Clear Sky Science · nl
Kernel-gebaseerde dynamische ensemblebenadering voor het classificeren van ongebalanceerde data met overlappende klassen
Waarom zeldzame gevallen in gegevens ertoe doen
Veel beslissingen in het moderne leven — van het opsporen van een frauduleuze creditcardbetaling tot het vroegtijdig herkennen van een ziekte — zijn afhankelijk van algoritmen die leren van historische gegevens. In de meeste reële datasets zijn de belangrijke gebeurtenissen echter zeldzaam: slechts een paar transacties zijn frauduleus, slechts enkele patiënten zijn ernstig ziek. Deze zeldzame gevallen kunnen gemakkelijk worden overschaduwd door de massa van gewone voorbeelden, en het wordt nog moeilijker wanneer de patronen van “normaal” en “abnormaal” sterk op elkaar lijken. Dit artikel introduceert een nieuwe manier om machine‑learning‑systemen te trainen zodat ze op intelligente wijze extra aandacht besteden aan deze moeilijk zichtbare, gemakkelijk te missen gevallen.
Wanneer algemene voorbeelden de cruciale verbergen
In veel datasets overtreft de ene klasse het aantal van de andere klassen sterk — bijvoorbeeld duizenden veilige transacties voor elke frauduleuze transactie. Standaardalgoritmen proberen de algehele nauwkeurigheid te maximaliseren, waardoor ze zich richten op de meerderheid en de minderheid negeren. Het probleem wordt verergerd wanneer de verschillende klassen overlappen in hun gemeten kenmerken, waardoor ze moeilijk te onderscheiden zijn. In domeinen zoals fraudedetectie, medische diagnose, foutdetectie en het opsporen van anomalieën zijn deze minderheidsexemplaren precies de voorbeelden waar het ons om te doen is, en verkeerde classificatie kan kostbaar of gevaarlijk zijn. De auteurs kaderen hun werk rond deze dubbele uitdaging: ongelijke klassengroottes en overlappende grensgebieden in complexe, hoge-dimensionale data.
Een slimmer team van classificatoren
In plaats van te vertrouwen op één enkel model bouwen de auteurs een team — of ensemble — van support vector machine (SVM) classificatoren, elk met verschillende manieren om naar de data te kijken (zogenaamde kernels). Het kernidee is om dit ensemble dynamisch en lokaal bewust te maken. Eerst worden de gegevens zorgvuldig voorbewerkt: kenmerken worden genormaliseerd zodat ze vergelijkbare schalen hebben, en een techniek genaamd SMOTE wordt gebruikt om extra synthetische voorbeelden voor de ondervertegenwoordigde klassen te genereren en zo de trainingssets in balans te brengen. 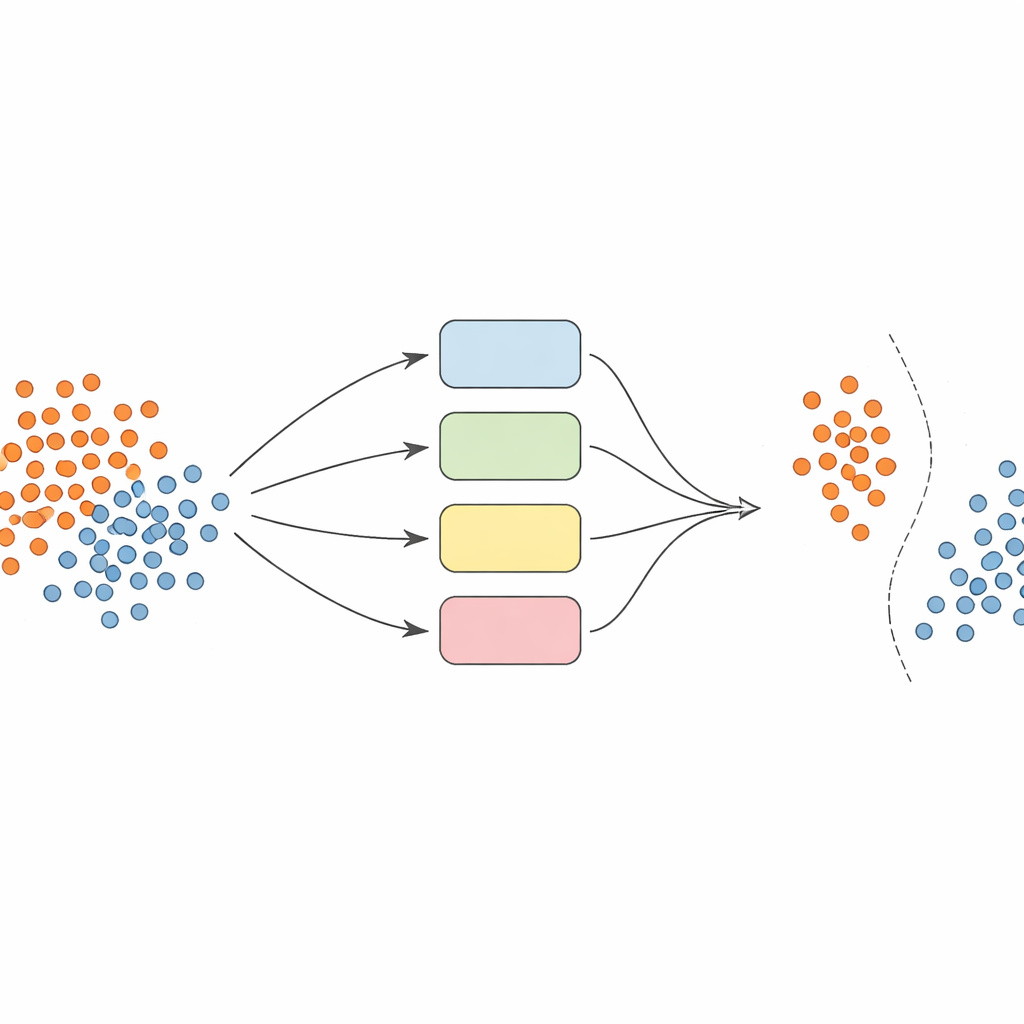
Modellen leren zich te concentreren op vage grenzen
Het hart van de benadering is een nieuwe "boundary‑aware" kernel die doelbewust inspanning concentreert op regio’s waar klassen overlappen. Tijdens training zoekt de methode naar monsters die zich in ambigue buurten bevinden, gemeten aan afstanden tot hun dichtstbijzijnde buren. Deze overlappende voorbeelden krijgen vervolgens speciale behandeling: elk wordt gebruikt om SVM’s te trainen waarvan de kernelfunctie wordt aangepast met een gewicht dat vastlegt hoe informatief dat voorbeeld lokaal is. Voorbeelden uit de minderheidsklasse dicht bij de beslissingsgrens krijgen hogere gewichten, terwijl voorbeelden uit de meerderheidsklasse in die zones worden afgezwakt. In feite rekt de methode het beslissingsvlak uit rond zeldzame maar belangrijke punten, wat helpt een duidelijkere scheidslijn tussen klassen te tekenen zonder meer data te verzinnen dan nodig is. 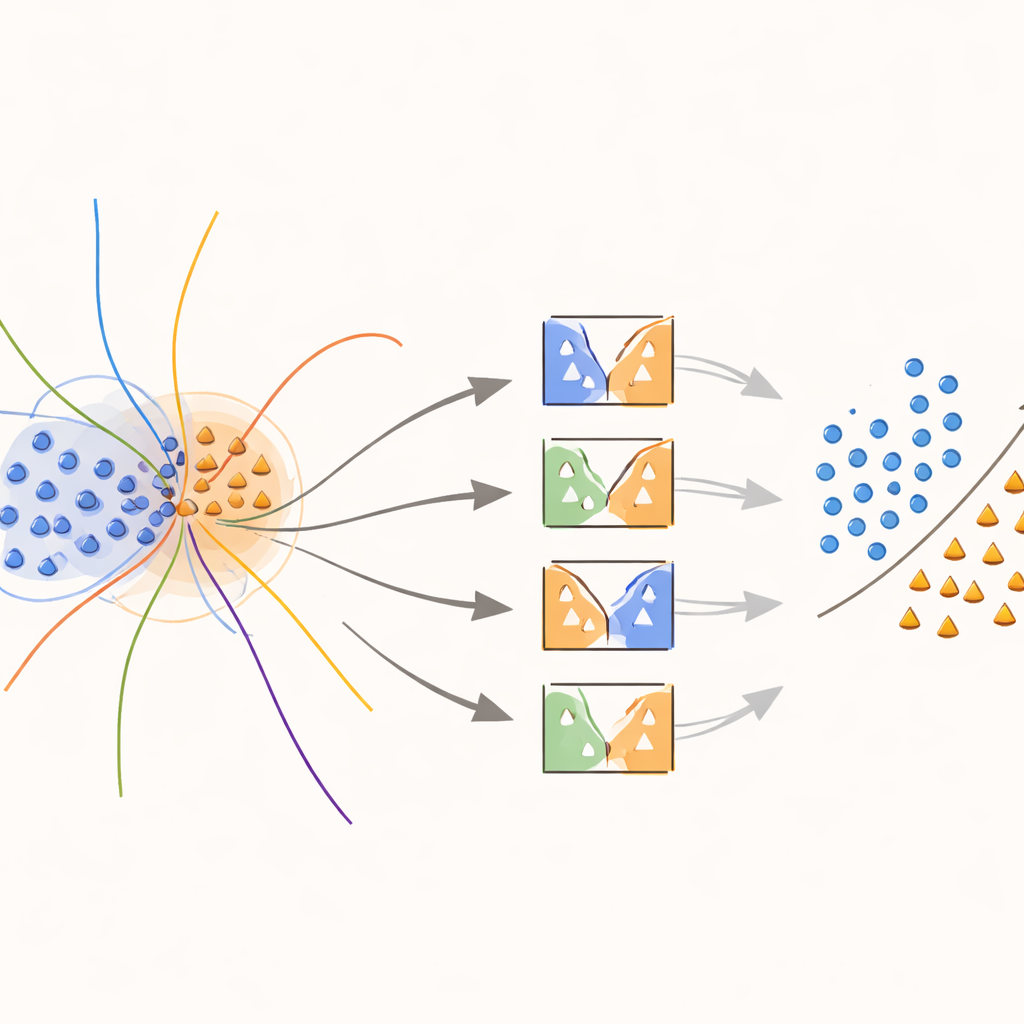
De juiste experts kiezen voor elke voorspelling
Wanneer het tijd is om de klasse van een nieuw voorbeeld te voorspellen, neemt het systeem niet klakkeloos het gemiddelde van alle modelopinies. In plaats daarvan kijkt het eerst naar nabijgelegen validatiemonsters — gevallen die het al heeft gezien — en schat het in hoe bekwaam elke classifier is in die lokale regio. Alleen het best presterende deel van de modellen, degenen die historisch gezien vergelijkbare voorbeelden goed hebben behandeld, mogen stemmen. Hun gecombineerde beslissing bepaalt de uiteindelijke voorspelling. Deze instance‑afhankelijke modelselectie houdt de berekening beheersbaar en zorgt ervoor dat elke beslissing wordt gevormd door de modellen die dat specifieke hoekje van de dataspace het beste begrijpen.
Hoe goed werkt het in de praktijk?
Om hun methode te testen voerden de onderzoekers experimenten uit op 20 multiclass- en 20 binaire datasets uit een openbare repository, met diverse taken zoals medische diagnose, kwaliteitsbeoordeling en patroonherkenning. Ze vergeleken hun dynamische ensemble met sterke baselines, waaronder een aangepaste SVM gecombineerd met de populaire AdaBoost‑techniek. Over de datasets heen behaalde de nieuwe benadering consequent hogere algehele nauwkeurigheid en een betere balans tussen het correct herkennen van meerderheid- en minderheidsklassen, gemeten met een statistiek genaamd G‑mean. In veel benchmarks behield het ook concurrerende precisie, wat betekent dat het niet te veel valse alarmen gaf terwijl het toch zeldzame gevallen effectiever opspoorde.
Wat dit betekent voor beslissingen in de echte wereld
Voor niet‑specialisten is de conclusie dat de auteurs een meer oplettende en aanpasbare manier hebben ontworpen waarop algoritmen naar de "stille stemmen" in data luisteren. Door tegelijkertijd scheve klassengroottes en vage grenzen aan te pakken, en door alleen de meest relevante modellen voor elke beslissing aan het woord te laten, verkleint hun raamwerk de kans dat zeldzame maar vitale gebeurtenissen over het hoofd worden gezien. Dit maakt het vooral veelbelovend voor toepassingen waarin het missen van een ongebruikelijk geval — een frauduleuze transactie, een falend onderdeel of een vroeg teken van ziekte — veel zwaarder weegt dan het verkeerd classificeren van een gewoon geval.
Bronvermelding: Abokadr, S., Azman, A., Hamdan, H. et al. Kernel-based dynamic ensemble approach for classifying imbalanced data with overlapping classes. Sci Rep 16, 13789 (2026). https://doi.org/10.1038/s41598-026-42940-y
Trefwoorden: ongebalanceerde data, overlappende klassen, ensemble learning, support vector machines, fraude- en anomaliedetectie