Clear Sky Science · he
גישה דינמית מבוססת גרעין למיון נתונים לא מאוזנים עם מעמדות חופפות
מדוע מקרים נדירים בנתונים חשובים
הרבה החלטות בחיי המודרניים — מהגילוי של רכישת כרטיס אשראי הונאתית ועד זיהוי סימן מוקדם למחלה — מבוססות על אלגוריתמים הלומדים מנתוני העבר. ברוב מערכי הנתונים בעולם האמיתי, האירועים המשמעותיים נדירים: רק כמה עסקאות הן הונאתיות, רק כמה מטופלים חולים במצב חמור. המקרים הנדירים האלה עלולים לטבוע בתוך המוני הדוגמאות השגרתיות, ומצב זה מסתבך עוד יותר כאשר דפוסי ה"נורמלי" ו"חריג" נראים דומים מאוד. מאמר זה מציג דרך חדשה לאמן מערכות למידת מכונה כך שייתנו תשומת לב ייחודית וחכמה למקרים שקשה לראותם וקל לפספסם.
כשדוגמאות נפוצות מסתירות את הקריטיות
במגוון מערכי נתונים כיתה אחת של דוגמאות מכפילה בהרבה את שאר הכיתות — למשל אלפי עסקאות בטוחות לכל אחת הונאתית. אלגוריתמים סטנדרטיים מנסים למקסם דיוק כולל, ולכן בסופו של דבר מתמקדים ברוב ומתעלמים מהמיעוט. הבעיה מוחמרת כאשר המעמדות השונות חופפות בתכונות הנמדדות, מה שמקשה על ההבחנה ביניהן. בתחומים כמו גילוי הונאות, אבחון רפואי, גילוי תקלות וזיהוי אנומליות, דוגמאות המיעוט הן בדיוק אלו שמעניינות אותנו ביותר, וטעות בסיווגן יכולה להיות יקרה או מסוכנת. המחברים ממקמים את עבודתם סביב האתגר הכפול הזה: גדלים בלתי שווים של כיתות ומעברים חופפים בנתונים מורכבים ובעלי מימד גבוה.
צוות חכם יותר של מסווגים
במקום להסתמך על מודל יחיד, המחברים בונים צוות — או אנסמבל — של מסווגי מכונת וקטור‑תמיכה (SVM), שכל אחד מהם מסתכל על הנתונים באופן שונה (נקראים גרעינים). הרעיון המרכזי הוא להפוך את האנסמבל לדינמי ולמקומי‑מודע. תחילה הנתונים עוברים עיבוד מקדים בקפידה: התכונות מנורמלות כדי להיות בקנה מידה השווה, וטכניקה בשם SMOTE משמשת ליצירת דוגמאות סינתטיות נוספות עבור הכיתות חסרות הייצוג, מה שמאזן את מערכי האימון. 
ללמד מודלים להתמקד בגבולות מטושטשים
הליבה של הגישה היא גרעין חדש "מודע־גבול" שמכוון במכוון להתמקד באזורים שבהם המעמדות חופפים. במהלך האימון השיטה מחפשת דגימות שממוקמות בשכונות עמומות, כפי שנמדד לפי מרחקים לשכנים הקרובים ביותר. דגימות חופפות אלה זוכות לטיפול מיוחד: כל אחת משמשת לאימון SVMים כאשר פונקציית הגרעין שלהן מותאמת על ידי משקל שמשקף עד כמה הדגימה נותנת מידע מקומי. דגימות של כיתת המיעוט בקרבת גבול ההחלטה מקבלות משקלים גבוהים יותר, בעוד דגימות של כיתת הרוב באותן אזורים מקבלות משקל מופחת. למעשה, השיטה מתיחה את פני השטח ההחלטי סביב נקודות נדירות אך חשובות, ועוזרת לצייר קו ברור יותר בין המעמדות מבלי להמציא נתונים נוספים מעבר לנדרש. 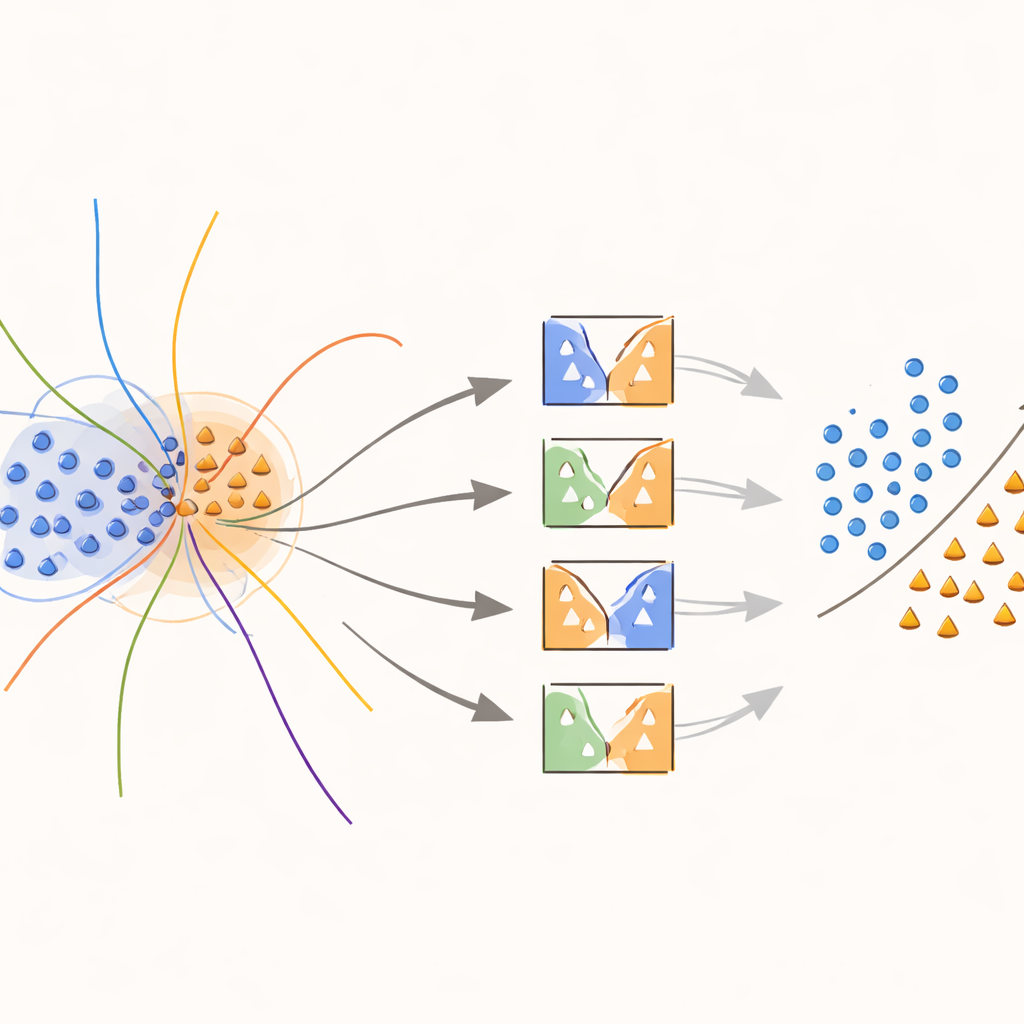
בחירת המומחים הנכונים לכל חיזוי
כאשר מגיע הזמן לנבא את כיתתו של דוגמה חדשה, המערכת לא ממוצעת בעיוורון את דעות כל המודלים. במקום זאת, היא תחילה מסתכלת על דגימות ולידציה סמוכות — מקרים שכבר נראו — ומעריכה את יכולת הכל אחד מהמסווגים באותו אזור מקומי. רק החלק העליון של המודלים, אלה שהטיפלו בהצלחה בדוגמאות דומות בעבר, מורשים להצביע. ההחלטה המשולבת שלהם קובעת את החיזוי הסופי. בחירה מותאמת לדוגמה זו שומרת על חישוביות סבירה ובו בזמן מבטיחה שכל החלטה תתבסס על המודלים שמבינים את זוית המרחב הספציפית בצורה הטובה ביותר.
כמה טוב זה עובד בפועל?
כדי לבחון את שיטתם, החוקרים הריצו ניסויים על 20 מערכי נתונים מרובי־כיתות ו‑20 מערכי נתונים בינאריים ממאגר ציבורי, המכסים משימות מגוונות כגון אבחון רפואי, הערכת איכות והכרה בתבניות. הם השוו את האנסמבל הדינמי שלהם מול בסיסים חזקים, כולל SVM מותאם המשולב עם טכניקת AdaBoost הפופולרית. על פני מערכי הנתונים הגישה החדשה השיגה בעקביות דיוק כולל גבוה יותר ואיזון טוב יותר בין זיהוי נכון של כיתות הרוב והמיעוט, כפי שנמדד על ידי מדד שנקרא G‑mean. במספר רב של מדדים היא גם שמרה על דיוק תחרותי, כלומר נמנעה מהפעלת יותר מדי התרעות שגויות תוך כדי זיהוי יעיל יותר של מקרים נדירים.
מה זה אומר להחלטות בעולם האמיתי
ללא־מומחים, המסקנה היא שהמחברים עיצבו דרך קשובה ומתאימה יותר עבור אלגוריתמים להאזין ל"קולות השקטים" בנתונים. על ידי התמודדות משותפת עם חוסר איזון בגודל הכיתות וגבולות מטושטשים, ועל ידי מתן זכות דיבור רק למודלים הרלוונטיים ביותר בכל החלטה, המסגרת שלהם מפחיתה את הסיכוי שמקרים נדירים אך חיוניים ייחמצו. זה הופך אותה למבטיחה במיוחד ליישומים שבהם החמצת מקרה יוצא דופן — עסקאה הונאתית, רכיב נכשל או סימן מוקדם למחלה — חשובה הרבה יותר מהטעות בסיווג מקרה שגרתי.
ציטוט: Abokadr, S., Azman, A., Hamdan, H. et al. Kernel-based dynamic ensemble approach for classifying imbalanced data with overlapping classes. Sci Rep 16, 13789 (2026). https://doi.org/10.1038/s41598-026-42940-y
מילות מפתח: נתונים לא מאוזנים, מעמדות חופפות, למידת אנסמבל, מכונות וקטור תמיכה, גילוי הונאה ואנומליות