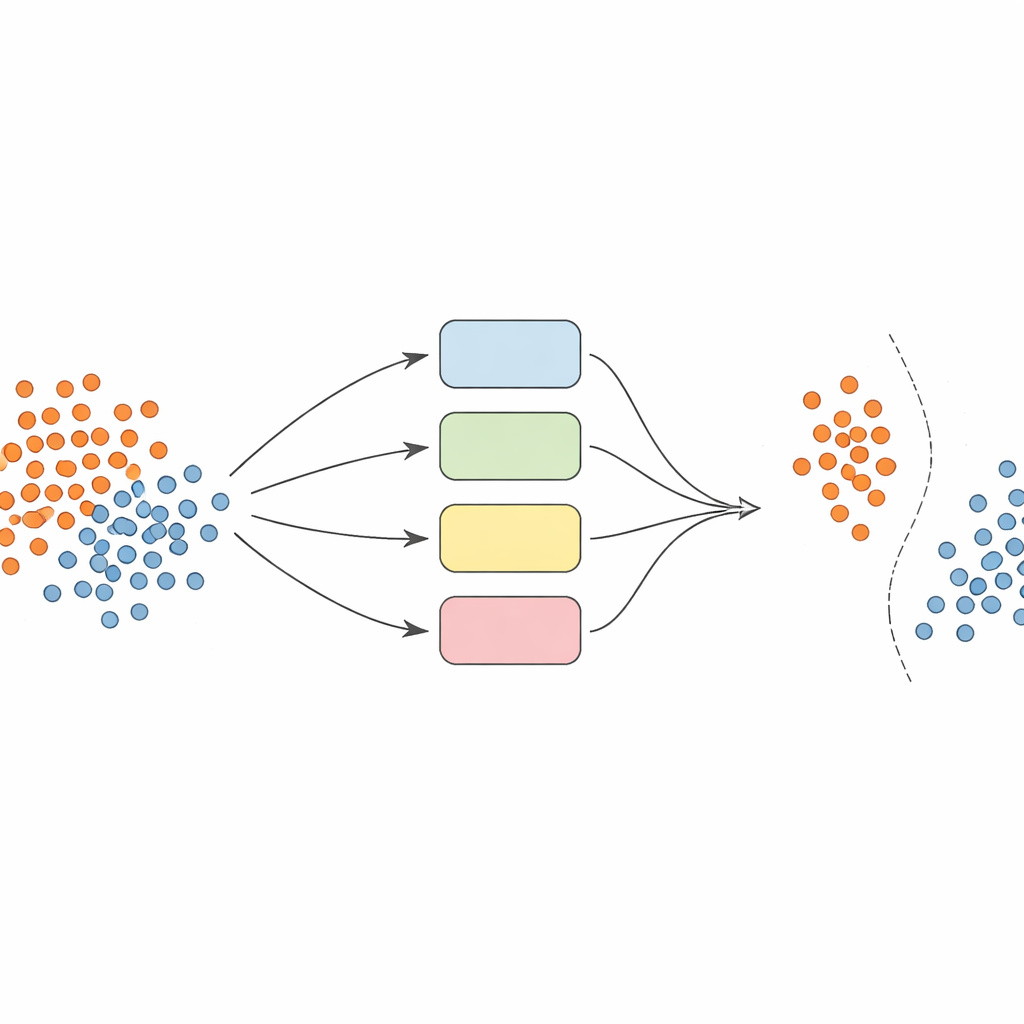
Modelleri belirsiz sınırlara odaklanmaya öğretmek
Yaklaşımın özünde sınıfların örtüştüğü bölgelere kasıtlı olarak yoğunlaşan yeni bir “sınır‑bilinçli” çekirdek vardır. Eğitim sırasında yöntem, en yakın komşularına olan uzaklıklarla ölçülen belirsiz mahallelerde bulunan örnekleri arar. Bu örtüşen örnekler özel muamele görür: her biri, o örneğin yerel olarak ne kadar bilgilendirici olduğunu yakalayan bir ağırlıkla değiştirilmiş çekirdek fonksiyonu kullanılarak SVM’leri eğitmek için kullanılır. Karar sınırına yakın azınlık sınıfı örneklerine daha yüksek ağırlık verilirken, o bölgelerdeki çoğunluk sınıfı örneklerinin ağırlığı azaltılır. Sonuç olarak yöntem, nadir ama önemli noktalardan etrafında karar yüzeyini gererek sınıflar arasında daha net bir çizgi çekmeye yardımcı olur; gereğinden fazla yeni veri icat etmeden bunu gerçekleştirir. 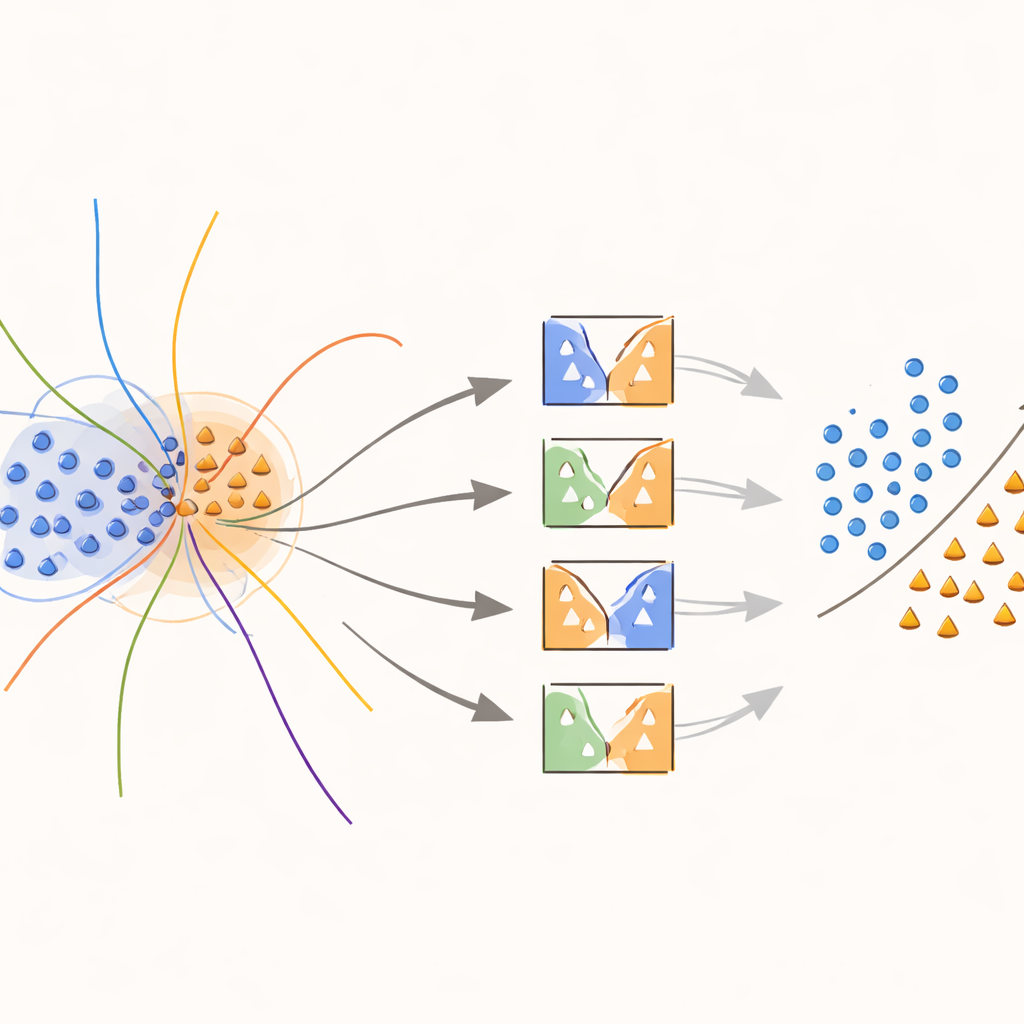
Her tahmin için doğru uzmanları seçmek
Yeni bir örneğin sınıfını tahmin etme zamanı geldiğinde sistem tüm modellerin görüşlerini körü körüne ortalamaz. Bunun yerine önce yakın doğrulama örneklerine—daha önce görmüş olduğu vakalara—bakar ve her sınıflayıcının o yerel bölgede ne kadar yetkin olduğunu tahmin eder. Sadece tarihsel olarak benzer örnekleri iyi işleyen üst performans gösteren model kesimi oy kullanmaya izin verilir. Bu örnek‑bağımlı model seçimi, hesaplamayı yönetilebilir tutarken her kararın veri uzayının o köşesini en iyi anlayan modeller tarafından bilgilendirilmesini sağlar.
Pratikte ne kadar iyi çalışıyor?
Yöntemlerini test etmek için araştırmacılar, tıbbi tanı, kalite değerlendirmesi ve desen tanıma gibi çeşitli görevleri kapsayan halka açık bir depodan alınan 20 çok‑sınıflı ve 20 ikili veri kümesinde deneyler yürüttüler. Dinamik topluluğu güçlü temel yaklaşımlarla, popüler AdaBoost tekniğiyle birleştirilmiş değiştirilmiş bir SVM de dahil olmak üzere karşılaştırdılar. Veri kümeleri genelinde yeni yaklaşım tutarlı biçimde daha yüksek genel doğruluk ve çoğunluk ile azınlık sınıfları arasında doğru tanıma dengesi (G‑mean ile ölçülen) sağladı. Birçok kıyaslamada ayrıca rekabetçi hassasiyet korundu; yani çok fazla yanlış alarma yol açmaktan kaçınırken nadir durumları daha etkili yakalamayı sürdürdü.
Gerçek dünya kararları için ne anlama geliyor
Uzman olmayanlar için çıkarım şudur: yazarlar verideki “sessiz sesleri” daha dikkatli ve uyum sağlayan bir şekilde dinleyecek bir yöntem tasarladılar. Eğik sınıf dağılımlarını ve belirsiz sınırları birlikte ele alarak ve her karar için yalnızca en ilgili modellerin konuşmasına izin vererek, çerçeveleri nadir ama hayati olayların gözden kaçma olasılığını azaltır. Bu, olağandışı bir durumun—sahte bir işlem, arızaya yakın bir bileşen veya bir hastalığın erken belirtisi—kaçırılmasının sıradan bir şeyi yanlış sınıflandırmaktan çok daha önemli olduğu uygulamalar için özellikle umut vericidir.
Atıf: Abokadr, S., Azman, A., Hamdan, H. et al. Kernel-based dynamic ensemble approach for classifying imbalanced data with overlapping classes. Sci Rep 16, 13789 (2026). https://doi.org/10.1038/s41598-026-42940-y
Anahtar kelimeler: dengesiz veri, örtüşen sınıflar, topluluk öğrenmesi, destek vektör makineleri, dolandırıcılık ve anomali tespiti