Clear Sky Science · de
Kernelbasierter dynamischer Ensemble‑Ansatz zur Klassifikation unausgewogener Daten mit überlappenden Klassen
Warum seltene Fälle in Daten wichtig sind
Viele Entscheidungen im modernen Leben – vom Erkennen einer betrügerischen Kreditkartenbuchung bis zum Aufspüren eines frühen Krankheitszeichens – beruhen auf Algorithmen, die aus vergangenen Daten lernen. In den meisten realen Datensätzen sind die wichtigen Ereignisse jedoch selten: Nur wenige Transaktionen sind betrügerisch, nur wenige Patientinnen und Patienten sind schwer erkrankt. Diese seltenen Fälle können leicht in der Masse gewöhnlicher Beispiele untergehen, und die Lage verschärft sich, wenn sich die Muster von „normal“ und „abnormal“ sehr ähneln. Dieser Beitrag stellt eine neue Methode vor, maschinelle Lernsysteme so zu trainieren, dass sie diesen schwer zu erkennenden, leicht zu übersehenden Fällen besondere, intelligente Aufmerksamkeit schenken.
Wenn häufige Beispiele die entscheidenden verbergen
In vielen Datensätzen überwiegt eine Klasse die anderen deutlich – etwa Tausende sicherer Transaktionen auf jede betrügerische. Standardalgorithmen versuchen, die Gesamtgenauigkeit zu maximieren, und konzentrieren sich deshalb auf die Mehrheit, während die Minderheit vernachlässigt wird. Das Problem verschärft sich, wenn die Klassen in ihren gemessenen Merkmalen überlappen und dadurch schwer zu unterscheiden sind. In Bereichen wie Betrugserkennung, medizinischer Diagnose, Fehlererkennung und Anomalieerkennung sind gerade diese Minderheitsbeispiele die, um die es am meisten geht; ihre Fehlklassifizierung kann kostspielig oder gefährlich sein. Die Autoren fassen ihre Arbeit um diese doppelte Herausforderung: ungleiche Klassenhäufigkeiten und überlappende Grenzen in komplexen, hochdimensionalen Daten.
Ein klügeres Team von Klassifikatoren
Anstatt sich auf ein einzelnes Modell zu verlassen, bauen die Autoren ein Team – ein Ensemble – von Support‑Vector‑Machine (SVM)‑Klassifikatoren auf, die jeweils unterschiedliche Blickwinkel auf die Daten verwenden (sogenannte Kernel). Die zentrale Idee ist, dieses Ensemble dynamisch und lokal bewusst zu machen. Zuerst werden die Daten sorgfältig vorverarbeitet: Merkmale werden normalisiert, sodass sie vergleichbar skaliert sind, und eine Technik namens SMOTE wird verwendet, um zusätzliche synthetische Beispiele für die unterrepräsentierten Klassen zu erzeugen und die Trainingsmengen auszugleichen. 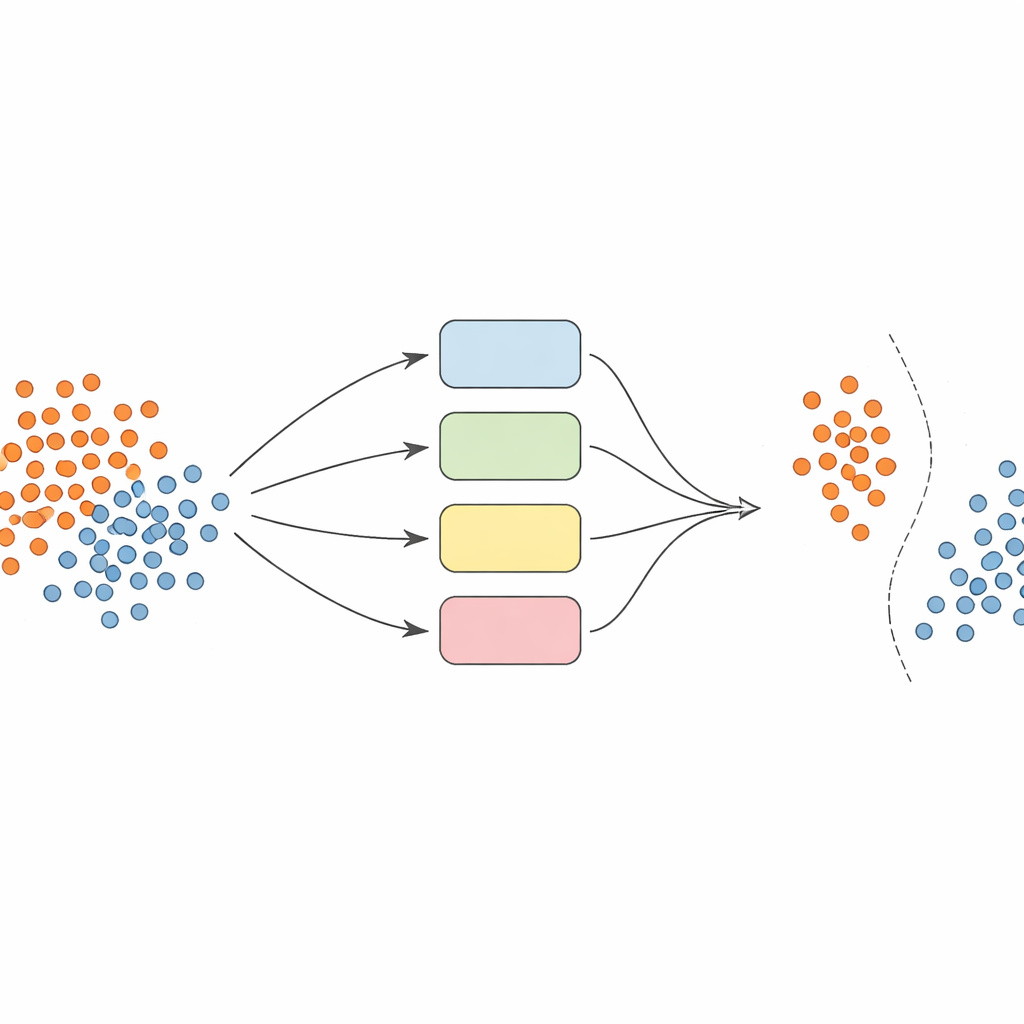
Modelle darin schulen, sich auf unscharfe Grenzen zu konzentrieren
Kern des Ansatzes ist ein neuer „grenzen‑bewusster“ Kernel, der gezielt Aufwand auf Regionen konzentriert, in denen Klassen überlappen. Während des Trainings sucht die Methode nach Proben, die in zweideutigen Nachbarschaften liegen, gemessen an Abständen zu ihren nächsten Nachbarn. Diese überlappenden Proben erhalten dann eine besondere Behandlung: Jede wird verwendet, um SVMs zu trainieren, deren Kernel‑Funktion durch ein Gewicht modifiziert wird, das erfasst, wie informativ diese Probe lokal ist. Minderheitsklassen‑Proben nahe der Entscheidungsgrenze erhalten höhere Gewichte, während Mehrheitsklassen‑Proben in diesen Zonen herabgewichtet werden. Effektiv dehnt die Methode die Entscheidungsfläche um seltene, aber wichtige Punkte herum, was hilft, eine klarere Trennlinie zwischen den Klassen zu zeichnen, ohne mehr Daten zu erfinden, als nötig. 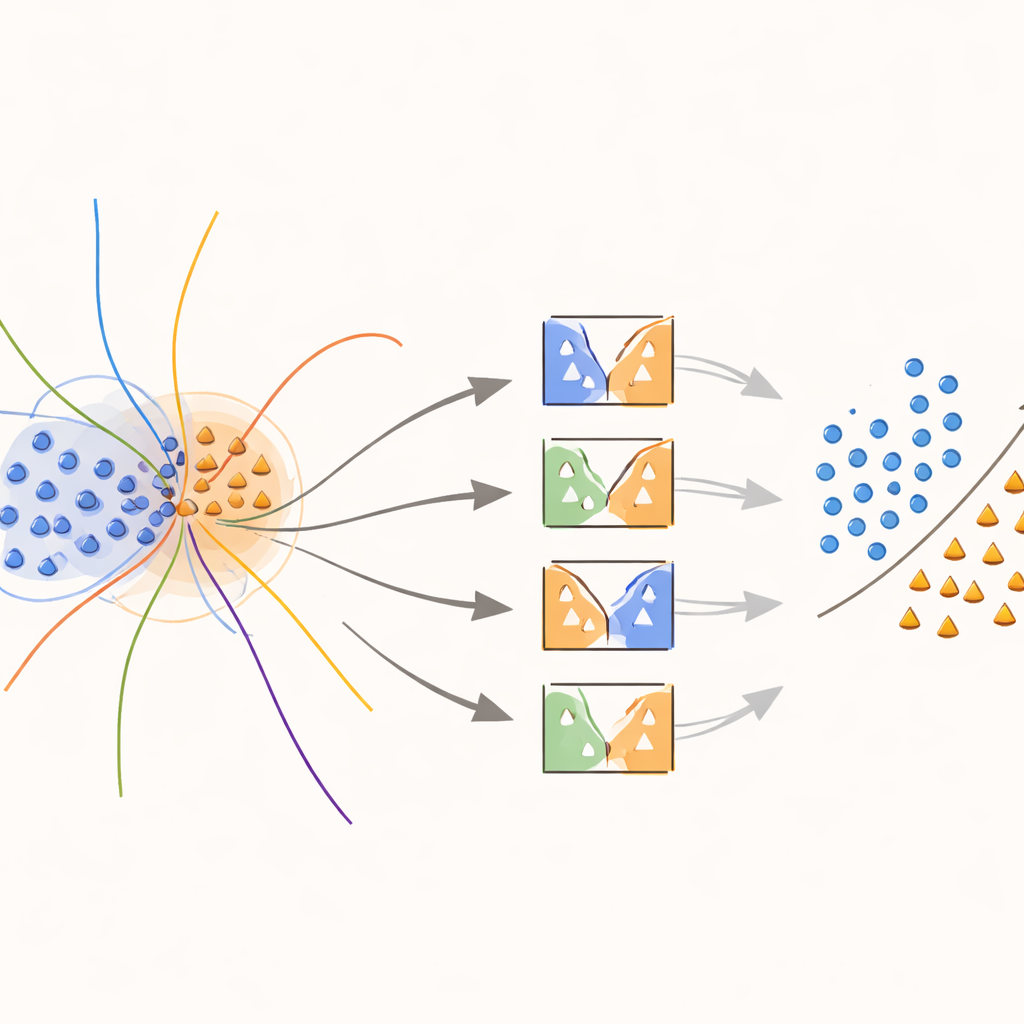
Die richtigen Expertinnen und Experten für jede Vorhersage auswählen
Wenn es Zeit ist, die Klasse eines neuen Beispiels vorherzusagen, mittelt das System nicht blind die Meinungen aller Modelle. Stattdessen betrachtet es zunächst nahegelegene Validierungsbeispiele – bereits bekannte Fälle – und schätzt ab, wie kompetent jeder Klassifikator in dieser lokalen Region ist. Nur der leistungsschwache obere Anteil an Modellen, also jene, die historisch ähnliche Beispiele gut behandelt haben, dürfen abstimmen. Ihre kombinierte Entscheidung bestimmt die endgültige Vorhersage. Diese instanzabhängige Modellauswahl hält den Rechenaufwand überschaubar und sorgt gleichzeitig dafür, dass jede Entscheidung von den Modellen getragen wird, die diesen speziellen Bereich des Datenraums am besten verstehen.
Wie gut funktioniert es in der Praxis?
Um ihre Methode zu testen, führten die Forscher Experimente mit 20 Mehrklassen‑ und 20 Binärdatensätzen aus einem öffentlichen Repository durch, die vielfältige Aufgaben abdecken, etwa medizinische Diagnose, Qualitätsbewertung und Mustererkennung. Sie verglichen ihr dynamisches Ensemble mit starken Baselines, darunter eine modifizierte SVM kombiniert mit der populären AdaBoost‑Technik. Über die Datensätze hinweg erzielte der neue Ansatz durchweg höhere Gesamtgenauigkeit und eine bessere Balance zwischen korrekt erkannter Mehrheits‑ und Minderheitsklasse, gemessen an einer Statistik namens G‑Mean. In vielen Benchmarks hielt er zudem wettbewerbsfähige Präzision, das heißt, er vermied zu viele Fehlalarme, während er seltene Fälle dennoch effektiver erfasste.
Was das für Entscheidungen in der realen Welt bedeutet
Für Nicht‑Spezialistinnen und Nicht‑Spezialisten lautet die Quintessenz, dass die Autoren eine aufmerksamer reagierende und anpassungsfähigere Methode entwickelt haben, damit Algorithmen den „leisen Stimmen“ in den Daten besser zuhören. Indem sie sowohl verzerrte Klassenhäufigkeiten als auch unscharfe Grenzen gemeinsam angehen und nur die relevantesten Modelle für jede Entscheidung zu Wort kommen lassen, verringert ihr Rahmenwerk die Wahrscheinlichkeit, dass seltene, aber entscheidende Ereignisse übersehen werden. Das macht den Ansatz besonders vielversprechend für Anwendungen, bei denen das Übersehen eines ungewöhnlichen Falls – eine betrügerische Transaktion, eine ausfallende Komponente oder ein frühes Krankheitszeichen – wesentlich schwerwiegendere Folgen hat als die Fehlklassifizierung eines gewöhnlichen Falls.
Zitation: Abokadr, S., Azman, A., Hamdan, H. et al. Kernel-based dynamic ensemble approach for classifying imbalanced data with overlapping classes. Sci Rep 16, 13789 (2026). https://doi.org/10.1038/s41598-026-42940-y
Schlüsselwörter: unausgewogene Daten, überlappende Klassen, Ensemble‑Lernen, Support‑Vector‑Machines, Betrugs‑ und Anomalieerkennung