Clear Sky Science · pl
TigCLaF: ramy wielojęzykowego modelu dużej skali do klasyfikacji tekstu z uwzględnieniem sentymentu w zasobach niskich dla tigrinia
Dlaczego ma to znaczenie wykraczające poza informatykę
Codziennie osoby mówiące po tigrinia dzielą się swoimi nadziejami, obawami i opiniami w mediach społecznościowych oraz serwisach informacyjnych. Większość nowoczesnych systemów sztucznej inteligencji jednak nie potrafi poprawnie odczytywać tych komunikatów, ponieważ język ten dysponuje znacznie mniejszą liczbą zasobów cyfrowych niż angielski czy chiński. W artykule przedstawiono TigCLaF, nową ramę, która uczy duże modele językowe efektywnego rozumienia tonu emocjonalnego tekstów w tigrinia, wykorzystując ograniczone dane i umiarkowaną moc obliczeniową. Praca ta stanowi wzorzec pozwalający przenieść zaawansowane technologie językowe do wielu innych niedoreprezentowanych języków.
Przekształcanie ograniczonych danych w zaletę
Głównym wyzwaniem, któremu autorzy sprostali, jest klasyfikacja tekstu z uwzględnieniem sentymentu w warunkach niskich zasobów. Oznacza to automatyczne określenie, czy fragment tekstu wyraża uczucie pozytywne, negatywne czy neutralne, przy zachowaniu subtelnych sygnałów emocjonalnych. W przypadku tigrinia jest to trudne: brakuje oznakowanych zbiorów danych, pismo Ge’ez ma własne zasady interpunkcji i odstępów, a sentyment bywa wyrażany przez idiomy i odniesienia kulturowe. Konwencjonalne modele zakładają ogromne zbiory treningowe i rozbudowane narzędzia, więc słabną na takim materiale. TigCLaF odpowiada na to, ponownie wykorzystując wiedzę z modeli wielojęzykowych trenowanych na bogatych danych i ostrożnie dostosowując ją do tigrinia bez konieczności ponownego trenowania wszystkiego od zera.
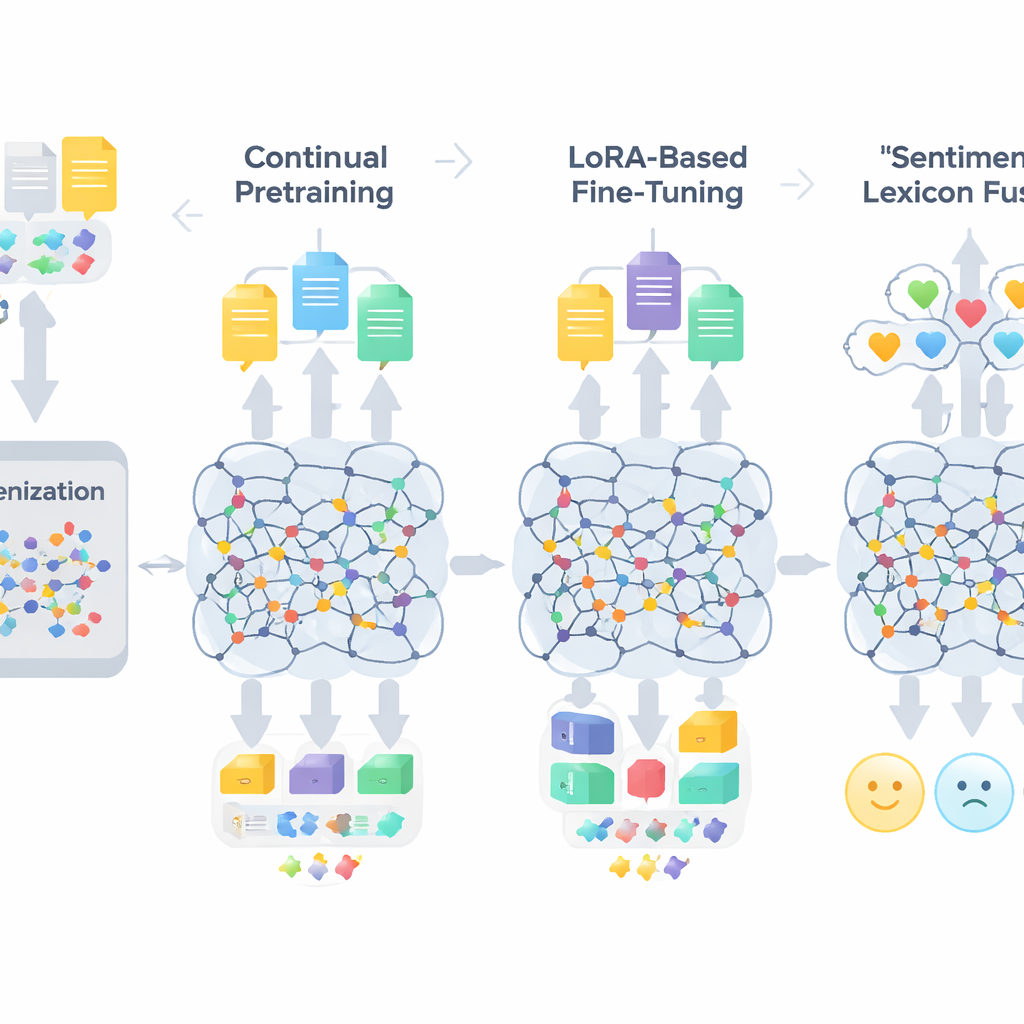
Trzystopniowy przepis na adaptację dużych modeli
Workflow TigCLaF składa się z trzech ściśle powiązanych etapów. Najpierw autorzy rozszerzają tokenizer modelu — część, która dzieli tekst na jednostki — dodając tysiące często używanych tigrinia subwords. Zmniejsza to nienaturalne dzielenie słów w piśmie Ge’ez i poprawia reprezentację języka w sieci. Po drugie, kontynuują wstępne trenowanie modelu wielojęzykowego na mieszance danych głównie w tigrinia, z dodatkiem angielskiego i amharskiego. Na tym etapie system uzupełnia maskowane słowa i uczy się zbliżać odpowiadające sobie zdania między językami w przestrzeni wewnętrznej, wzmacniając wyrównanie międzyjęzykowe. Po trzecie, zamiast aktualizować wszystkie wagi modelu, stosują technikę nazwaną LoRA, która dodaje małe moduły adapterowe do warstw uwagi i warstw przetwarzania. Tylko te lekkie komponenty są trenowane na 30‑tysięcznym zbiorze danych sentymentu w tigrinia, co dramatycznie redukuje zapotrzebowanie na pamięć i obliczenia.
Nauczanie modelu o emocjach w sposób jawny
Ponad ogólną adaptacją językową, rama wprowadza jawne informacje o emocjach. Autorzy zbudowali kompaktowy słownik sentymentu w tigrinia liczący około 3 200 wpisów, łącząc ręcznie opracowaną listę słów z projekcjami ze źródeł angielskich i amharskich. Każdy wpis ma przypisany wskaźnik polaryzacji wskazujący, na ile dana jednostka zwykle jest pozytywna lub negatywna. W trakcie treningu system mapuje tokeny na te wskazówki polaryzacji, obsługuje negację i wzmacniacze, a następnie łączy te cechy z kontekstowymi osadzeniami modelu. Mechanizm bramkowy uczy się, jaką wagę nadać leksykalnym wskazówkom sentymentu względem otaczającego kontekstu na każdej pozycji, co pomaga w trudnych przypadkach, takich jak sarkazm, idiomy i morfologicznie złożone słowa.
Jak to działa w praktyce
Aby przetestować TigCLaF, autorzy przygotowali nowy korpus sentymentu w tigrinia z mediów społecznościowych i portali informacyjnych z lat 2023–2025, starannie oczyszczając dane i zlecając rodzimym mówcom etykietowanie każdego wpisu. Porównali swoją ramę z silnymi wielojęzykowymi punktami odniesienia, w tym mBERT, XLM‑RoBERTa, AfriBERTa oraz modelami LLaMA używanymi albo z promptingiem in‑context, albo z własnym efektywnym parametrycznie dostrajaniem. TigCLaF osiąga najlepsze wyniki ogólne, podnosząc makro F1 o około siedem punktów procentowych względem najlepszych bazowych transformatorów, przy aktualizacji zaledwie około sześciu procent parametrów. Badania ablacyjne pokazują, że każdy element wnosi wkład: ciągłe wstępne trenowanie daje największy wzrost, adaptacja tokenizera i wyrównanie międzyjęzykowe dodatkowo poprawiają odporność, a integracja słownika sentymentu konsekwentnie ułatwia obsługę zniuansowanych treści emocjonalnych. Rama dobrze przenosi się także na amharski i angielski w ustawieniach zero‑shot i few‑shot i degradacja jest stopniowa, gdy dostępna jest tylko część danych treningowych w tigrinia.
Od eksperymentu laboratoryjnego do realnego wpływu
Poza surowymi liczbami artykuł analizuje obszary, w których model nadal ma trudności — takie jak intensywne przełączanie kodu (code‑switching), sarkazm i zmiany domeny między wiadomościami a rozmowami nieformalnymi — i argumentuje, że lepsza normalizacja, modelowanie języka figuratywnego oraz adaptacja domenowa mogłyby dodatkowo zmniejszyć liczbę błędów. Co kluczowe, TigCLaF działa wydajnie na sprzęcie konsumenckim dzięki LoRA i kwantyzacji, co czyni go praktycznym dla instytucji i społeczności w regionach mówiących po tigrinia. Autorzy konkludują, że ich rama jest zarówno działającym systemem analizy sentymentu dla tigrinia, jak i planem działania do rozszerzenia nowoczesnych technologii językowych na wiele innych afrykańskich języków o niskich zasobach, pomagając zapewnić, że nie zostaną one pozostawione w tyle w erze AI.
Cytowanie: Gebremeskel, H.G., Feng, C., Abera, A.M. et al. TigCLaF: a cross-lingual large language model framework for sentiment-aware text classification in low-resource tigrigna. Sci Rep 16, 12953 (2026). https://doi.org/10.1038/s41598-026-42786-4
Słowa kluczowe: analiza sentymentu w tigrinia, przetwarzanie języka naturalnego dla języków o niskich zasobach, uczenie transferowe międzyjęzykowe, modele dużej skali, efektywne parametrycznie dostrajanie