Clear Sky Science · ru
Динамический ансамблевый подход на основе ядер для классификации несбалансированных данных с перекрывающимися классами
Почему редкие случаи в данных важны
Многие решения в современной жизни — от обнаружения мошеннической операции по карте до выявления ранних признаков болезни — зависят от алгоритмов, обучающихся на исторических данных. Но в большинстве реальных наборов данных важные события встречаются редко: мошеннических транзакций лишь немного, серьёзно больных пациентов тоже немного. Эти редкие случаи легко теряются среди множества обычных примеров, и всё усложняется, когда паттерны «нормального» и «аномального» очень похожи. В этой работе предложен новый способ обучения систем машинного обучения, чтобы они уделяли особое, интеллектуально направленное внимание этим трудночеловимым и легко упускаемым случаям.
Когда распространённые примеры скрывают ключевые
Во многих наборах данных один класс примеров значительно превосходит остальные по численности — например, тысячи безопасных транзакций на каждую мошенническую. Стандартные алгоритмы стремятся максимизировать общую точность, поэтому в результате фокусируются на большинстве и игнорируют меньшинство. Проблема усугубляется, когда классы перекрываются по измеряемым признакам и их трудно различить. В областях, таких как обнаружение мошенничества, медицинская диагностика, обнаружение отказов и поиск аномалий, эти примеры меньшинства как раз представляют наибольшую ценность, и их неверная классификация может быть дорогостоящей или опасной. Авторы рассматривают свою работу как решение этой двойной задачи: неравномерных размеров классов и перекрывающихся границ в сложных многомерных данных.
Более умная команда классификаторов
Вместо опоры на одну модель авторы создают команду — ансамбль — классификаторов SVM, каждый из которых использует разные способы представления данных (так называемые ядра). Ключевая идея — сделать ансамбль динамичным и локально осведомлённым. Сначала данные тщательно предварительно обрабатываются: признаки нормализуют, чтобы они находились в сопоставимом масштабе, а для балансировки обучающих наборов применяется метод SMOTE для генерации дополнительных синтетических примеров для недостаточно представленных классов. 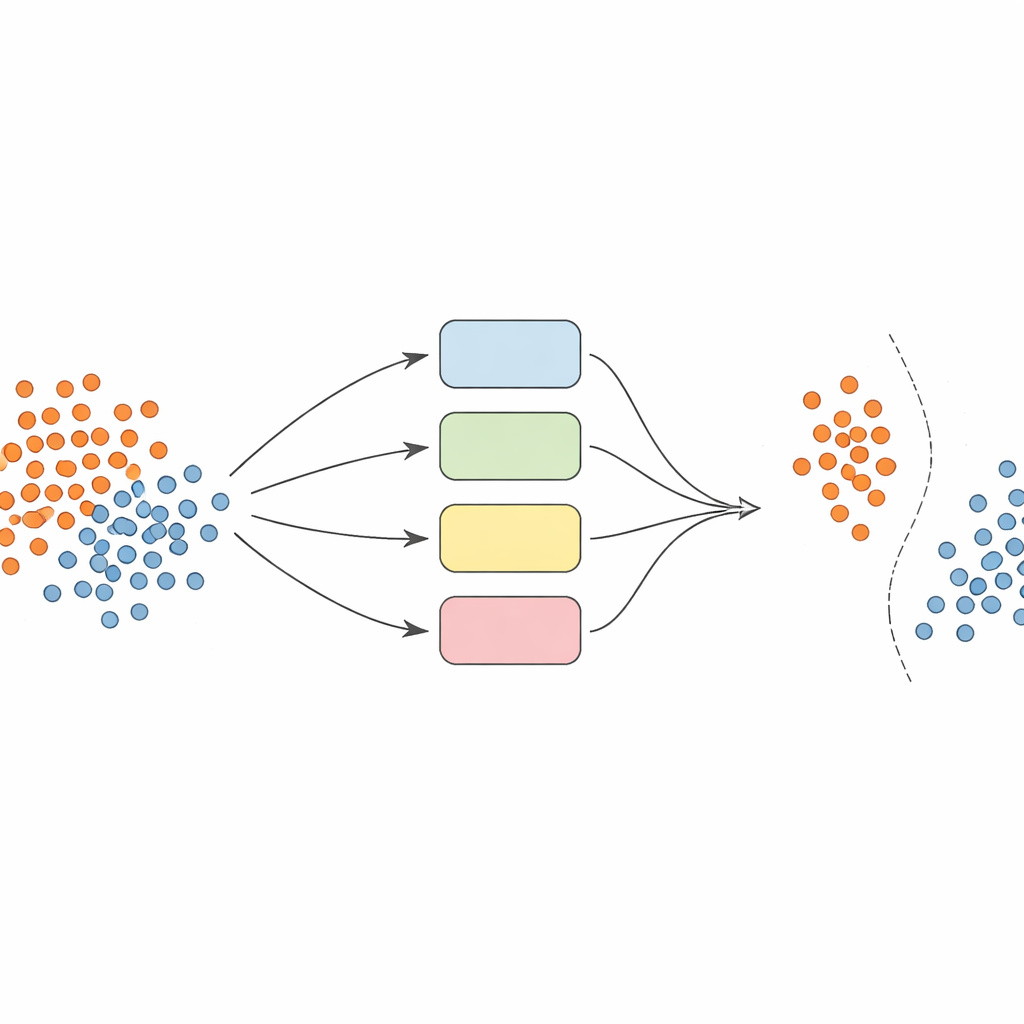
Обучение моделей фокусироваться на размытой границе
Сердце подхода — новое «границе‑чувствительное» ядро, которое целенаправленно концентрирует усилия на областях, где классы перекрываются. Во время обучения метод ищет образцы, находящиеся в неоднозначных окрестностях, оцениваемых через расстояния до ближайших соседей. Этим перекрывающимся образцам затем уделяют особое внимание: каждый такой пример используется для обучения SVM, чья функция ядра модифицируется весом, отражающим, насколько информативен этот образец в локальном контексте. Образцы из класса меньшинства, расположенные у границы решения, получают более высокие веса, тогда как образцы большинства в этих зонах уменьшаются в весе. Фактически метод растягивает поверхность разделения вокруг редких, но важных точек, помогая провести более чёткую грань между классами без излишней генерации данных.
Выбор подходящих экспертов для каждого прогноза
Когда приходит время предсказать класс нового примера, система не усредняет мнения всех моделей вслепую. Вместо этого она сначала рассматривает соседние валидационные образцы — случаи, которые она уже видела — и оценивает компетентность каждого классификатора в этой локальной области. Только лучшая доля моделей, те, которые исторически хорошо справлялись с похожими примерами, допускаются к голосованию. Их совместное решение определяет итоговый прогноз. Такой выбор моделей в зависимости от экземпляра сокращает вычислительные затраты и гарантирует, что каждое решение учитывает мнения моделей, лучше понимающих соответствующий уголок пространства данных.
Насколько хорошо это работает на практике?
Чтобы проверить метод, исследователи провели эксперименты на 20 многоклассовых и 20 бинарных наборах данных из открытого репозитория, охватывающих разнообразные задачи, такие как медицинская диагностика, оценка качества и распознавание образов. Они сравнили свой динамический ансамбль с сильными базовыми методами, включая модифицированный SVM в сочетании с популярной техникой AdaBoost. По результатам на наборах данных новый подход стабильно обеспечивал более высокую общую точность и лучшую сбалансированность между корректным распознаванием классов большинства и меньшинства, измеряемую статистикой G‑mean. Во многих бенчмарках он также сохранял конкурентоспособную точность (precision), что означает, что он избегал слишком большого числа ложных срабатываний, при этом эффективнее улавливал редкие случаи.
Что это значит для реальных решений
Для неспециалистов главное, что авторы разработали более внимательный и адаптивный способ, с помощью которого алгоритмы прислушиваются к «тихим голосам» в данных. Совместно решая проблему перекоса размеров классов и размытых границ и допуская к решению только наиболее релевантные модели, их рамочная модель снижает вероятность того, что редкие, но критичные события будут упущены. Это делает подход особенно перспективным для приложений, где пропуск необычного случая — мошеннической транзакции, вышедшего из строя компонента или раннего признака болезни — существенно важнее, чем неверная классификация обычного примера.
Цитирование: Abokadr, S., Azman, A., Hamdan, H. et al. Kernel-based dynamic ensemble approach for classifying imbalanced data with overlapping classes. Sci Rep 16, 13789 (2026). https://doi.org/10.1038/s41598-026-42940-y
Ключевые слова: несбалансированные данные, перекрывающиеся классы, ансамблевое обучение, метод опорных векторов, выявление мошенничества и аномалий