Clear Sky Science · fr
Approche d'ensemble dynamique basée sur des noyaux pour classer des données déséquilibrées avec classes qui se recouvrent
Pourquoi les cas rares dans les données comptent
Beaucoup de décisions de la vie moderne — de la détection d'un achat frauduleux par carte bancaire à la détection précoce d'une maladie — reposent sur des algorithmes qui apprennent à partir de données historiques. Mais dans la plupart des jeux de données réels, les événements importants sont rares : seules quelques transactions sont frauduleuses, seuls quelques patients sont gravement malades. Ces cas rares peuvent facilement être noyés dans la masse d'exemples ordinaires, et la tâche devient encore plus difficile lorsque les schémas du « normal » et de l'« anormal » se ressemblent beaucoup. Cet article présente une nouvelle méthode d'entraînement des systèmes d'apprentissage automatique pour qu'ils accordent une attention particulière et intelligente à ces cas difficiles à voir et faciles à manquer.
Quand les exemples courants cachent les cas cruciaux
Dans de nombreux jeux de données, une classe d'exemples surpasse largement les autres — par exemple, des milliers de transactions sûres pour une seule frauduleuse. Les algorithmes standard cherchent à maximiser l'exactitude globale, si bien qu'ils se concentrent sur la majorité et ignorent la minorité. Le problème s'aggrave lorsque les différentes classes se recouvrent dans leurs caractéristiques mesurées, ce qui les rend difficiles à distinguer. Dans des domaines tels que la détection de fraude, le diagnostic médical, la détection de pannes et le repérage d'anomalies, ces exemples minoritaires sont précisément ceux qui nous intéressent le plus, et les mal classer peut être coûteux ou dangereux. Les auteurs encadrent leur travail autour de ce double défi : des tailles de classes inégales et des frontières qui se chevauchent dans des données complexes et de haute dimension.
Une équipe plus intelligente de classificateurs
Plutôt que de s'appuyer sur un seul modèle, les auteurs construisent une équipe — ou un ensemble — de classificateurs SVM (machines à vecteurs de support), chacun utilisant des manières différentes d'examiner les données (appelées noyaux). L'idée clé est de rendre cet ensemble dynamique et localement conscient. D'abord, les données sont soigneusement prétraitées : les caractéristiques sont normalisées afin d'être sur une échelle comparable, et une technique appelée SMOTE est utilisée pour générer des exemples synthétiques supplémentaires pour les classes sous-représentées, équilibrant ainsi les jeux d'entraînement. 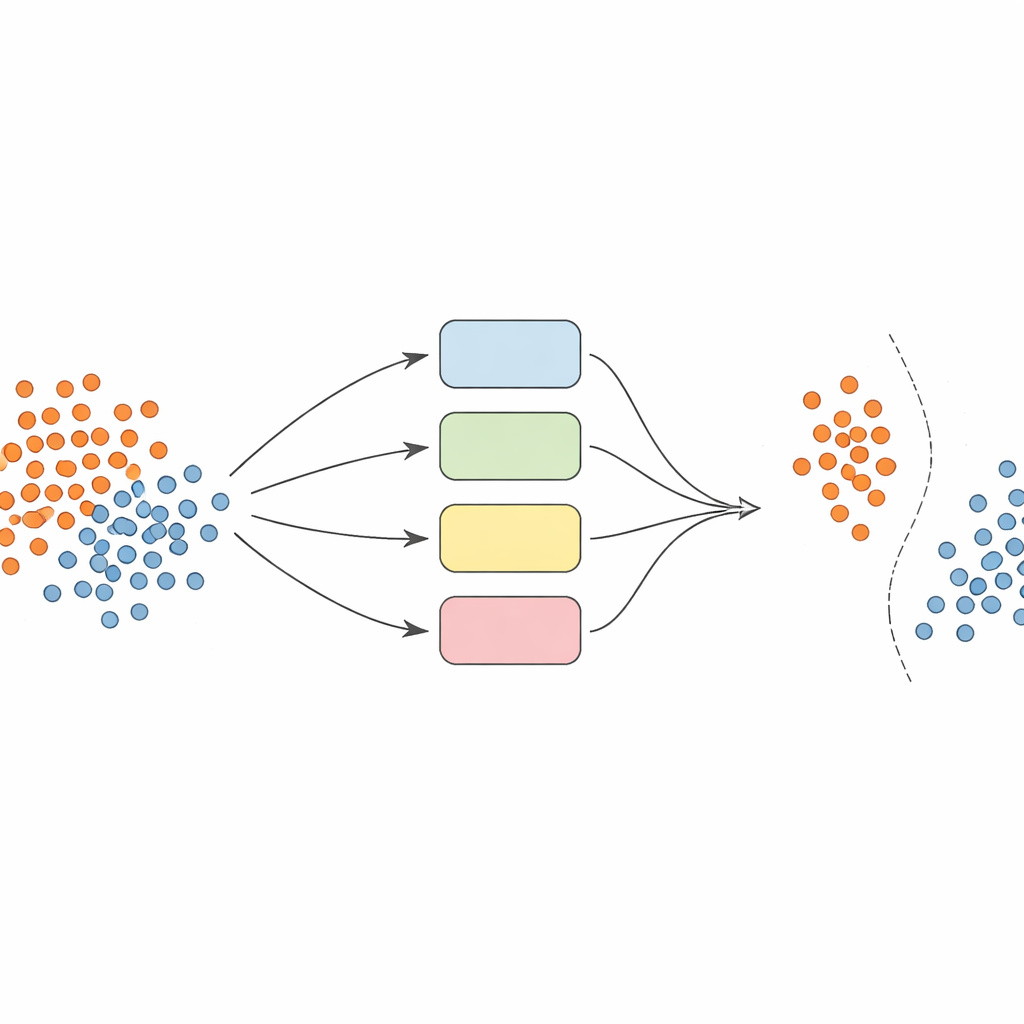
Apprendre aux modèles à se concentrer sur les frontières floues
Le cœur de l'approche est un nouveau noyau « sensible aux frontières » qui concentre délibérément l'effort sur les régions où les classes se recouvrent. Pendant l'entraînement, la méthode recherche des échantillons situés dans des voisinages ambigus, mesurés par les distances à leurs plus proches voisins. Ces échantillons de recouvrement reçoivent ensuite un traitement spécial : chacun est utilisé pour entraîner des SVM dont la fonction noyau est modifiée par un poids capturant l'utilité informative de cet échantillon localement. Les échantillons de la classe minoritaire proches de la frontière de décision reçoivent des poids plus élevés, tandis que les échantillons de la classe majoritaire dans ces zones sont sous‑pondérés. En pratique, la méthode étire la surface de décision autour de points rares mais importants, aidant à tracer une ligne plus nette entre les classes sans inventer plus de données que nécessaire. 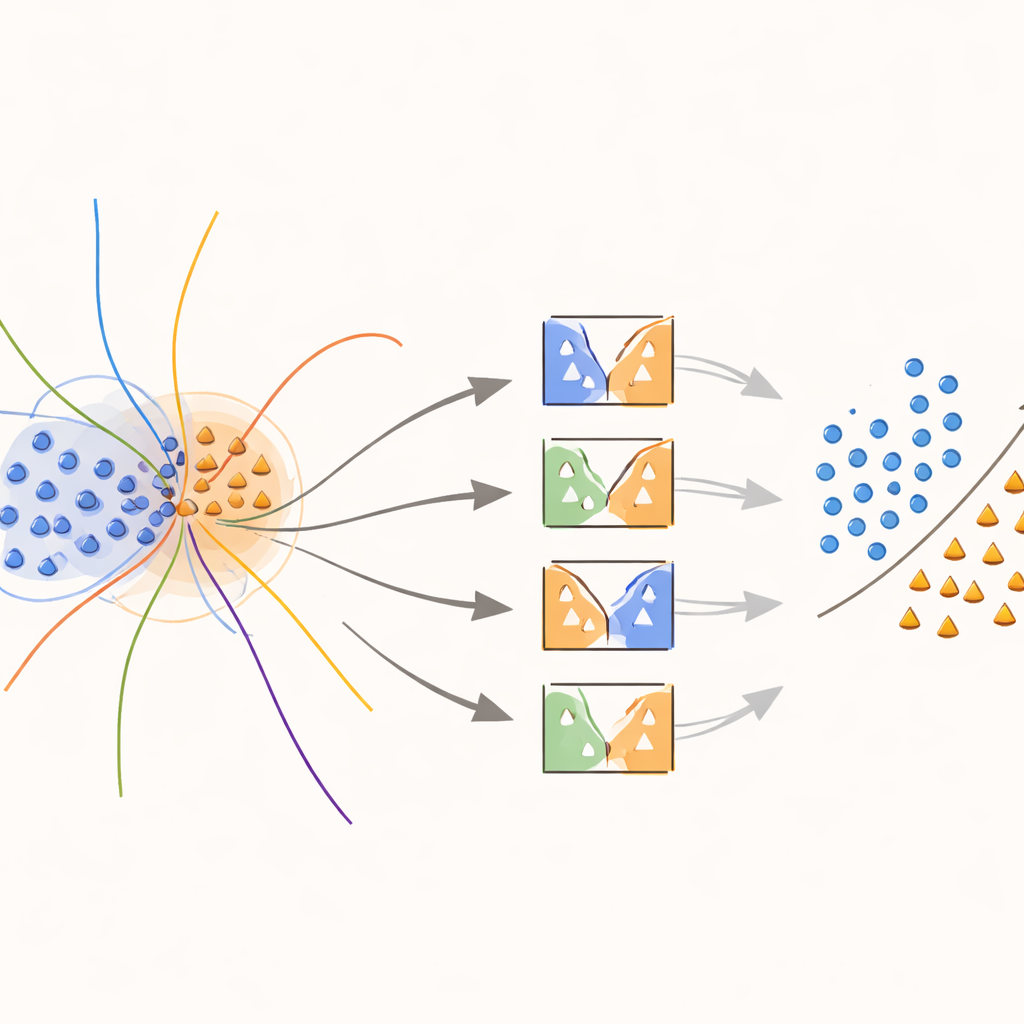
Choisir les bons experts pour chaque prédiction
Au moment de prédire la classe d'un nouvel exemple, le système n'agrège pas aveuglément les avis de tous les modèles. Il examine d'abord des échantillons de validation voisins — des cas qu'il a déjà vus — et estime la compétence de chaque classificateur dans cette région locale. Seule la fraction des modèles les mieux performants, ceux qui ont historiquement bien traité des exemples similaires, est autorisée à voter. Leur décision combinée détermine la prédiction finale. Cette sélection de modèles dépendante de l'instance maintient la charge de calcul raisonnable tout en assurant que chaque décision s'appuie sur les modèles qui comprennent le mieux ce coin particulier de l'espace des données.
Quelle est l'efficacité en pratique ?
Pour évaluer leur méthode, les chercheurs ont réalisé des expériences sur 20 jeux de données multi‑classe et 20 jeux binaires provenant d'un référentiel public, couvrant des tâches diverses telles que le diagnostic médical, l'évaluation de la qualité et la reconnaissance de motifs. Ils ont comparé leur ensemble dynamique à des références solides, y compris un SVM modifié combiné à la technique populaire AdaBoost. Sur l'ensemble des jeux de données, la nouvelle approche a systématiquement atteint une meilleure exactitude globale et un meilleur équilibre entre la reconnaissance correcte des classes majoritaires et minoritaires, mesuré par une statistique appelée G‑mean. Sur de nombreux bancs d'essai, elle a aussi conservé une précision compétitive, c'est‑à‑dire qu'elle évitait de signaler trop de fausses alertes tout en détectant plus efficacement les cas rares.
Ce que cela signifie pour les décisions du monde réel
Pour les non‑spécialistes, la conclusion est que les auteurs ont conçu une manière plus attentive et adaptable pour les algorithmes d'entendre les « voix silencieuses » dans les données. En traitant conjointement la déséquilibre des tailles de classes et les frontières floues, et en ne laissant parler que les modèles les plus pertinents pour chaque décision, leur cadre réduit le risque que des événements rares mais vitaux soient négligés. Cela le rend particulièrement prometteur pour des applications où manquer un cas inhabituel — une transaction frauduleuse, un composant défaillant ou un signe précoce de maladie — a beaucoup plus de conséquences que de mal classer un cas ordinaire.
Citation: Abokadr, S., Azman, A., Hamdan, H. et al. Kernel-based dynamic ensemble approach for classifying imbalanced data with overlapping classes. Sci Rep 16, 13789 (2026). https://doi.org/10.1038/s41598-026-42940-y
Mots-clés: données déséquilibrées, classes qui se recouvrent, apprentissage par ensemble, machines à vecteurs de support, détection de fraude et d'anomalies