Clear Sky Science · fr
TigCLaF : un cadre de modèles linguistiques multilingues pour la classification de texte sensible au sentiment en tigrigna à ressources limitées
Pourquoi cela compte au-delà de l’informatique
Chaque jour, des locuteurs du tigrigna partagent leurs espoirs, leurs craintes et leurs opinions sur les réseaux sociaux et les sites d’information. Pourtant, la plupart des systèmes d’intelligence artificielle modernes ne lisent pas correctement ces messages, car la langue dispose de bien moins de ressources numériques que l’anglais ou le chinois. Cet article présente TigCLaF, un nouveau cadre qui apprend aux grands modèles de langage à comprendre le ton émotionnel des textes en tigrigna de manière efficace, en utilisant des données limitées et des ressources de calcul modestes. Ce travail propose un modèle pour apporter des technologies linguistiques puissantes à de nombreuses autres langues sous-représentées.
Transformer la rareté des données en atout
Le défi central que les auteurs relèvent est la classification de texte sensible au sentiment dans un contexte à faibles ressources. Il s’agit de déterminer automatiquement si un texte exprime un sentiment positif, négatif ou neutre tout en conservant des nuances émotionnelles subtiles. Pour le tigrigna, c’est difficile : il existe peu de jeux de données annotés, l’écriture guèze (Ge’ez) a ses propres règles de ponctuation et d’espacement, et le sentiment s’exprime souvent par des idiomes et des références culturelles. Les modèles classiques supposent de vastes jeux d’entraînement et des outils bien développés, et ils peinent sur ce type de matériau. TigCLaF répond en réutilisant les connaissances de modèles multilingues entraînés sur des langues riches en données et en les adaptant soigneusement au tigrigna sans tout réentraîner depuis zéro.
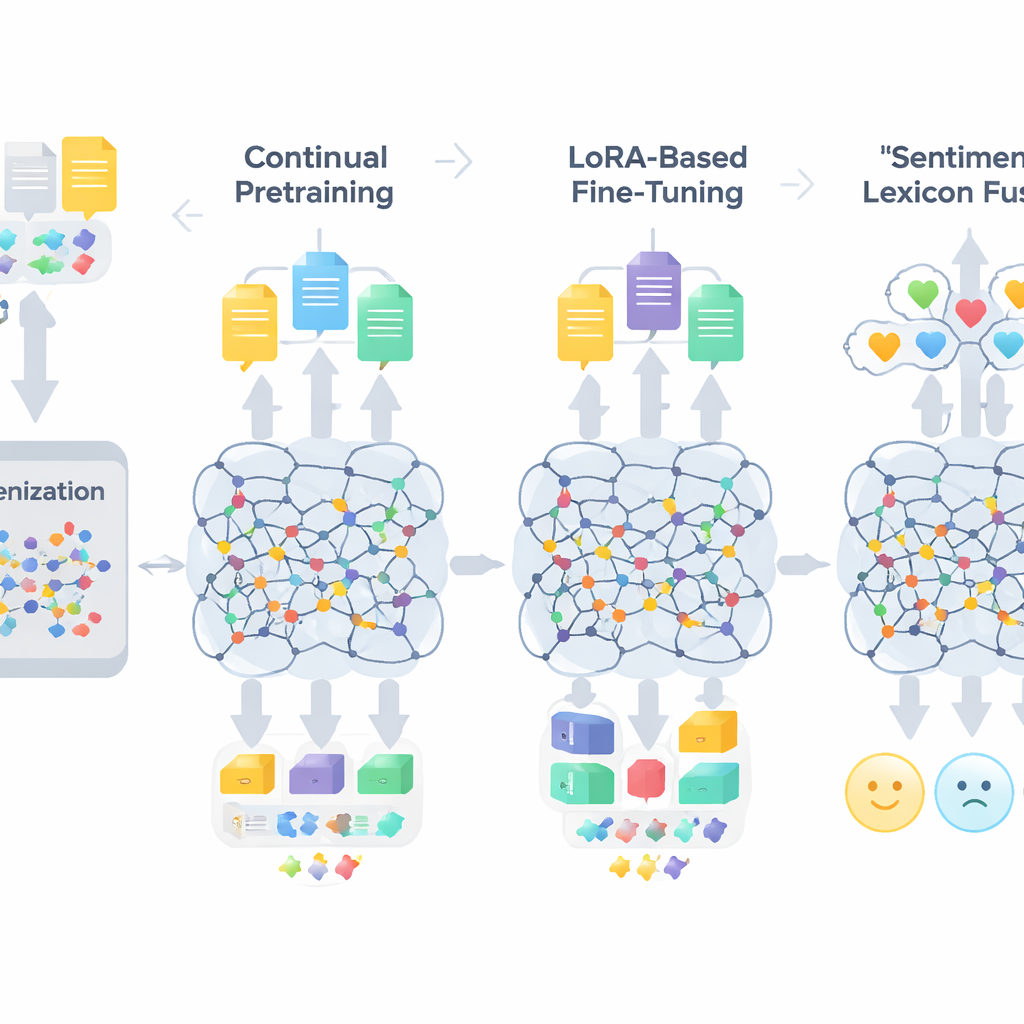
Une recette en trois étapes pour adapter les grands modèles
Le flux de travail de TigCLaF se compose de trois étapes étroitement liées. D’abord, les auteurs étendent le tokenizer du modèle — la partie qui segmente le texte en unités — en ajoutant des milliers de sous-mots tigrigna fréquents. Cela réduit les coupures inappropriées des mots en écriture guèze et améliore la représentation de la langue à l’intérieur du réseau. Ensuite, ils poursuivent le préentraînement du modèle multilingue sur un mélange principalement tigrigna, avec un peu d’anglais et d’amharique. Pendant cette phase, le système complète des mots masqués et apprend à rapprocher dans son espace interne les phrases correspondantes entre langues, renforçant l’alignement cross-lingual. Troisièmement, au lieu de mettre à jour l’ensemble des poids du modèle, ils appliquent une technique appelée LoRA, qui ajoute de petits modules adaptateurs aux couches d’attention et feed-forward. Seules ces pièces légères sont entraînées sur le jeu de données de sentiment tigrigna de 30 000 instances, réduisant radicalement les besoins en mémoire et en calcul.
Enseigner explicitement au modèle les émotions
Outre l’adaptation linguistique générale, le cadre injecte une connaissance explicite des émotions. Les auteurs construisent un lexique compact de sentiment en tigrigna d’environ 3 200 entrées en combinant une liste de mots manuelle avec des projections provenant de ressources anglaises et amhariques. Chaque entrée porte un score de polarité indiquant sa tendance positive ou négative. Lors de l’entraînement, le système associe des tokens à ces indices de polarité, gère la négation et les intensificateurs, puis fusionne ces caractéristiques avec les embeddings contextuels du modèle. Un mécanisme à portes apprend combien de poids accorder aux indices lexicaux de sentiment par rapport au contexte environnant à chaque position, ce qui aide dans les cas délicats comme le sarcasme, les idiomes et les mots à morphologie complexe.
Quelle est l’efficacité en pratique
Pour évaluer TigCLaF, les auteurs constituent un nouveau corpus de sentiment en tigrigna à partir des réseaux sociaux et de sources d’actualité entre 2023 et 2025, en nettoyant soigneusement les données et en faisant annoter chaque publication par des locuteurs natifs. Ils comparent leur cadre à des références multilingues solides, notamment mBERT, XLM-RoBERTa, AfriBERTa et des modèles LLaMA utilisés soit avec des prompts en contexte, soit avec leur propre ajustement paramétrique efficace. TigCLaF obtient les meilleures performances globales, augmentant les scores macro F1 d’environ sept points de pourcentage au maximum par rapport aux meilleurs baselines transformeurs, tout en ne mettant à jour qu’environ six pour cent des paramètres. Les études d’ablation montrent que chaque composant apporte sa contribution : le préentraînement continu fournit le plus grand gain, l’adaptation du tokenizer et l’alignement cross-lingual renforcent la robustesse, et la fusion avec le lexique de sentiment améliore systématiquement le traitement des contenus émotionnels nuancés. Le cadre se transfère aussi bien à l’amharique et à l’anglais en configuration zero-shot et few-shot et se dégrade progressivement lorsque seule une fraction des données tigrigna est disponible.
De l’expérience de laboratoire à l’impact dans le monde réel
Au-delà des chiffres bruts, l’article examine les situations où le modèle rencontre encore des difficultés — comme le fort code-switching, le sarcasme et les changements de domaine entre info et conversations informelles — et soutient qu’une meilleure normalisation, la modélisation du langage figuré et l’adaptation de domaine pourraient réduire davantage les erreurs. De façon cruciale, TigCLaF fonctionne efficacement sur du matériel courant grâce à LoRA et à la quantification, ce qui le rend pratique pour les institutions et communautés des régions tigrigna. Les auteurs concluent que leur cadre constitue à la fois un système opérationnel d’analyse des sentiments pour le tigrigna et une feuille de route pour étendre les technologies linguistiques modernes à de nombreuses autres langues africaines à faibles ressources, contribuant à éviter leur exclusion à l’ère de l’IA.
Citation: Gebremeskel, H.G., Feng, C., Abera, A.M. et al. TigCLaF: a cross-lingual large language model framework for sentiment-aware text classification in low-resource tigrigna. Sci Rep 16, 12953 (2026). https://doi.org/10.1038/s41598-026-42786-4
Mots-clés: analyse des sentiments en tigrigna, TAL pour langue à ressources limitées, apprentissage par transfert cross-lingual, grands modèles de langage, ajustement de paramètres efficace