Clear Sky Science · en
TigCLaF: a cross-lingual large language model framework for sentiment-aware text classification in low-resource tigrigna
Why this matters beyond computer science
Every day, people who speak Tigrigna share their hopes, fears, and opinions on social media and news sites. Yet most modern artificial intelligence systems cannot properly read these messages, because the language has far fewer digital resources than English or Chinese. This article presents TigCLaF, a new framework that teaches large language models to understand the emotional tone of Tigrigna text efficiently, using limited data and modest computing power. The work offers a template for bringing powerful language technology to many other underrepresented languages.
Turning scarce data into a strength
The core challenge the authors tackle is sentiment-aware text classification in a low-resource setting. This means automatically telling whether a piece of text expresses a positive, negative, or neutral feeling while preserving subtle emotional cues. For Tigrigna, this is difficult: there are few labeled datasets, the Ge’ez script has its own punctuation and spacing rules, and sentiment is often expressed through idioms and cultural references. Conventional models assume huge training sets and well-developed tools, so they falter on such material. TigCLaF responds by reusing knowledge from multilingual models trained on data-rich languages and carefully adapting it to Tigrigna without retraining everything from scratch.
A three-step recipe for adapting big models
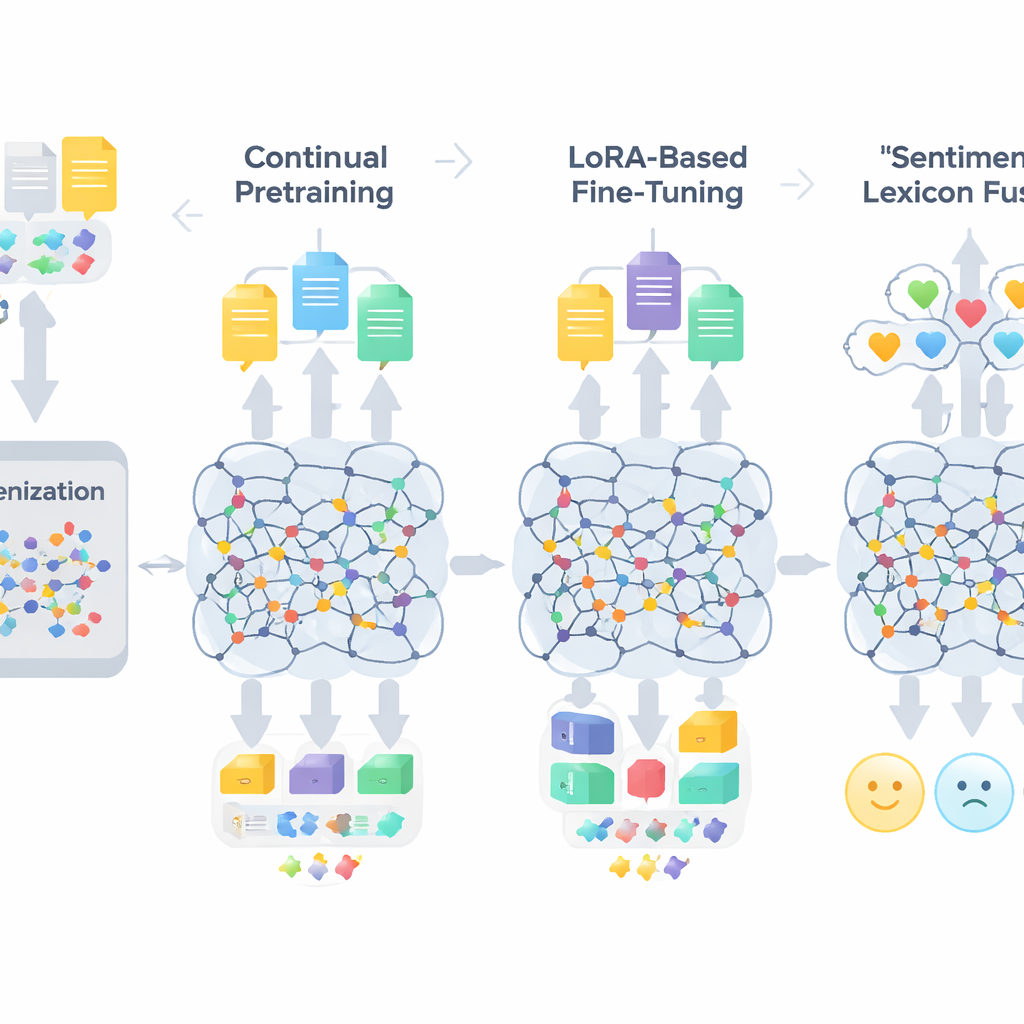
TigCLaF’s workflow consists of three tightly connected stages. First, the authors extend the model’s tokenizer—the part that breaks text into units—by adding thousands of frequently used Tigrigna subwords. This reduces awkward splitting of Ge’ez-script words and improves how the language is represented inside the network. Second, they continue pretraining the multilingual model on a mixture of mostly Tigrigna, with some English and Amharic. During this stage, the system both fills in masked words and learns to bring matching sentences across languages closer together in its internal space, strengthening cross-lingual alignment. Third, instead of updating all model weights, they apply a technique called LoRA, which adds small adapter modules to attention and feed-forward layers. Only these lightweight pieces are trained on the 30,000-instance Tigrigna sentiment dataset, dramatically cutting memory and computation needs.
Teaching the model about feelings explicitly
Beyond general language adaptation, the framework injects explicit knowledge about emotions. The authors build a compact Tigrigna sentiment lexicon of about 3,200 entries by combining a hand-crafted word list with projections from English and Amharic resources. Each entry carries a polarity score indicating how positive or negative it tends to be. During training, the system maps tokens to these polarity hints, handles negation and intensifiers, and then fuses these features with the model’s contextual embeddings. A gated mechanism learns how much weight to give lexical sentiment cues versus surrounding context at each position, which helps in tricky cases like sarcasm, idioms, and morphologically complex words.
How well it works in practice
To test TigCLaF, the authors curate a new Tigrigna sentiment corpus from social media and news outlets between 2023 and 2025, carefully cleaning the data and having native speakers label each post. They compare their framework against strong multilingual baselines, including mBERT, XLM-RoBERTa, AfriBERTa, and LLaMA models used either with in-context prompting or with their own parameter-efficient tuning. TigCLaF achieves the best overall performance, raising macro F1 scores by up to about seven percentage points over the best transformer baselines, while updating as little as roughly six percent of the parameters. Ablation studies show that each component contributes: continual pretraining yields the largest boost, tokenizer adaptation and cross-lingual alignment further enhance robustness, and sentiment-lexicon fusion consistently improves handling of nuanced emotional content. The framework also transfers well to Amharic and English in zero-shot and few-shot settings and degrades gracefully when only a fraction of the Tigrigna training data is available.
From lab experiment to real-world impact
Beyond raw numbers, the paper explores where the model still struggles—such as heavy code-switching, sarcasm, and domain shifts between news and informal conversations—and argues that better normalization, figurative language modeling, and domain adaptation could further reduce errors. Crucially, TigCLaF runs efficiently on commodity hardware thanks to LoRA and quantization, making it practical for institutions and communities in Tigrigna-speaking regions. The authors conclude that their framework is both a working sentiment analysis system for Tigrigna and a blueprint for extending modern language technologies to many other low-resource African languages, helping ensure they are not left behind in the AI era.
Citation: Gebremeskel, H.G., Feng, C., Abera, A.M. et al. TigCLaF: a cross-lingual large language model framework for sentiment-aware text classification in low-resource tigrigna. Sci Rep 16, 12953 (2026). https://doi.org/10.1038/s41598-026-42786-4
Keywords: Tigrigna sentiment analysis, low-resource language NLP, cross-lingual transfer learning, large language models, parameter-efficient fine-tuning