Clear Sky Science · pt
Abordagem dinâmica baseada em kernel para classificar dados desbalanceados com classes sobrepostas
Por que casos raros nos dados importam
Muitas decisões na vida moderna — de identificar uma compra de cartão de crédito fraudulenta a detectar um sinal inicial de doença — dependem de algoritmos que aprendem com dados passados. Mas, na maioria dos conjuntos de dados do mundo real, os eventos importantes são raros: apenas algumas transações são fraudulentas, apenas alguns pacientes estão gravemente doentes. Esses casos raros podem ser facilmente ofuscados pela massa de exemplos ordinários, e a tarefa fica ainda mais difícil quando os padrões de “normal” e “anômalo” são muito parecidos. Este artigo apresenta uma nova forma de treinar sistemas de aprendizado de máquina para que prestem atenção especial e inteligente a esses casos difíceis de ver e fáceis de perder.
Quando exemplos comuns escondem os cruciais
Em muitos conjuntos de dados, uma classe de exemplos supera em número as outras — por exemplo, milhares de transações seguras para cada uma fraudulenta. Algoritmos padrão tentam maximizar a acurácia global, então acabam se concentrando na maioria e ignorando a minoria. O problema se agrava quando as diferentes classes se sobrepõem nas características medidas, tornando-as difíceis de distinguir. Em áreas como detecção de fraude, diagnóstico médico, detecção de falhas e identificação de anomalias, esses exemplos minoritários são exatamente aqueles que mais nos interessam, e classificá‑los incorretamente pode ser custoso ou perigoso. Os autores enquadram seu trabalho em torno desse duplo desafio: tamanhos de classe desiguais e limites sobrepostos em dados complexos e de alta dimensionalidade.
Um time mais inteligente de classificadores
Em vez de confiar em um único modelo, os autores constroem um time — ou ensemble — de classificadores SVM (máquinas de vetores de suporte), cada um usando diferentes formas de olhar para os dados (chamadas kernels). A ideia-chave é tornar esse ensemble dinâmico e sensibilizado localmente. Primeiro, os dados são cuidadosamente pré‑processados: as características são normalizadas para ficarem em uma escala comparável, e uma técnica chamada SMOTE é usada para gerar exemplos sintéticos adicionais para as classes subrepresentadas, equilibrando os conjuntos de treino. 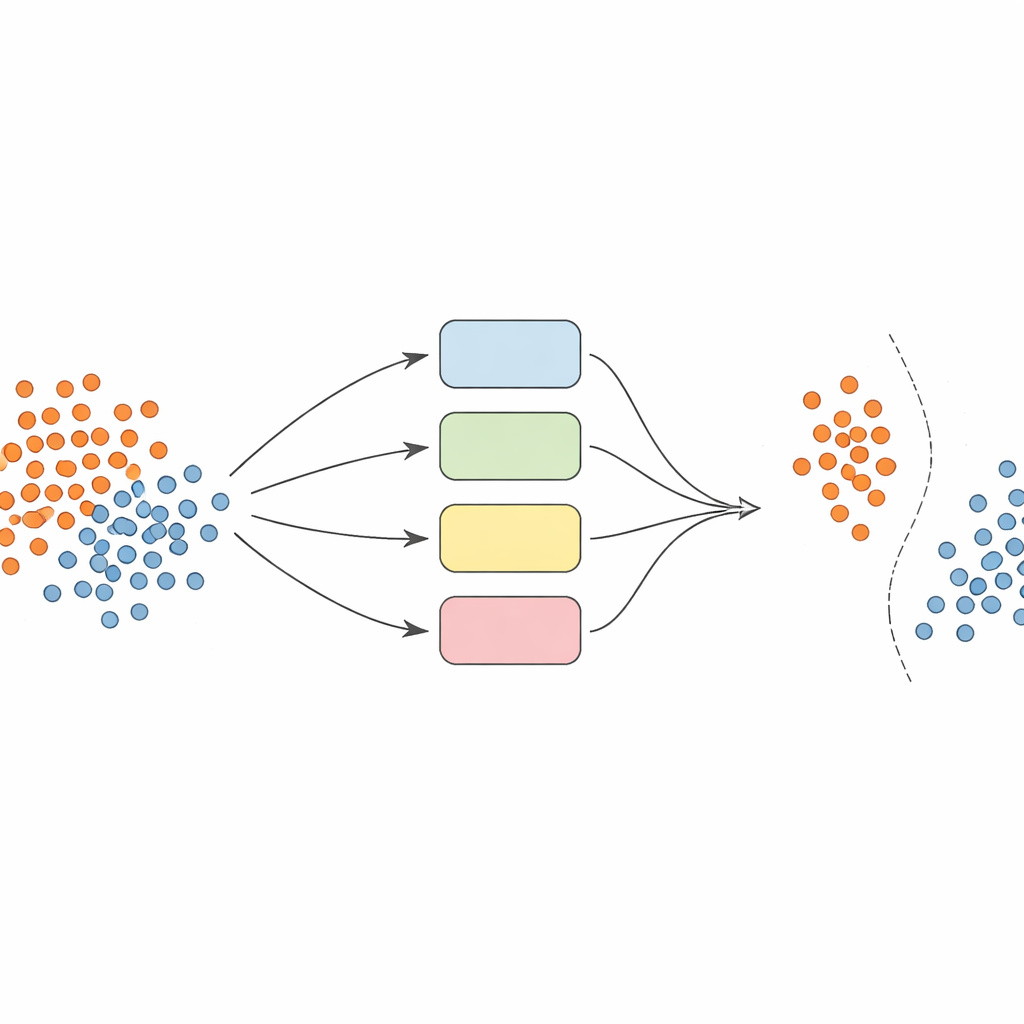
Ensinando modelos a focarem nas bordas confusas
O cerne da abordagem é um novo kernel “consciente do limite” que concentra propositalmente esforço nas regiões onde as classes se sobrepõem. Durante o treinamento, o método procura amostras que estão em vizinhanças ambíguas, medidas pelas distâncias até seus vizinhos mais próximos. Essas amostras sobrepostas recebem então um tratamento especial: cada uma é usada para treinar SVMs cuja função kernel é modificada por um peso que captura o quão informativa essa amostra é localmente. Amostras da classe minoritária próximas à fronteira de decisão recebem pesos maiores, enquanto amostras da classe majoritária nessas zonas têm seus pesos reduzidos. Na prática, o método estica a superfície de decisão em torno de pontos raros mas importantes, ajudando a traçar uma linha mais clara entre classes sem inventar mais dados do que o necessário. 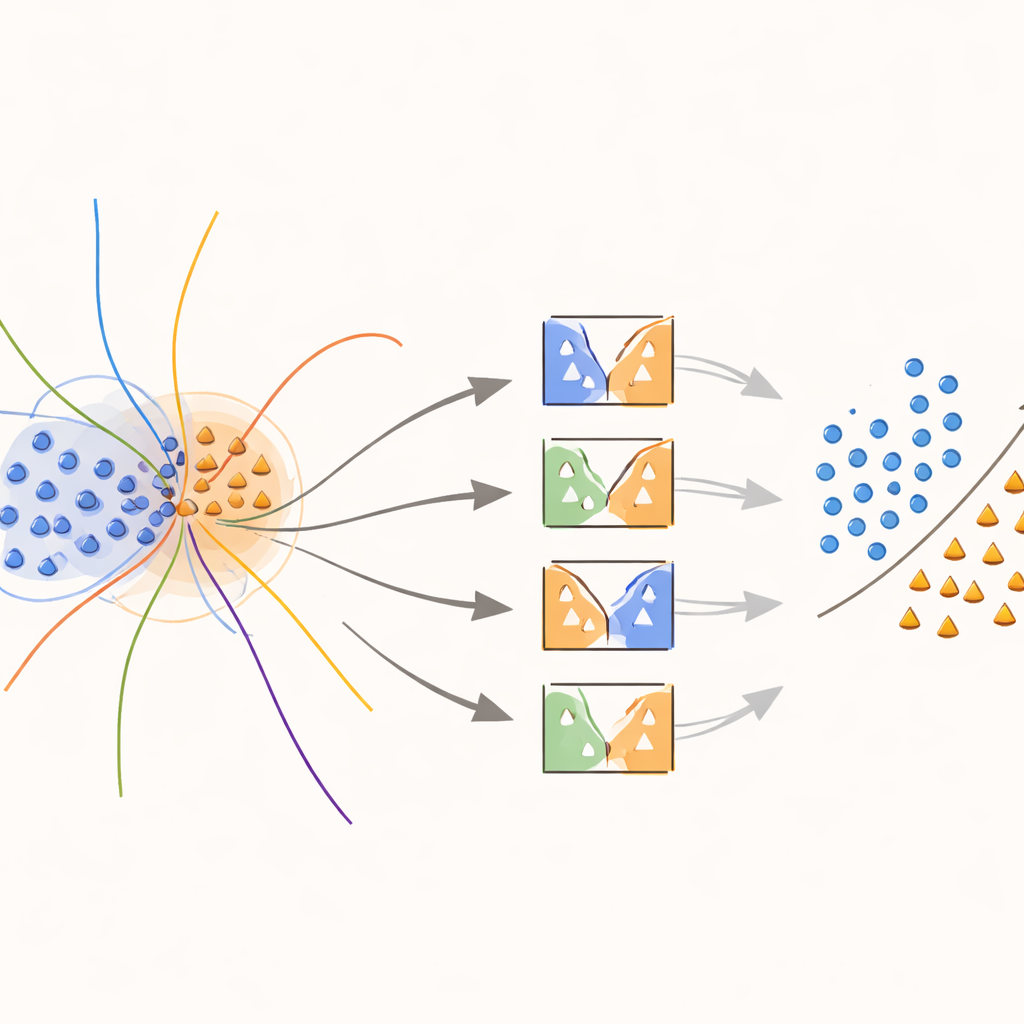
Escolhendo os especialistas certos para cada previsão
Quando chega a hora de prever a classe de um novo exemplo, o sistema não faz a média cega das opiniões de todos os modelos. Em vez disso, primeiro observa amostras de validação próximas — casos que já viu — e estima quão competente cada classificador é naquela região local. Apenas a fração de modelos com melhor desempenho, aqueles que historicamente lidaram bem com exemplos semelhantes, podem votar. A decisão combinada deles determina a previsão final. Essa seleção de modelos dependente da instância mantém a computação manejável ao mesmo tempo em que garante que cada decisão seja informada pelos modelos que melhor compreendem aquele canto específico do espaço de dados.
Quão bem isso funciona na prática?
Para testar seu método, os pesquisadores realizaram experimentos em 20 conjuntos de dados multiclasses e 20 conjuntos binários de um repositório público, cobrindo tarefas diversas como diagnóstico médico, avaliação de qualidade e reconhecimento de padrões. Eles compararam seu ensemble dinâmico contra baselines fortes, incluindo um SVM modificado combinado com a popular técnica AdaBoost. Ao longo dos conjuntos, a nova abordagem consistentemente alcançou maior acurácia geral e melhor equilíbrio entre o reconhecimento correto de classes majoritárias e minoritárias, medido por uma estatística chamada G‑mean. Em muitos benchmarks, também manteve precisão competitiva, isto é, evitou sinalizar alarmes falsos em excesso enquanto continuava a detectar casos raros de forma mais eficaz.
O que isso significa para decisões do mundo real
Para não especialistas, a lição é que os autores projetaram uma maneira mais atenta e adaptável para algoritmos ouvirem as “vozes discretas” nos dados. Ao enfrentar conjuntamente tamanhos de classe desequilibrados e fronteiras vagas, e ao permitir que apenas os modelos mais relevantes falem em cada decisão, seu arcabouço reduz a chance de que eventos raros porém vitais sejam negligenciados. Isso o torna especialmente promissor para aplicações nas quais perder um caso incomum — uma transação fraudulenta, um componente prestes a falhar ou um sinal precoce de doença — importa muito mais do que classificar incorretamente um caso ordinário.
Citação: Abokadr, S., Azman, A., Hamdan, H. et al. Kernel-based dynamic ensemble approach for classifying imbalanced data with overlapping classes. Sci Rep 16, 13789 (2026). https://doi.org/10.1038/s41598-026-42940-y
Palavras-chave: dados desbalanceados, classes sobrepostas, aprendizado em conjunto, máquinas de vetores de suporte, detecção de fraude e anomalias