Clear Sky Science · nl
TigCLaF: een cross-linguale framework voor grote taalmodellen voor sentimentbewuste tekstclassificatie in het laagresources Tigrigna
Waarom dit belangrijk is buiten de computerwetenschap
Dagelijks delen Tigrigna-sprekers hun hoop, angsten en meningen op sociale media en nieuwswebsites. Toch kunnen de meeste moderne kunstmatige-intelligentiesystemen deze berichten niet goed lezen, omdat de taal veel minder digitale bronnen heeft dan Engels of Chinees. Dit artikel presenteert TigCLaF, een nieuw kader dat grote taalmodellen efficiënt leert de emotionele toon van Tigrigna-tekst te begrijpen, met beperkt data-aanbod en bescheiden rekenkracht. Het werk biedt een sjabloon om krachtige taaltechnologie naar tal van andere ondervertegenwoordigde talen te brengen.
Schaarse data ombuigen tot een kracht
De kernuitdaging die de auteurs aanpakken is sentimentbewuste tekstclassificatie in een laagresource-omgeving. Dat betekent automatisch bepalen of een tekst een positieve, negatieve of neutrale emotie uitdrukt, terwijl subtiele emotionele aanwijzingen behouden blijven. Voor Tigrigna is dit lastig: er zijn weinig gelabelde datasets, het Ge’ez-schrift kent eigen interpunctie- en spatiëringsregels, en sentiment wordt vaak via idioom en culturele verwijzingen uitgedrukt. Conventionele modellen veronderstellen enorme trainingssets en goed ontwikkelde hulpmiddelen, en falen daarom op dit materiaal. TigCLaF reageert door kennis te hergebruiken uit meertalige modellen die op datarijke talen zijn getraind en deze zorgvuldig aan Tigrigna aan te passen zonder alles vanaf nul te herscholen.
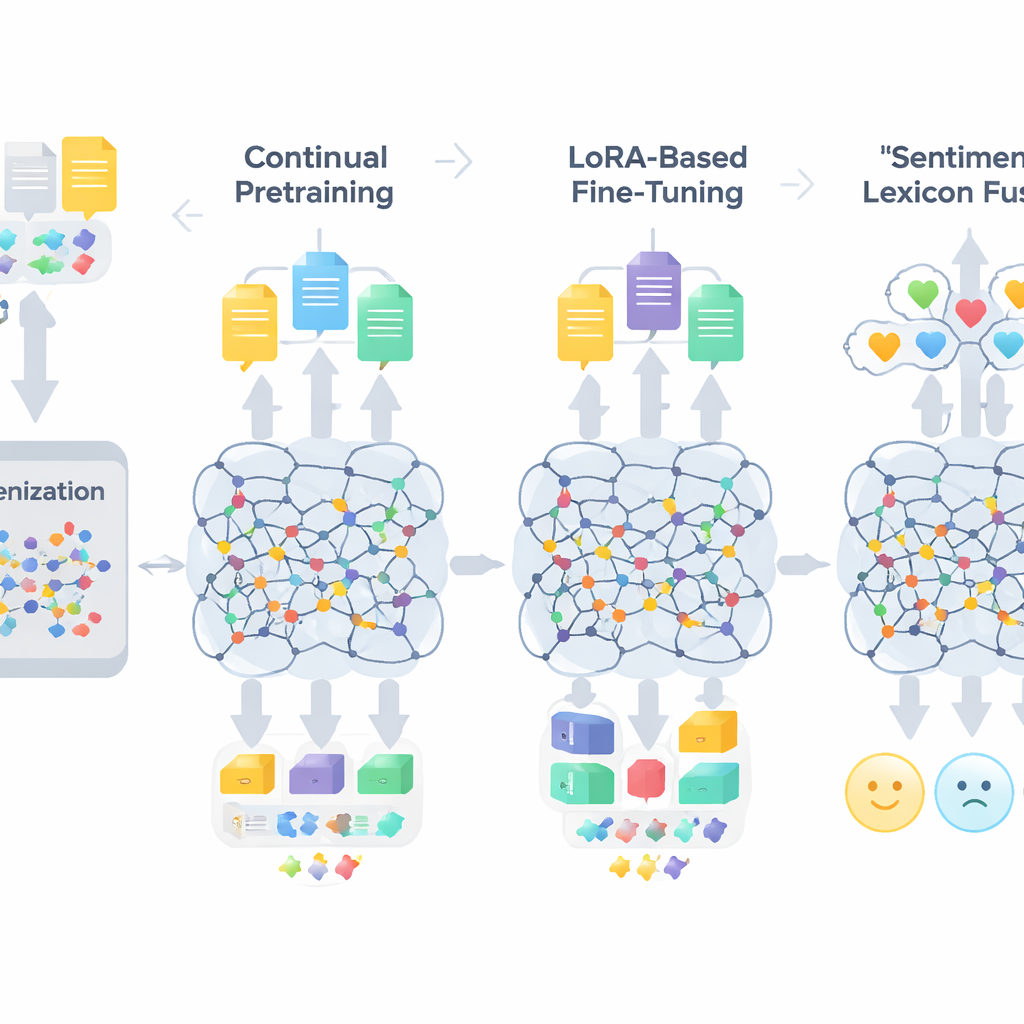
Een recept in drie stappen om grote modellen aan te passen
De workflow van TigCLaF bestaat uit drie nauw verbonden fasen. Ten eerste breiden de auteurs de tokenizer van het model uit—het onderdeel dat tekst in eenheden knipt—door duizenden vaak gebruikte Tigrigna-subwoorden toe te voegen. Dit vermindert onnatuurlijke splitsing van Ge’ez-woorden en verbetert hoe de taal in het netwerk wordt gerepresenteerd. Ten tweede zetten ze de pretraining van het meertalige model voort op een mengsel dat voornamelijk Tigrigna bevat, met wat Engels en Amhaars. Tijdens deze fase vult het systeem zowel gemaskeerde woorden in als leert het overeenkomende zinnen tussen talen dichter bij elkaar te brengen in de interne representatieruimte, wat de cross-linguale uitlijning versterkt. Ten derde, in plaats van alle modelgewichten bij te werken, passen ze een techniek genaamd LoRA toe, die kleine adaptermodules toevoegt aan aandacht- en feedforward-lagen. Alleen deze lichtgewicht componenten worden getraind op de Tigrigna-sentimentdataset van 30.000 voorbeelden, wat het geheugen- en rekengerei drastisch vermindert.
Het model expliciet over gevoelens leren
Buiten algemene taaladaptatie injecteert het kader expliciete kennis over emoties. De auteurs bouwen een compacte Tigrigna-sentimentlexicon van ongeveer 3.200 items door een handgemaakte woordlijst te combineren met projecties uit Engelse en Amhaarse bronnen. Elk item draagt een polariteitsscore die aangeeft hoe positief of negatief het doorgaans is. Tijdens training mappt het systeem tokens naar deze polariteitsaanwijzingen, gaat het om met negatie en intensiverende elementen, en fuseert het vervolgens deze kenmerken met de contextuele embeddings van het model. Een gemoduleerd mechanisme leert hoeveel gewicht lexicale sentimentaanwijzingen krijgen ten opzichte van de omliggende context op elke positie, wat helpt bij lastige gevallen zoals sarcasme, idioom en morfologisch complexe woorden.
Hoe goed het in de praktijk werkt
Om TigCLaF te testen, stellen de auteurs een nieuwe Tigrigna-sentimentcorpus samen uit sociale media en nieuwsbronnen tussen 2023 en 2025, reinigen de data zorgvuldig en laten moedertaalsprekers elk bericht labelen. Ze vergelijken hun kader met sterke meertalige baselines, waaronder mBERT, XLM-RoBERTa, AfriBERTa en LLaMA-modellen die ofwel met in-context prompting worden gebruikt ofwel met hun eigen parameter-efficiënte tuning. TigCLaF behaalt de beste algehele prestaties, met een stijging van de macro F1-scores tot ongeveer zeven procentpunten ten opzichte van de beste transformer-baselines, terwijl het slechts zo weinig als ongeveer zes procent van de parameters bijwerkt. Ablatiestudies tonen aan dat elk component bijdraagt: voortdurende pretraining levert de grootste winst, tokenizer-aanpassing en cross-linguale uitlijning verbeteren de robuustheid verder, en de fusie met het sentimentlexicon verbetert consequent de omgang met genuanceerde emotionele inhoud. Het framework generaliseert ook goed naar Amhaars en Engels in zero-shot en few-shot instellingen en degradeert geleidelijk wanneer slechts een fractie van de Tigrigna-trainingsdata beschikbaar is.
Van laboratoriumexperiment naar impact in de echte wereld
Buiten ruwe cijfers onderzoekt het artikel waar het model nog steeds moeite mee heeft—zoals veel code-switching, sarcasme en domeinverschuivingen tussen nieuws en informele gesprekken—en betoogt dat betere normalisatie, modellering van figuratieve taal en domeinadaptatie fouten verder kunnen verminderen. Cruciaal is dat TigCLaF efficiënt draait op gangbare hardware dankzij LoRA en kwantisatie, waardoor het praktisch inzetbaar is voor instellingen en gemeenschappen in Tigrigna-sprekende regio’s. De auteurs concluderen dat hun kader zowel een werkend sentimentanalysesysteem voor Tigrigna is als een blauwdruk om moderne taaltechnologieën naar veel andere laagresource Afrikaanse talen uit te breiden, en zo bij te dragen aan het voorkomen dat deze talen achterblijven in het AI-tijdperk.
Bronvermelding: Gebremeskel, H.G., Feng, C., Abera, A.M. et al. TigCLaF: a cross-lingual large language model framework for sentiment-aware text classification in low-resource tigrigna. Sci Rep 16, 12953 (2026). https://doi.org/10.1038/s41598-026-42786-4
Trefwoorden: Tigrigna sentimentanalyse, NLP voor laagresources talen, cross-linguale transfer learning, grote taalmodellen, parameter-efficiënte fine-tuning