Clear Sky Science · en
Kernel-based dynamic ensemble approach for classifying imbalanced data with overlapping classes
Why rare cases in data matter
Many decisions in modern life—from spotting a fraudulent credit-card purchase to catching an early sign of disease—depend on algorithms that learn from past data. But in most real-world datasets, the important events are rare: only a few transactions are fraudulent, only a few patients are seriously ill. These rare cases can be easily drowned out by the masses of ordinary examples, and things get even harder when the patterns of “normal” and “abnormal” look very similar. This paper introduces a new way to train machine-learning systems so they pay special, intelligent attention to these hard-to-see, easy-to-miss cases.
When common examples hide the crucial ones
In many datasets, one class of examples greatly outnumbers the others—for instance, thousands of safe transactions for every fraudulent one. Standard algorithms try to maximize overall accuracy, so they end up focusing on the majority and ignoring the minority. The problem is compounded when the different classes overlap in their measured characteristics, making them difficult to distinguish. In areas such as fraud detection, medical diagnosis, fault detection, and anomaly spotting, these minority examples are exactly the ones we most care about, and misclassifying them can be costly or dangerous. The authors frame their work around this double challenge: uneven class sizes and overlapping boundaries in complex, high‑dimensional data.
A smarter team of classifiers
Instead of relying on a single model, the authors build a team—or ensemble—of support vector machine (SVM) classifiers, each using different ways of looking at the data (called kernels). The key idea is to make this ensemble dynamic and locally aware. First, the data are carefully preprocessed: features are normalized so they sit on a comparable scale, and a technique called SMOTE is used to generate additional synthetic examples for the underrepresented classes, balancing the training sets. 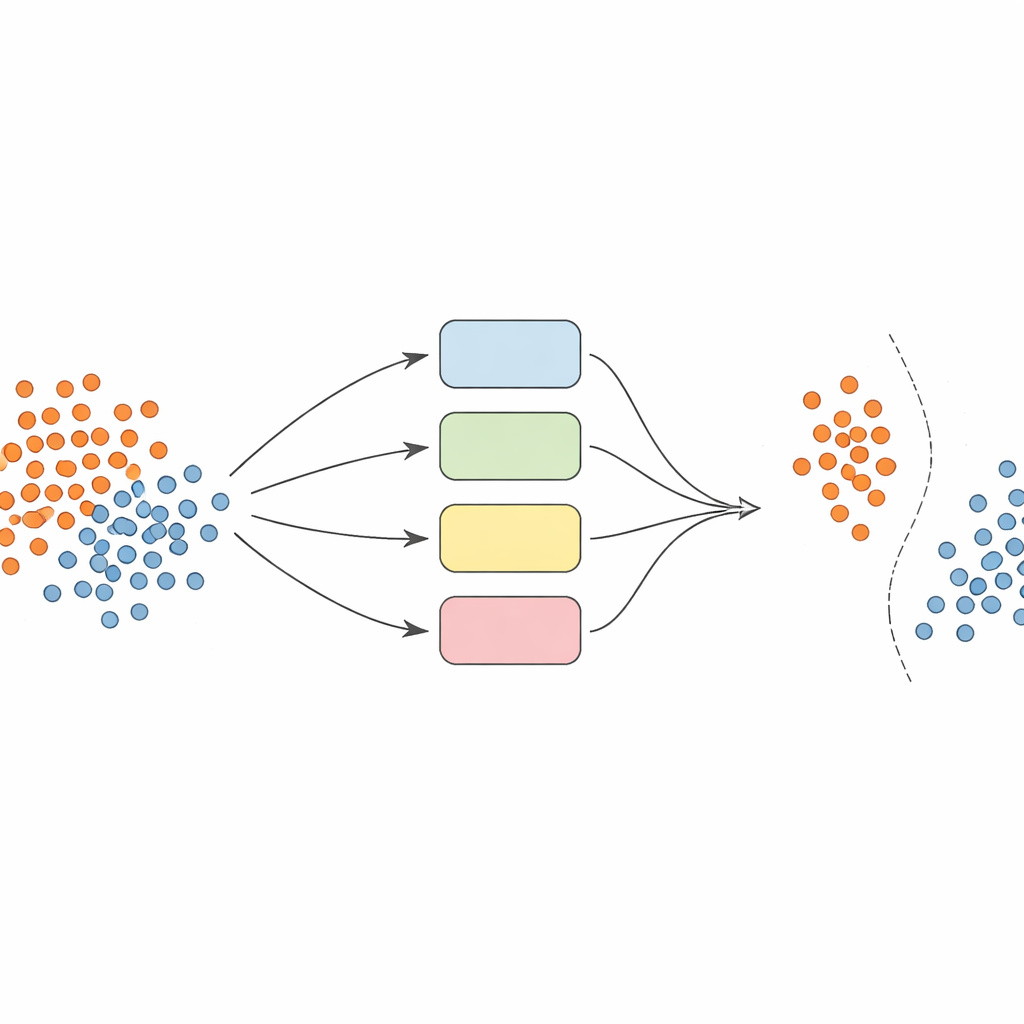
Teaching models to focus on fuzzy borders
The heart of the approach is a new “boundary‑aware” kernel that purposely concentrates effort on regions where classes overlap. During training, the method looks for samples that sit in ambiguous neighborhoods, as measured by distances to their nearest neighbors. These overlapping samples are then given special treatment: each is used to train SVMs whose kernel function is modified by a weight capturing how informative that sample is locally. Minority‑class samples near the decision boundary are given higher weights, while majority‑class samples in those zones are down‑weighted. In effect, the method stretches the decision surface around rare but important points, helping draw a clearer line between classes without inventing more data than necessary. 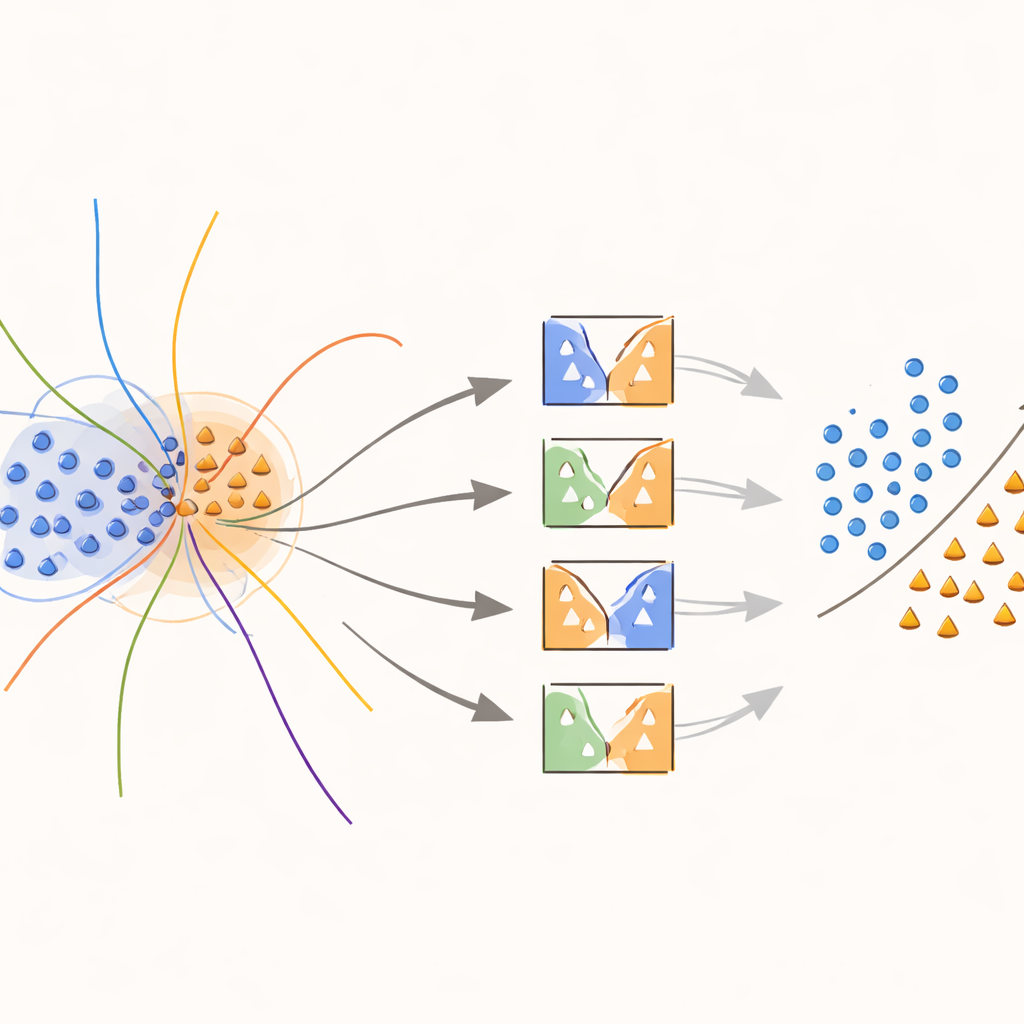
Picking the right experts for each prediction
When it is time to predict the class of a new example, the system does not blindly average the opinions of all models. Instead, it first looks at nearby validation samples—cases it has already seen—and estimates how competent each classifier is in that local region. Only the top‑performing fraction of models, those that historically handled similar examples well, are allowed to vote. Their combined decision determines the final prediction. This instance‑dependent model selection keeps computation manageable while ensuring that each decision is informed by the models that understand that particular corner of the data space best.
How well does it work in practice?
To test their method, the researchers ran experiments on 20 multi‑class and 20 binary datasets from a public repository, covering diverse tasks such as medical diagnosis, quality assessment, and pattern recognition. They compared their dynamic ensemble against strong baselines, including a modified SVM combined with the popular AdaBoost technique. Across datasets, the new approach consistently achieved higher overall accuracy and better balance between correctly recognizing majority and minority classes, as measured by a statistic called G‑mean. In many benchmarks, it also maintained competitive precision, meaning it avoided flagging too many false alarms while still catching rare cases more effectively.
What this means for real-world decisions
For non‑specialists, the takeaway is that the authors have designed a more attentive and adaptable way for algorithms to listen to the “quiet voices” in data. By jointly tackling skewed class sizes and fuzzy boundaries, and by letting only the most relevant models speak for each decision, their framework reduces the chance that rare but vital events are overlooked. This makes it especially promising for applications where missing an unusual case—a fraudulent transaction, a failing component, or an early sign of illness—matters far more than misclassifying an ordinary one.
Citation: Abokadr, S., Azman, A., Hamdan, H. et al. Kernel-based dynamic ensemble approach for classifying imbalanced data with overlapping classes. Sci Rep 16, 13789 (2026). https://doi.org/10.1038/s41598-026-42940-y
Keywords: imbalanced data, overlapping classes, ensemble learning, support vector machines, fraud and anomaly detection