Clear Sky Science · de
TigCLaF: ein cross-linguales Large-Model-Framework für stimmungsbewusste Textklassifikation in ressourcenarmer Tigrigna
Warum das über die Informatik hinaus wichtig ist
Jeden Tag teilen Tigrigna-Sprecherinnen und -Sprecher ihre Hoffnungen, Ängste und Meinungen in sozialen Medien und Nachrichtenseiten. Doch die meisten modernen KI-Systeme können diese Beiträge nicht zuverlässig lesen, weil die Sprache deutlich weniger digitale Ressourcen hat als Englisch oder Chinesisch. Dieser Artikel stellt TigCLaF vor, ein neues Framework, das große Sprachmodelle effizient darin schult, den emotionalen Ton von Tigrigna-Texten zu erfassen — mit begrenzten Daten und moderatem Rechenaufwand. Die Arbeit bietet eine Blaupause, um leistungsfähige Sprachtechnologie vielen anderen unterrepräsentierten Sprachen zugänglich zu machen.
Knappheit an Daten als Stärke nutzen
Die Kernherausforderung, die die Autorinnen und Autoren angehen, ist stimmungsbewusste Textklassifikation in einem ressourcenarmen Setting. Das heißt, automatisch zu bestimmen, ob ein Text positiv, negativ oder neutral gefärbt ist, dabei aber feine emotionale Nuancen zu bewahren. Für Tigrigna ist das schwierig: Es gibt wenige annotierte Datensätze, die Ge’ez-Schrift bringt eigene Interpunktions- und Wortabstandsregeln mit, und Stimmung wird oft durch Idiome und kulturelle Verweise ausgedrückt. Konventionelle Modelle setzen große Trainingsmengen und gut entwickelte Werkzeuge voraus und scheitern deshalb an diesem Material. TigCLaF reagiert, indem es Wissen aus multilingualen Modellen, die an datenträchtigen Sprachen trainiert wurden, wiederverwendet und sorgfältig an Tigrigna anpasst, ohne alles von Grund auf neu zu trainieren.
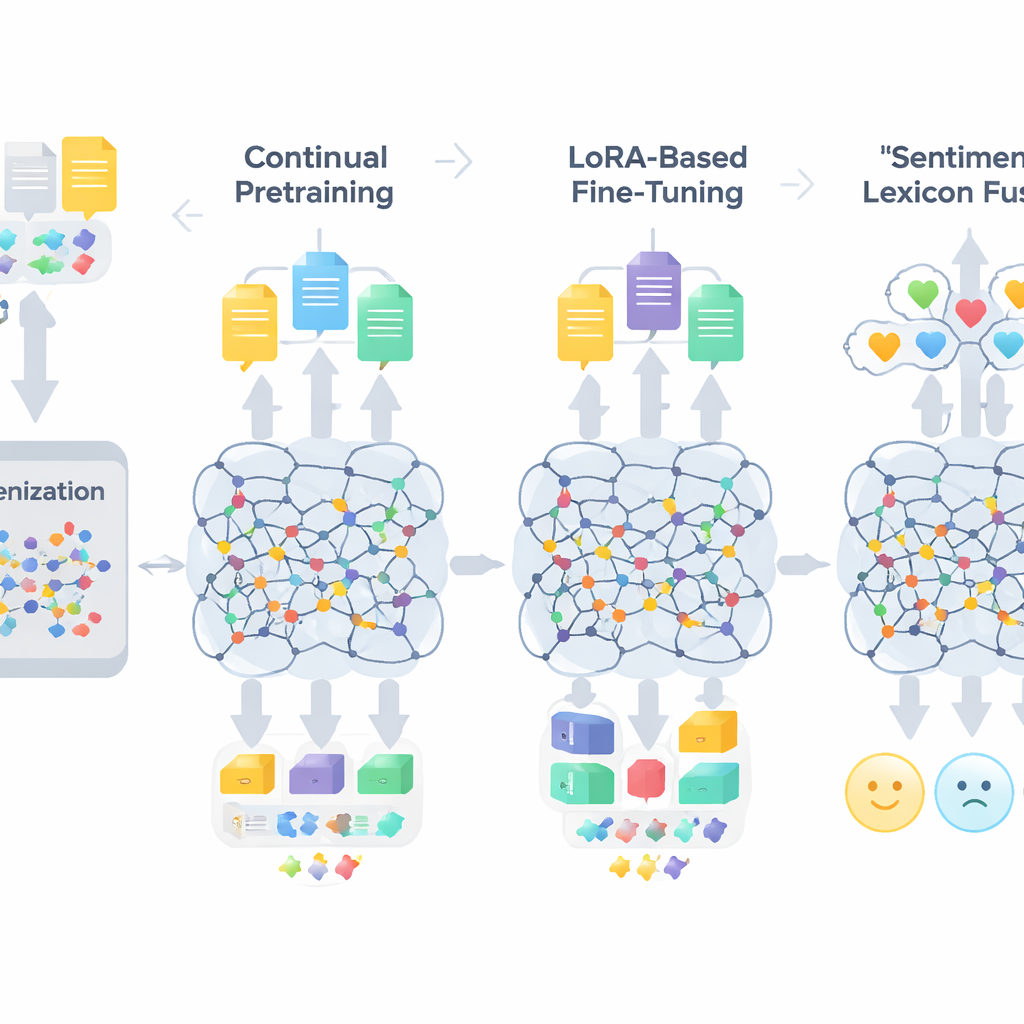
Ein Dreischritte-Rezept zur Anpassung großer Modelle
Der Workflow von TigCLaF besteht aus drei eng verknüpften Phasen. Zuerst erweitern die Autoren den Tokenizer — den Teil, der Text in Einheiten zerlegt — durch Hinzufügen tausender häufig verwendeter Tigrigna-Subwörter. Das reduziert unglückliche Zerlegungen von Ge’ez-Wörtern und verbessert die Repräsentation der Sprache im Netz. Zweitens führen sie ein weiteres Pretraining des multilingualen Modells auf einer Mischung durch, die überwiegend Tigrigna, aber auch etwas Englisch und Amharisch enthält. In dieser Phase füllt das System maskierte Wörter auf und lernt, passende Sätze über Sprachen hinweg im internen Raum näher zusammenzubringen, wodurch die cross-linguale Ausrichtung gestärkt wird. Drittens aktualisieren sie nicht alle Modellgewichte, sondern wenden eine Technik namens LoRA an, die kleine Adaptermodule in Attention- und Feedforward-Schichten einfügt. Nur diese leichtgewichtigen Teile werden auf dem 30.000-Instanzen starken Tigrigna-Stimmungsdatensatz trainiert, was Speicher- und Rechenbedarf drastisch senkt.
Dem Modell Gefühle explizit beibringen
Über die allgemeine Sprachadaptation hinaus injiziert das Framework explizites Wissen über Emotionen. Die Autoren erstellen ein kompaktes Tigrigna-Stimmungslexikon mit etwa 3.200 Einträgen, indem sie eine handverfasste Wortliste mit Übertragungen aus englischen und amharischen Ressourcen kombinieren. Jeder Eintrag trägt einen Polaritätswert, der angibt, wie positiv oder negativ das Wort typischerweise ist. Während des Trainings ordnet das System Tokens diesen Polaritäts-Hinweisen zu, behandelt Negation und Intensivierer und verschmilzt dann diese Merkmale mit den kontextuellen Einbettungen des Modells. Ein gated Mechanismus lernt, wie viel Gewicht lexikalische Stimmungshinweise gegenüber dem umgebenden Kontext an jeder Position erhalten sollen, was bei schwierigen Fällen wie Sarkasmus, Idiomen und morphologisch komplexen Wörtern hilft.
Wie gut es in der Praxis funktioniert
Um TigCLaF zu testen, erstellen die Autoren ein neues Tigrigna-Stimmungs-Korpus aus sozialen Medien und Nachrichtenquellen der Jahre 2023 bis 2025, reinigen die Daten sorgfältig und lassen muttersprachliche Annotatorinnen und Annotatoren jeden Beitrag labeln. Sie vergleichen ihr Framework mit starken multilingualen Baselines, darunter mBERT, XLM-RoBERTa, AfriBERTa und LLaMA-Modelle, die entweder mit In-Context-Prompting oder mit eigenen parameter-effizienten Anpassungen verwendet werden. TigCLaF erzielt die beste Gesamtergebnis, erhöht die Macro-F1-Werte um bis zu etwa sieben Prozentpunkte gegenüber den besten Transformer-Baselines und aktualisiert dabei nur rund sechs Prozent der Parameter. Ablationsstudien zeigen, dass jede Komponente beiträgt: kontinuierliches Pretraining liefert den größten Schub, Tokenizer-Anpassung und cross-linguale Ausrichtung erhöhen die Robustheit weiter, und die Fusion mit dem Stimmungslexikon verbessert konsequent den Umgang mit nuanciertem emotionalen Gehalt. Das Framework überträgt sich außerdem gut auf Amharisch und Englisch in Zero-Shot- und Few-Shot-Szenarien und verschlechtert sich nur moderat, wenn nur ein Bruchteil der Tigrigna-Trainingsdaten verfügbar ist.
Vom Laborexperiment zur realen Wirkung
Über die reinen Zahlen hinaus untersucht das Papier, wo das Modell noch Probleme hat — etwa bei starkem Code-Switching, Sarkasmus und Domänenverschiebungen zwischen Nachrichten und informellen Gesprächen — und argumentiert, dass bessere Normalisierung, Modellierung bildlicher Sprache und Domänenanpassung Fehler weiter reduzieren könnten. Entscheidend ist, dass TigCLaF dank LoRA und Quantisierung effizient auf handelsüblicher Hardware läuft, was es für Institutionen und Gemeinschaften in tigrignasprachigen Regionen praktikabel macht. Die Autoren schließen, dass ihr Framework sowohl ein funktionierendes Stimmungsanalyse-System für Tigrigna als auch eine Blaupause zum Ausbau moderner Sprachtechnologien für viele andere ressourcenarme afrikanische Sprachen darstellt, wodurch sichergestellt werden kann, dass diese nicht in der KI-Ära zurückgelassen werden.
Zitation: Gebremeskel, H.G., Feng, C., Abera, A.M. et al. TigCLaF: a cross-lingual large language model framework for sentiment-aware text classification in low-resource tigrigna. Sci Rep 16, 12953 (2026). https://doi.org/10.1038/s41598-026-42786-4
Schlüsselwörter: Tigrigna Stimmungsanalyse, NLP für ressourcenarme Sprachen, cross-linguales Transferlernen, große Sprachmodelle, parameter-effizientes Fine-Tuning