Clear Sky Science · ar
نهج تجميعي ديناميكي قائم على النواة لتصنيف البيانات غير المتوازنة مع تداخل الفئات
لماذا تهم الحالات النادرة في البيانات
تعتمد العديد من القرارات في الحياة الحديثة — من اكتشاف عملية شراء بالبطاقة الائتمانية احتيالية إلى رصد علامة مبكرة لمرض — على خوارزميات تتعلم من بيانات الماضي. لكن في معظم مجموعات البيانات الواقعية، تكون الأحداث المهمة نادرة: عدد قليل فقط من المعاملات احتيالية، وعدد قليل فقط من المرضى يعانون من حالات خطيرة. يمكن لهذه الحالات النادرة أن تُغرق بسهولة وسط جموع الأمثلة العادية، وتزداد صعوبة الأمور عندما تبدو أنماط «المألوف» و«الشاذ» متشابهة للغاية. يقدم هذا البحث طريقة جديدة لتدريب أنظمة التعلم الآلي بحيث تولي اهتمامًا خاصًا وذكيًا لهذه الحالات الصعبة الرصد والتي تُفوت بسهولة.
عندما تخفي الأمثلة الشائعة تلك الحاسمة
في العديد من مجموعات البيانات، تفوق فئة واحدة من الأمثلة الفئات الأخرى بأعداد كبيرة — على سبيل المثال، آلاف المعاملات الآمنة مقابل كل معاملة احتيالية. تحاول الخوارزميات التقليدية تعظيم الدقة الإجمالية، لذلك تنتهي بالتركيز على الأغلبية وتجاهل الأقلية. تتفاقم المشكلة عندما تتداخل الفئات المختلفة في خصائصها المقاسة، مما يجعل من الصعب تمييزها. في مجالات مثل كشف الاحتيال، والتشخيص الطبي، وكشف الأعطال، واكتشاف الشذوذ، تكون أمثلة الأقلية هي بالضبط ما نهتم به أكثر، ويمكن أن يكون تصنيفها بشكل خاطئ مكلفًا أو خطيرًا. يؤطر المؤلفون عملهم حول هذا التحدي المزدوج: أحجام فئات غير متساوية وحدود متداخلة في بيانات معقدة وعالية الأبعاد.
فريق أذكى من المصنفين
بدلاً من الاعتماد على نموذج واحد، يبني المؤلفون فريقًا — أو تجميعًا — من مصنفات آلات الدعم الناقل (SVM)، كل منها يستخدم طرقًا مختلفة للنظر إلى البيانات (تسمى نوى). الفكرة الأساسية هي جعل هذا التجميع ديناميكيًا وواعيًا محليًا. أولًا، تُجهز البيانات بعناية: تُطَبَّع الميزات لتوضع على مقياس قابل للمقارنة، وتُستخدم تقنية تسمى SMOTE لتوليد أمثلة تركيبية إضافية للفئات الممثلة تمثيلاً ناقصًا، مما يوازن مجموعات التدريب. 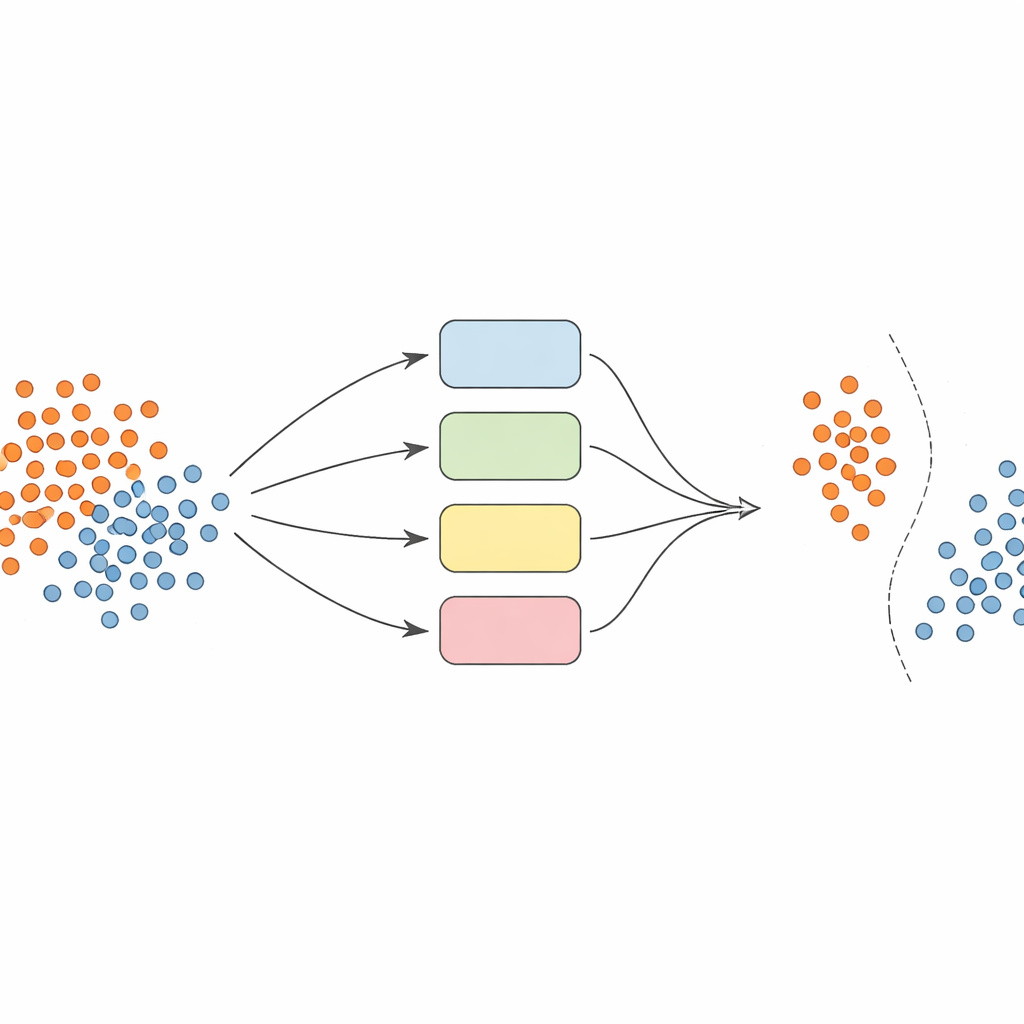
تعليم النماذج التركيز على الحدود الضبابية
جوهر النهج هو نواة جديدة «واعية بالحدود» تركز عمدًا الجهد على المناطق التي تتداخل فيها الفئات. أثناء التدريب، تبحث الطريقة عن عينات تقع في أحياء غامضة، كما يقاس ذلك بواسطة المسافات إلى أقرب الجيران. تُعامل هذه العينات المتداخلة بشكل خاص: يُستخدم كل منها لتدريب SVMs تُعدَّل فيها دالة النواة بواسطة وزن يعكس مدى المعلوماتية التي توفرها تلك العينة محليًا. تُعطى عينات فئة الأقلية القريبة من حدود القرار أوزانًا أعلى، بينما تُخفَّض أوزان عينات فئة الأغلبية في تلك المناطق. في الواقع، يقوم الأسلوب بشد سطح القرار حول نقاط نادرة لكنها مهمة، مما يساعد على رسم خط أكثر وضوحًا بين الفئات دون اختلاق بيانات أكثر من اللازم. 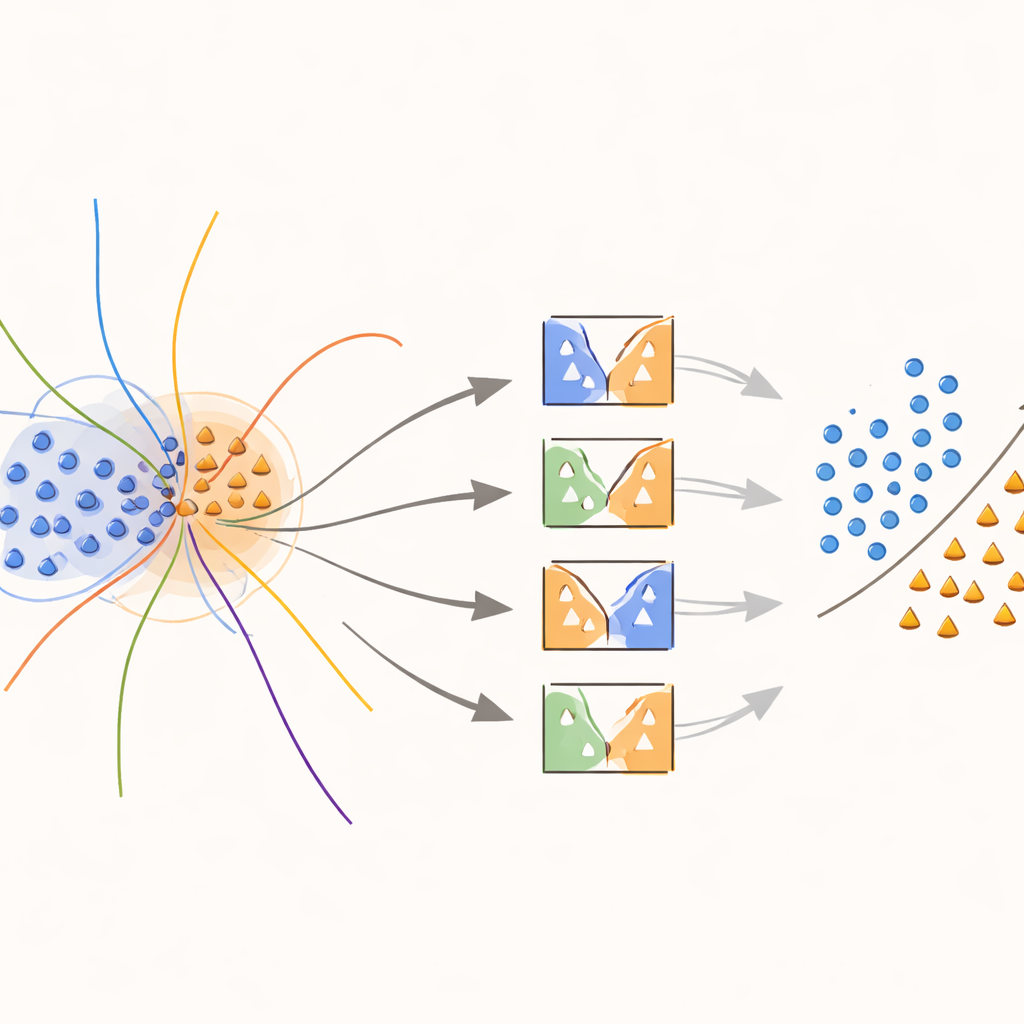
اختيار الخبراء المناسبين لكل توقع
عندما يحين وقت توقع فئة مثال جديد، لا يُجري النظام متوسطًا أعمى لآراء جميع النماذج. بدلاً من ذلك، ينظر أولًا إلى عينات التحقق القريبة — حالات سبق رؤيتها — ويقدر مدى كفاءة كل مصنف في تلك المنطقة المحلية. يُسمح فقط لجزء النماذج الأعلى أداءً، وهي التي تعاملت تاريخيًا مع أمثلة مشابهة جيدًا، بالإدلاء بأصواتها. يحدد قرارهم المجمّع التنبؤ النهائي. يحافظ هذا الاختيار المعتمد على الحالة على قابلية حساب التكلفة مع ضمان أن كل قرار يستند إلى النماذج التي تفهم ركن البيانات المعني على أفضل وجه.
ما مدى فاعليته عمليًا؟
لاختبار طريقتهم، أجرى الباحثون تجارب على 20 مجموعة بيانات متعددة الفئات و20 مجموعة ثنائية من مستودع عام، تغطي مهام متنوعة مثل التشخيص الطبي، وتقييم الجودة، والتعرف على الأنماط. قارنوا تجميعهم الديناميكي مع قواعد أساس قوية، بما في ذلك SVM معدل مدمج مع تقنية AdaBoost الشهيرة. عبر المجموعات، حقق النهج الجديد باستمرار دقة كلية أعلى وتوازنًا أفضل بين التعرف الصحيح على فئات الأغلبية والأقلية، كما قِيست بإحصائية تسمى المتوسط الهندسي (G‑mean). في العديد من المقاييس المرجعية، حافظ أيضًا على دقة تنافسية، مما يعني أنه تجنب إطلاق عدد كبير جدًا من الإنذارات الكاذبة بينما لا يزال يلتقط الحالات النادرة بفاعلية أكبر.
ماذا يعني هذا لقرارات العالم الحقيقي
بالنسبة لغير المتخصصين، الخلاصة أن المؤلفين صمموا طريقة أكثر انتباهاً وتكيّفًا لكي تستمع الخوارزميات إلى «الأصوات الهادئة» في البيانات. من خلال معالجة حجم الفئات المتحيز والحدود الضبابية معًا، ومن خلال السماح فقط لأكثر النماذج صلةً بالتحدث عند كل قرار، يقلل إطارهم من احتمال التغاضي عن أحداث نادرة لكنها حيوية. هذا يجعله واعدًا بشكل خاص للتطبيقات التي يكون فيها فوات حالة غير معتادة — معاملة احتيالية، مكوّن فاشل، أو علامة مبكرة لمرض — أكثر أهمية بكثير من تصنيف خاطئ لمثال عادي.
الاستشهاد: Abokadr, S., Azman, A., Hamdan, H. et al. Kernel-based dynamic ensemble approach for classifying imbalanced data with overlapping classes. Sci Rep 16, 13789 (2026). https://doi.org/10.1038/s41598-026-42940-y
الكلمات المفتاحية: البيانات غير المتوازنة, تداخل الفئات, التعلم بالتجميع, آلات الدعم الناقل, كشف الاحتيال والشذوذ