Clear Sky Science · zh
TigCLaF:一种面向低资源提格利尼亚语的跨语言大模型框架,用于情感感知文本分类
超出计算机科学范畴的重要性
每天,说提格利尼亚语的人们都会在社交媒体和新闻网站上分享他们的希望、恐惧和观点。然而大多数现代人工智能系统无法正确解读这些信息,因为与英语或汉语相比,这种语言的数字资源要少得多。本文介绍了 TigCLaF —— 一个新的框架,它能在数据有限且计算资源适中的情况下,高效地教会大规模语言模型理解提格利尼亚语文本的情感倾向。该工作为将强大的语言技术带给其他许多被忽视的语言提供了范式。
把稀缺数据变成优势
作者解决的核心挑战是低资源条件下的情感感知文本分类。这意味着自动判断一段文本是表达积极、消极还是中性情感,同时保留微妙的情绪线索。对提格利尼亚语而言,这很困难:标注数据稀少,古埃及字母(Ge’ez)有自己独特的标点和空格规则,情感通常通过习语和文化指涉来表达。传统模型假设有大量训练集和成熟工具,因此在这种材料上表现欠佳。TigCLaF 的策略是借用在资源丰富语言上训练的多语种模型的知识,并在不从头重训全部参数的情况下,谨慎地将其适配到提格利尼亚语。
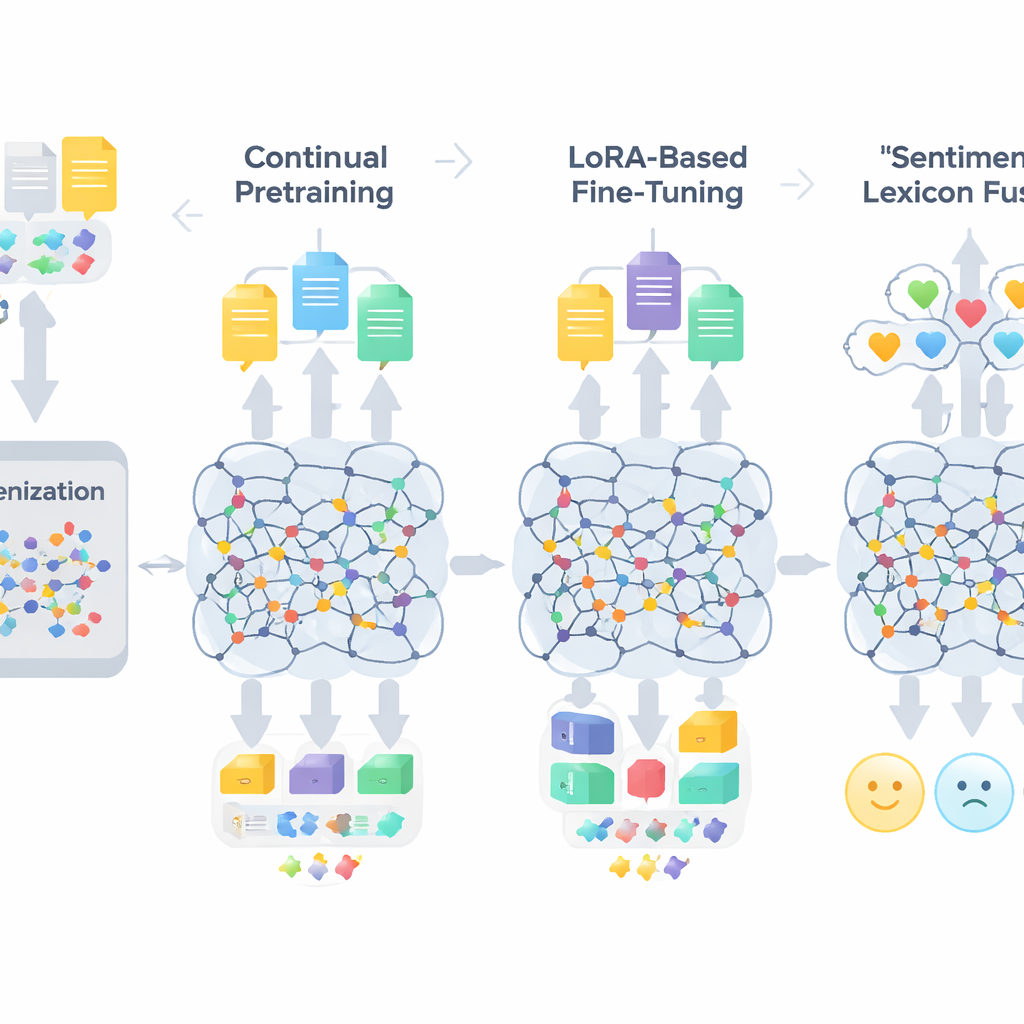
适配大型模型的三步法
TigCLaF 的工作流由三紧密相连的阶段组成。首先,作者扩展了模型的分词器——将文本拆分为单元的组件——通过加入数千个常用的提格利尼亚语子词,减少古埃及文字词的尴尬拆分并改善语言在网络内部的表示。其次,他们在以提格利尼亚语为主、并混入部分英语和阿姆哈拉语的数据上继续对多语种模型进行预训练。在此阶段,系统既完成掩码填充任务,又学习将跨语言的匹配句子在内部空间中拉近,从而加强跨语言对齐。第三步,不是更新全部模型权重,而是应用一种称为 LoRA 的技术,在注意力和前馈层中加入小的适配模块。只有这些轻量模块在包含 3 万条实例的提格利尼亚语情感数据集上进行训练,大幅降低了内存和计算需求。
显式传授情感知识
除了通用的语言适配,该框架还注入了关于情感的显式知识。作者通过将手工构建的词表与来自英语和阿姆哈拉语资源的映射相结合,构建了约 3,200 条目、精简的提格利尼亚语情感词典。每个条目带有极性分数,表示其倾向的正负性。训练过程中,系统将标记映射到这些极性提示,处理否定和程度副词,然后将这些特征与模型的上下文化嵌入融合。一个门控机制学习在每个位置上应给予词典情感线索与上下文多大权重,这有助于处理诸如讽刺、习语和形态复杂的词等棘手情况。
实际效果如何
为评估 TigCLaF,作者整理了一个新的提格利尼亚语情感语料库,来源于 2023 至 2025 年间的社交媒体和新闻,经过精心清洗并由母语者对每条帖子进行标注。他们将该框架与强有力的多语种基线进行比较,包括 mBERT、XLM-RoBERTa、AfriBERTa 以及以上下文提示或自身参数高效微调方式使用的 LLaMA 模型。TigCLaF 达到了最佳总体性能,使宏 F1 分数相比最佳 Transformer 基线最高提升约七个百分点,同时仅更新大约六个百分点的参数。消融研究表明各组件均有贡献:持续预训练带来最大提升,分词器适配与跨语言对齐进一步增强稳健性,而情感词典融合在处理细腻情绪内容上持续改进。该框架在零样本与少样本设置下也能良好迁移到阿姆哈拉语和英语,并且在仅有部分提格利尼亚训练数据时性能平滑下降。
从实验室到现实世界的影响
除了原始指标外,论文还探讨了模型仍然困难的场景——例如频繁的语言混用、讽刺以及新闻与非正式对话之间的领域转移——并指出更好的规范化、比喻语言建模和领域适配可能进一步减少错误。关键是,得益于 LoRA 和量化,TigCLaF 能在普通硬件上高效运行,使其对提格利尼亚语使用地区的机构和社区具有实用性。作者总结认为,该框架既是一个可用的提格利尼亚语情感分析系统,也是将现代语言技术扩展到更多低资源非洲语言的蓝图,帮助确保这些语言不会在人工智能时代被落下。
引用: Gebremeskel, H.G., Feng, C., Abera, A.M. et al. TigCLaF: a cross-lingual large language model framework for sentiment-aware text classification in low-resource tigrigna. Sci Rep 16, 12953 (2026). https://doi.org/10.1038/s41598-026-42786-4
关键词: 提格利尼亚语情感分析, 低资源语言自然语言处理, 跨语言迁移学习, 大规模语言模型, 参数高效微调