Clear Sky Science · ar
TigCLaF: إطار عمل متعدد اللغات لنماذج اللغة الكبيرة لتصنيف النصوص مع الوعي بالمشاعر بلغة التغرينية منخفضة الموارد
لماذا هذا مهم خارج علوم الحاسوب
يومياً يشارك متحدثو التغرينية آمالهم ومخاوفهم وآرائهم على وسائل التواصل الاجتماعي ومواقع الأخبار. ومع ذلك، فإن معظم أنظمة الذكاء الاصطناعي الحديثة غير قادرة على فهم هذه الرسائل بصورة سليمة، لأن اللغة تملك موارد رقمية أقل بكثير من الإنجليزية أو الصينية. يقدم هذا المقال TigCLaF، إطار عمل جديد يُعلّم نماذج اللغة الكبيرة كيفية استيعاب النبرة العاطفية للنصوص بالتغرينية بكفاءة، باستخدام بيانات محدودة وقوة حسابية متواضعة. يقدم العمل نموذجاً لنشر تقنيات لغوية قوية إلى لغات أخرى ممثلة تمثيلاً ناقصاً.
تحويل قلة البيانات إلى نقطة قوة
التحدي الأساسي الذي يعالجه المؤلفون هو تصنيف النص مع الوعي بالمشاعر في بيئة منخفضة الموارد. أي تحديد تلقائي ما إذا كان النص يعبر عن شعور إيجابي أو سلبي أو محايد مع الحفاظ على الدلالات العاطفية الدقيقة. بالنسبة للتغرينية، هذا صعب: مجموعات البيانات الموسومة قليلة، لخط الجعزية قواعد ترقيم ومسافات خاصة به، وغالباً ما تُعبَّر المشاعر عبر تعابير اصطلاحية وإشارات ثقافية. تفترض النماذج التقليدية مجموعات تدريب ضخمة وأدوات متطورة، لذا تتعثر مع مثل هذا المحتوى. يستجيب TigCLaF بإعادة استخدام المعرفة من نماذج متعددة اللغات مدرَّبة على لغات غنية بالبيانات وتكييفها بعناية للتغرينية دون إعادة تدريب كل شيء من الصفر.
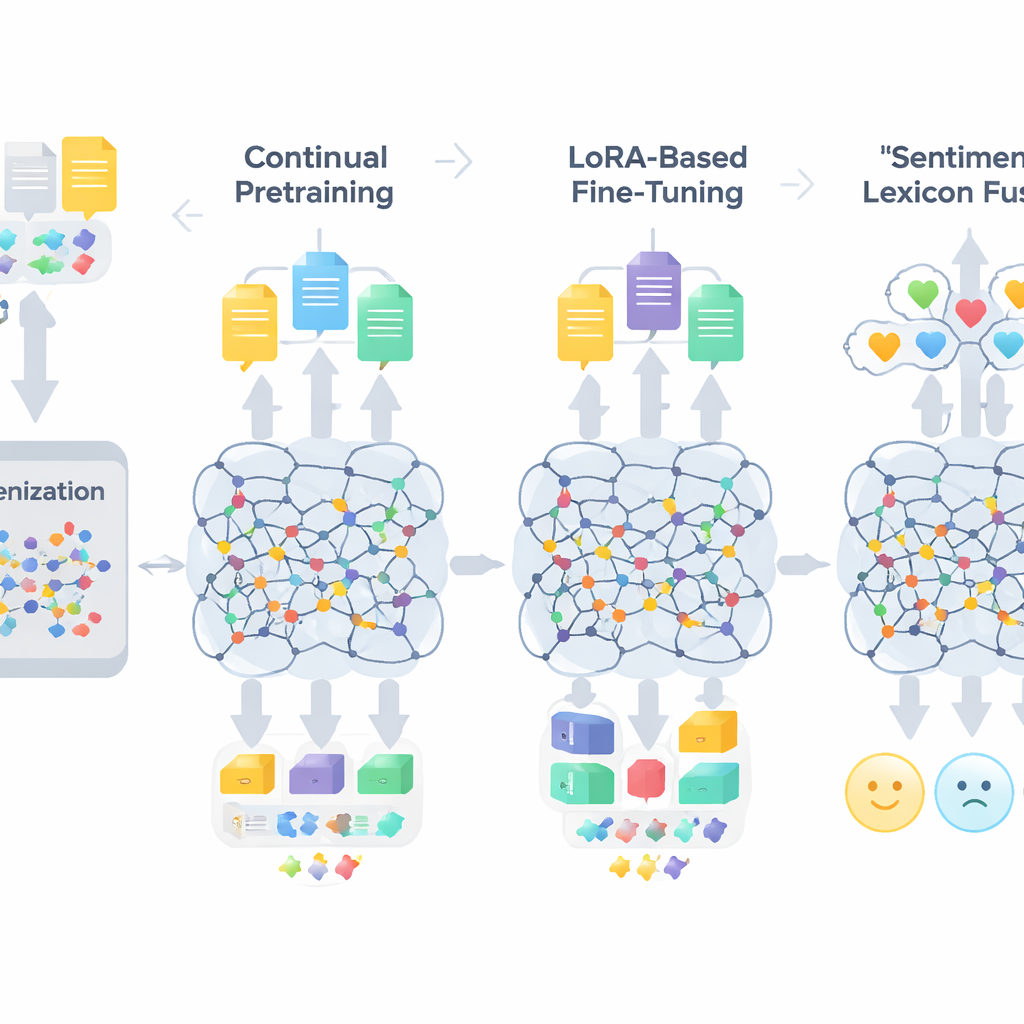
وصفة من ثلاث خطوات لتكييف النماذج الكبيرة
يتألف سير عمل TigCLaF من ثلاث مراحل مترابطة بإحكام. أولاً، يوسِّعون مفكك الرموز (الجزء الذي يقسم النص إلى وحدات) بإضافة آلاف الوحدات الفرعية الشائعة بالتغرينية. هذا يقلل من تقسيم كلمات الخط الجعزي بشكل غريب ويحسن كيفية تمثيل اللغة داخل الشبكة. ثانياً، يستكملون التدريب المسبق للنموذج متعدد اللغات على خليط يحتوي في الغالب على تغرينية، مع بعض الإنجليزية والأمهرية. خلال هذه المرحلة، يملأ النظام الكلمات المخفية ويتعلم أيضاً تقريب الجمل المطابقة عبر اللغات داخل فضائه الداخلي، مما يقوي المحاذاة عبر اللغات. ثالثاً، بدلاً من تحديث كل أوزان النموذج، يطبقون تقنية تسمى LoRA، التي تضيف وحدات محولة صغيرة إلى طبقات الانتباه والطبقات التغذية الأمامية. تُدرَّب هذه الأجزاء الخفيفة فقط على مجموعة بيانات المشاعر بالتغرينية المكونة من نحو 30,000 عينة، ما يقلل بشكل كبير من متطلبات الذاكرة والحساب.
تعليم النموذج بالمشاعر بشكل صريح
إلى جانب التكييف العام للغة، يحقن الإطار معرفة صريحة عن العواطف. يبني المؤلفون معجم مشاعر تغريني مدمج يضم نحو 3,200 إدخال عبر الجمع بين قائمة كلمات مصنوعة يدوياً وإسقاطات من موارد الإنجليزية والأمهرية. يحمل كل إدخال درجة قطبية تشير إلى ميله نحو الإيجابية أو السلبية. أثناء التدريب، يطابق النظام الرموز مع تلميحات القطبية هذه، ويتعامل مع النفي والمعزِّزات، ثم يدمج هذه السمات مع التمثيلات السياقية للنموذج. يتعلَّم آلية مسوَّرة مقدار الثقل الذي يُعطى للمؤشرات المعجمية مقابل السياق المحيط في كل موضع، مما يساعد في الحالات الشائكة مثل السخرية والتعابير الاصطلاحية والكلمات المعقدة صرفياً.
مدى فاعليته عملياً
لاختبار TigCLaF، يجمع المؤلفون مجموعة بيانات مشاعر جديدة بالتغرينية من وسائل التواصل الاجتماعي والمنافذ الإخبارية بين 2023 و2025، مع تنظيف دقيق للبيانات واعتماد متحدثين أصليين لوضع الوسوم على كل منشور. يقارنون إطارهم مع قواعد أساسية متعددة اللغات قوية، بما في ذلك mBERT وXLM-RoBERTa وAfriBERTa ونماذج LLaMA المستخدمة إما باستدعاء الأمثلة في السياق أو مع ضبطها بكفاءة على المعلمات. يحقق TigCLaF أفضل أداء إجمالي، رافعاً درجات F1 الماكرو بما يصل إلى نحو سبع نقاط مئوية فوق أفضل قواعد المحولات، مع تحديث ما يقارب ستة بالمئة فقط من المعلمات في أسوأ الأحوال. تظهر دراسات الإقصاء أن كل مكوّن يساهم: يقدّم التدريب المستمر أكبر تعزيز، بينما يعزّز تعديل المفكك والمحاذاة عبر اللغات المتانة، ويسهم دمج معجم المشاعر باستمرار في تحسين التعامل مع المحتوى العاطفي الدقيق. ينتقل الإطار أيضاً بشكل جيد إلى الأمهرية والإنجليزية في إعدادات الصفر-طلقة والقليل-الطلقة ويتدهور بسلاسة عندما تتاح نسبة صغيرة فقط من بيانات التدريب بالتغرينية.
من تجربة مخبرية إلى تأثير في العالم الواقعي
بعيداً عن الأرقام الخام، يستكشف المقال مواطن الضعف التي لا يزال النموذج يواجهها—مثل التناوب المكثف بين اللغات (code-switching) والسخرية وتحولات النطاق بين الأخبار والمحادثات غير الرسمية—ويؤكد أن تحسين التطبيع، ونمذجة اللغة المجازية، والتكييف على النطاق يمكن أن يقلل الأخطاء أكثر. والأهم أن TigCLaF يعمل بكفاءة على أجهزة تجارية بفضل LoRA والكمية (quantization)، مما يجعله عملياً للمؤسسات والمجتمعات في مناطق الناطقة بالتغرينية. يخلص المؤلفون إلى أن إطارهم يعد نظام تحليل مشاعر عملي للتغرينية وخارطة طريق لتوسيع تقنيات اللغة الحديثة إلى لغات أفريقية منخفضة الموارد أخرى، مما يساعد على ضمان عدم تركها خلف الركب في عصر الذكاء الاصطناعي.
الاستشهاد: Gebremeskel, H.G., Feng, C., Abera, A.M. et al. TigCLaF: a cross-lingual large language model framework for sentiment-aware text classification in low-resource tigrigna. Sci Rep 16, 12953 (2026). https://doi.org/10.1038/s41598-026-42786-4
الكلمات المفتاحية: تحليل المشاعر بالتغرينية, معالجة اللغات منخفضة الموارد, نقل التعلم عبر اللغات, نماذج اللغة الكبيرة, تحسين المعلمات بكفاءة