Clear Sky Science · ru
TigCLaF: рамочная система для кросс-языковых больших языковых моделей для классификации тональности текста с учётом эмоций в условиях малоресурсного тигринья
Почему это важно за пределами информатики
Каждый день носители тигринья делятся надеждами, страхами и мнениями в социальных сетях и на новостных сайтах. Однако большинство современных систем искусственного интеллекта не умеют правильно «читать» эти сообщения, потому что для этого языка доступно намного меньше цифровых ресурсов, чем для английского или китайского. В статье представлен TigCLaF — новая система, которая эффективно обучает большие языковые модели распознавать эмоциональную окраску текста на тигринья, используя ограниченные данные и умеренные вычислительные ресурсы. Эта работа предлагает шаблон для переноса мощных языковых технологий на многие другие недопредставленные языки.
Превращая скудные данные в преимущество
Ключевая задача, которую решают авторы, — это классификация тональности текста в условиях малых ресурсов. Речь о том, чтобы автоматически определять, выражает ли текст положительную, отрицательную или нейтральную эмоцию, сохраняя тонкие эмоциональные оттенки. Для тигринья это сложно: мало размеченных наборов данных, письмо на письме гээз имеет свои правила пунктуации и разбиения слов, а эмоции часто передаются идиомами и культурными отсылками. Обычные модели предполагают огромные обучающие корпуса и развитые инструменты, поэтому на таком материале они дают сбои. TigCLaF отвечает на это повторным использованием знаний из многоязычных моделей, обученных на ресурсных языках, и аккуратной адаптацией этих знаний к тигринья без перекалибровки всей модели с нуля.
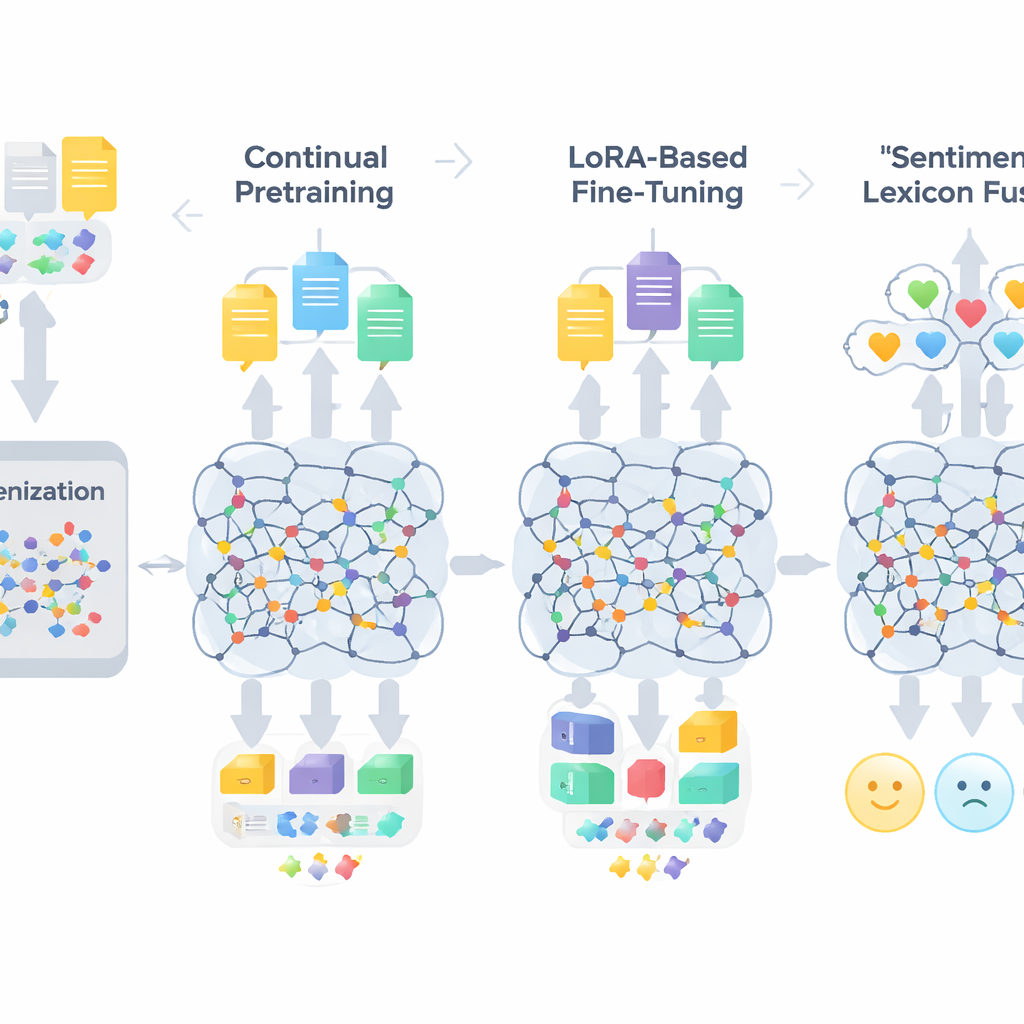
Трёхэтапный рецепт адаптации больших моделей
Рабочий процесс TigCLaF включает три тесно связанные стадии. Сначала авторы расширяют токенизатор модели — компонент, который разбивает текст на единицы — добавляя тысячи часто используемых подслов тигринья. Это уменьшает неестественное дробление слов в письменности гээз и улучшает представление языка внутри сети. Затем они продолжают предварительное обучение многоязычной модели на смеси данных, в основном тигринья, с небольшими примесями английского и амхарского. На этом этапе система и восстанавливает замаскированные слова, и учится сближать соответствующие предложения на разных языках в своём внутреннем пространстве, усиливая кросс-лингвистическое выравнивание. Третья стадия: вместо обновления всех весов модели применяют метод под названием LoRA, который добавляет небольшие адаптерные модули в слои внимания и полносвязные слои. Обучаются только эти лёгкие компоненты на наборе данных по тональности тигринья из 30 000 экземпляров, что значительно сокращает требования к памяти и вычислениям.
Явное обучение модели признакам эмоций
Помимо общей языковой адаптации, система вводит явные знания об эмоциях. Авторы создают компактный лексикон тональности тигринья примерно из 3 200 записей, комбинируя вручную составленный список слов с проекциями из английских и амхарских ресурсов. Каждая запись снабжена показателем полярности, указывающим, насколько слово склонно быть положительным или отрицательным. Во время обучения система сопоставляет токены с этими полярностными подсказками, учитывает отрицания и усилители, а затем объединяет эти признаки с контекстными встраиваниями модели. С помощью механизма с затворами модель учится определять, какое значение придавать лексическим сигналам тональности по сравнению с окружающим контекстом в каждой позиции, что помогает в сложных случаях — сарказме, идиомах и морфологически сложных словах.
Как это работает на практике
Для проверки TigCLaF авторы собирают новый корпус данных по тональности на тигринья из социальных сетей и новостных источников за 2023–2025 годы, тщательно очищают данные и привлекают носителей языка для разметки каждой публикации. Они сравнивают свою систему с сильными многоязычными базовыми моделями, включая mBERT, XLM-RoBERTa, AfriBERTa и модели LLaMA, применённые как с подсказками в контексте, так и с собственными эффективными по параметрам донастройками. TigCLaF показывает наилучшее общее качество, повышая макро-F1 примерно до семи процентных пунктов по сравнению с лучшими трансформерными базовыми моделями, при этом обновляя всего около шести процентов параметров. Исследования-абляции показывают, что каждый компонент вносит вклад: непрерывное предварительное обучение даёт наибольший прирост, адаптация токенизатора и кросс-лингвистическое выравнивание дополнительно повышают устойчивость, а слияние с лексиконом тональности последовательно улучшает обработку тонких эмоциональных оттенков. Фреймворк также хорошо переносится на амхарский и английский в режимах zero-shot и few-shot и деградирует плавно, если доступна лишь часть обучающей выборки по тигринья.
От лабораторного эксперимента к реальному воздействию
Помимо сырых метрик, статья исследует, где модель всё ещё испытывает сложности — например, при сильном код-свитчинге, сарказме и переносе доменов между новостями и неформальными беседами — и утверждает, что лучшая нормализация, моделирование образного языка и адаптация к доменам могли бы ещё больше снизить число ошибок. Важно, что TigCLaF эффективно работает на обычном оборудовании благодаря LoRA и квантизации, что делает его практичным для учреждений и сообществ в регионах, где говорят на тигринья. Авторы делают вывод, что их система одновременно является рабочим решением для анализа тональности на тигринья и шаблоном для распространения современных языковых технологий на многие другие малоресурсные африканские языки, помогая не допустить их отставания в эпоху ИИ.
Цитирование: Gebremeskel, H.G., Feng, C., Abera, A.M. et al. TigCLaF: a cross-lingual large language model framework for sentiment-aware text classification in low-resource tigrigna. Sci Rep 16, 12953 (2026). https://doi.org/10.1038/s41598-026-42786-4
Ключевые слова: анализ тональности тигринья, обработка естественного языка для малоресурсных языков, кросс-лингвистический перенос обучения, большие языковые модели, эффективная по числу параметров донастройка