Clear Sky Science · es
Enfoque dinámico por ensamblado basado en núcleos para clasificar datos desequilibrados con clases solapadas
Por qué importan los casos raros en los datos
Muchas decisiones en la vida moderna —desde detectar una compra fraudulenta con tarjeta hasta identificar una señal temprana de enfermedad— dependen de algoritmos que aprenden de datos pasados. Pero en la mayoría de los conjuntos reales, los acontecimientos importantes son raros: sólo unas pocas transacciones son fraudulentas, sólo unos pocos pacientes están gravemente enfermos. Estos casos poco frecuentes pueden quedar fácilmente enterrados entre la masa de ejemplos ordinarios, y la tarea se complica aún más cuando los patrones de “normal” y “anómalo” se parecen mucho. Este artículo presenta una nueva forma de entrenar sistemas de aprendizaje automático para que presten atención especial e inteligente a estos casos difíciles de ver y fáciles de pasar por alto.
Cuando los ejemplos comunes ocultan los cruciales
En muchos conjuntos de datos, una clase de ejemplos supera con creces a las demás —por ejemplo, miles de transacciones seguras por cada una fraudulenta. Los algoritmos estándar intentan maximizar la precisión global, por lo que acaban centrados en la mayoría e ignorando la minoría. El problema se agrava cuando las diferentes clases se solapan en sus características medidas, lo que dificulta su distinción. En áreas como la detección de fraude, el diagnóstico médico, la detección de fallos y el hallazgo de anomalías, esos ejemplos minoritarios son precisamente los que más nos importan, y su clasificación errónea puede resultar costosa o peligrosa. Los autores enmarcan su trabajo en torno a este doble desafío: tamaños de clase desiguales y fronteras solapadas en datos complejos y de alta dimensión.
Un equipo de clasificadores más inteligente
En lugar de confiar en un único modelo, los autores construyen un equipo —o ensamblado— de clasificadores SVM (máquinas de vectores de soporte), cada uno usando distintas formas de mirar los datos (llamadas núcleos o kernels). La idea clave es hacer que este ensamblado sea dinámico y consciente del entorno local. Primero, los datos se preprocesan con cuidado: las características se normalizan para que estén en una escala comparable, y se emplea una técnica llamada SMOTE para generar ejemplos sintéticos adicionales para las clases poco representadas, equilibrando los conjuntos de entrenamiento. 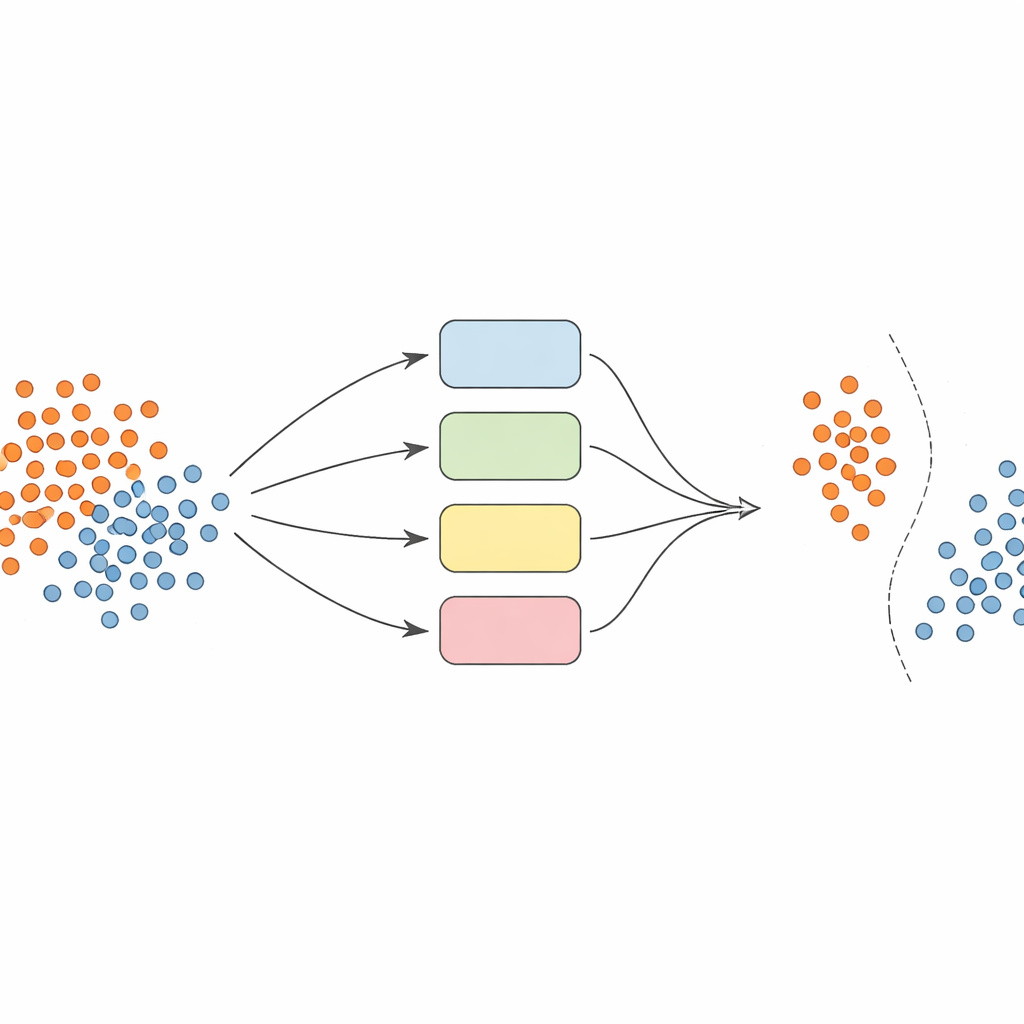
Enseñar a los modelos a centrarse en fronteras difusas
El núcleo del enfoque es un nuevo kernel “consciente de la frontera” que concentra deliberadamente el esfuerzo en las regiones donde las clases se solapan. Durante el entrenamiento, el método busca muestras que se sitúan en vecindarios ambiguos, medidos por distancias a sus vecinos más cercanos. A estas muestras solapadas se les da un tratamiento especial: cada una se usa para entrenar SVM cuyo kernel se modifica mediante un peso que captura cuán informativa es esa muestra a nivel local. Las muestras de la clase minoritaria cerca de la frontera de decisión reciben pesos más altos, mientras que las muestras de la clase mayoritaria en esas zonas se ponderan a la baja. En efecto, el método estira la superficie de decisión alrededor de puntos raros pero importantes, ayudando a trazar una línea más clara entre clases sin inventar más datos de los necesarios. 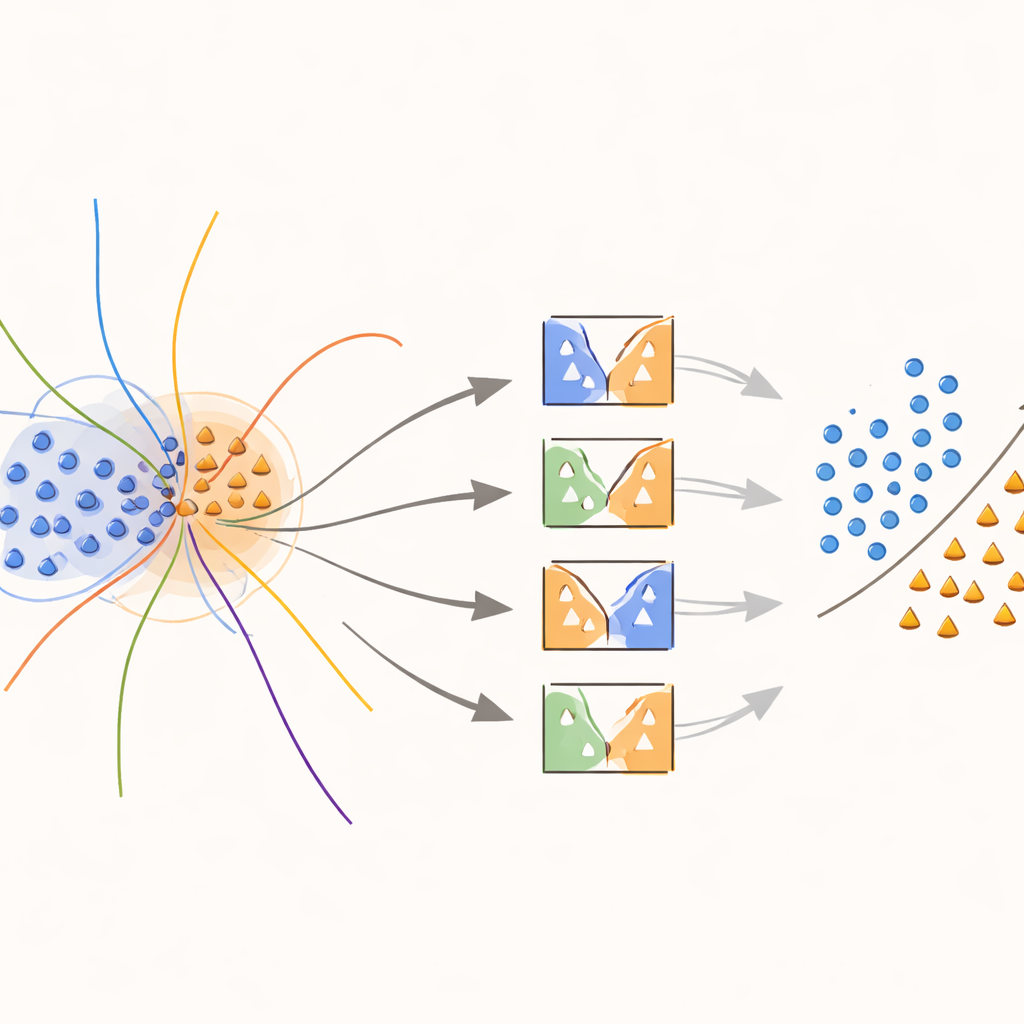
Elegir a los expertos adecuados para cada predicción
Cuando llega el momento de predecir la clase de un nuevo ejemplo, el sistema no promedia ciegamente las opiniones de todos los modelos. En su lugar, primero examina muestras de validación cercanas —casos que ya ha visto— y estima cuán competente es cada clasificador en esa región local. Sólo se permite votar a la fracción de modelos con mejor rendimiento histórico en ejemplos similares. Su decisión combinada determina la predicción final. Esta selección de modelos dependiente de la instancia mantiene la computación manejable a la vez que asegura que cada decisión esté informada por los modelos que mejor entienden ese rincón particular del espacio de datos.
¿Qué tan bien funciona en la práctica?
Para probar su método, los investigadores realizaron experimentos en 20 conjuntos de datos multiclase y 20 conjuntos binarios de un repositorio público, cubriendo tareas diversas como diagnóstico médico, evaluación de calidad y reconocimiento de patrones. Compararon su ensamblado dinámico con líneas base sólidas, incluido un SVM modificado combinado con la popular técnica AdaBoost. A través de los conjuntos, el nuevo enfoque alcanzó consistentemente mayor precisión global y un mejor equilibrio entre el reconocimiento correcto de las clases mayoritaria y minoritaria, medido por una estadística llamada G‑mean. En muchos benchmarks también mantuvo una precisión competitiva, es decir, evitó señalar demasiadas alarmas falsas mientras seguía detectando casos raros de forma más efectiva.
Qué implica esto para las decisiones del mundo real
Para el público general, la conclusión es que los autores han diseñado una forma más atenta y adaptable para que los algoritmos escuchen las “voces silenciosas” en los datos. Al abordar conjuntamente tamaños de clase sesgados y fronteras difusas, y al permitir que sólo los modelos más relevantes hablen en cada decisión, su marco reduce la probabilidad de que eventos raros pero vitales pasen desapercibidos. Esto lo hace especialmente prometedor para aplicaciones donde pasar por alto un caso inusual —una transacción fraudulenta, un componente que falla o una señal temprana de enfermedad— importa mucho más que clasificar incorrectamente un caso ordinario.
Cita: Abokadr, S., Azman, A., Hamdan, H. et al. Kernel-based dynamic ensemble approach for classifying imbalanced data with overlapping classes. Sci Rep 16, 13789 (2026). https://doi.org/10.1038/s41598-026-42940-y
Palabras clave: datos desequilibrados, clases solapadas, aprendizaje en ensamblado, máquinas de vectores de soporte, detección de fraude y anomalías